1.HBase写入流程
HBase提供create的接口,不直接提供update和delete接口。HBase中对数据的更新和删除都是通过create一条新纪录来实现。
HBase写入流程可分为三个过程:客户端处理、Region写入、MemStore flush

1.1.客户端处理
客户端将用户写入请求进行预处理,并根据集群元数据定位写入数据所在的RegionServer,将请求发送给对应的RegionServer。
客户端写入请求的核心流程可分为三步:
(1)用户提交put请求后,hbase client将数据写入本地缓冲区。符合一定条件后,将通过AsyncProcess异步批量提交。用户可以设置autoflush=false,这样put请求首先会放到缓冲区,缓冲区大小超过一定阈值后,使用批量提交请求到hbase服务端,可以极大地提升写入吞吐量。但是因为没有保护机制,如果客户端崩溃,会导致部分已经提交的数据丢失。
(2)提交数据到hbase服务端之前,hbase会在元数据表hbase:meta中根据rowkey找到归属的RegionServer,这个定位过程通过HConnection.locateRegion方法来完成。如果是批量请求,还会将这些rowkey根据HRegionLocation分组,不同分组的请求意味着发送到不同的RegionServer,每个分组对应一个RPC请求。
(3)HBase为每个HRegionLocation构造一个RPC请求MultiServerCallable,并通过rpcCallerFactory.newCaller执行调用。将请求经过Protobuf序列化后发送到RegionServer。
Client、Zookeeper、RegionServer之间的交互如下图所示:
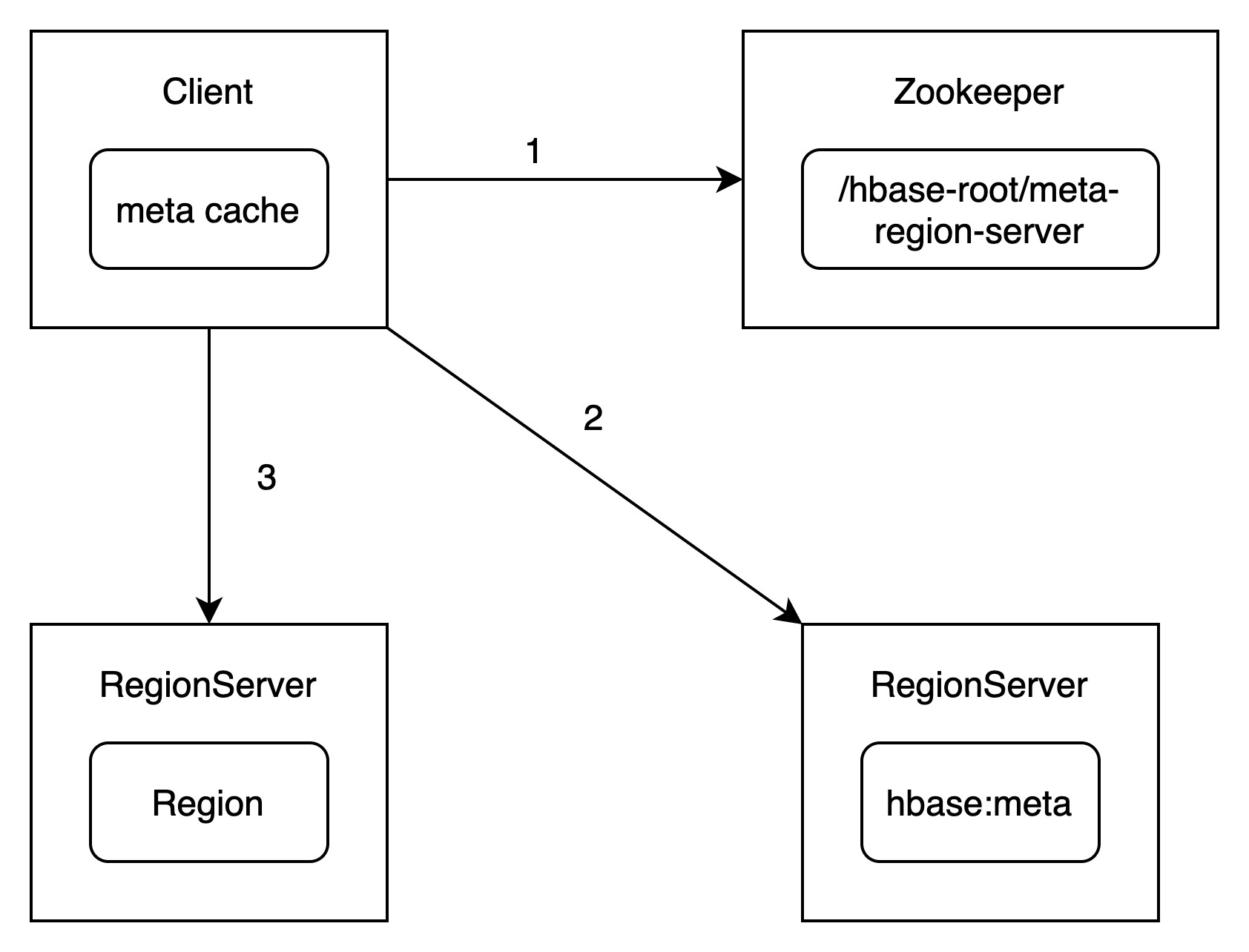
整个交互过程包含以下方式:
(1)客户端根据写入的表以及rowkey在元数据缓存中查找,如果能找到对应的RegionServer和Region,则直接向该RegionServer发送写入请求。
(2)如果缓存没有命中rowkey,则在zookeeper上的/meta-region-server节点查找Hbase元数据表所在的RegionServer。向该RegionServer发送查询请求,在元数据表中查找rowkey所在的RegionServer和Region。客户端接收到结果后,将结果缓存到本地。
(3)客户端根据rowkey相关元数据信息将写入请求发送给目标RegionServer,RegionServer接收到请求后会解析出具体的Region信息,查到对应的Region对象,并将数据写入目标Region的MemStore中。
1.2.Region写入
RegionServer接收到写入请求后将数据解析出来,首先写入WAL,再写入对应Region列簇的MemStore。
1.3.MemStore flush
当Region中MemStore容量超过一定的阈值,系统会异步执行flush操作,将内存中的数据写入HFile。