StreamWriteFunction
Flink通过StreamWriteFunction负责将数据流写入Hudi表。
processElement
processElement方法将数据缓存到buckets中。bucket的按照一定规则定期flush数据。
@Override
public void processElement(HoodieFlinkInternalRow record,
ProcessFunction<HoodieFlinkInternalRow, RowData>.Context ctx,
Collector<RowData> out) throws Exception {
bufferRecord(record);
}DataBucket为数据写入缓存。缓存了需要写入某个partition path和fileID之下的一批record。
Bucket中的数据不是无限累加的。满足下面2个条件之一会触发flush bucket:
(1)如果某个DataBucket数据累积够write.batch.size(默认256MB)会flush这个bucket。
(2)如果缓存的数据总大小超过write.task.max.size(默认1GB),会flush缓存数据最多的bucket。
bufferRecord
bufferRecord方法将数据放入bucket缓冲池。
protected void bufferRecord(HoodieFlinkInternalRow record) throws IOException {
writeMetrics.markRecordIn();
// set operation type into rowkind of row.
record.getRowData().setRowKind(
RowKind.fromByteValue(HoodieOperation.fromName(record.getOperationType()).getValue()));
// 根据HoodieRecord的partitionPath和fileId构建bucketID
final String bucketID = getBucketID(record.getPartitionPath(), record.getFileId());
// 1. 尝试将数据放入内存缓冲池
boolean success = doBufferRecord(bucketID, record);
if (!success) {
// 2. 如果缓冲池满了,将bucket中的数据执行flush操作
RowDataBucket bucketToFlush = this.buckets.values().stream()
.max(Comparator.comparingLong(RowDataBucket::getBufferSize))
.orElseThrow(NoSuchElementException::new);
if (flushBucket(bucketToFlush)) {
// 2.1 将bucket中所有的缓冲数据执行flush操作
this.tracer.countDown(bucketToFlush.getBufferSize());
disposeBucket(bucketToFlush);
} else {
LOG.warn("The buffer size hits the threshold {}, but still flush the max size data bucket failed!", this.tracer.maxBufferSize);
}
// 2.2 再次尝试将数据放入内存缓冲池
success = doBufferRecord(bucketID, record);
if (!success) {
// 如果此时还放入不了缓冲池,则说明缓冲池内存太小,直接抛异常
throw new RuntimeException("Buffer is too small to hold a single record.");
}
}
RowDataBucket bucket = this.buckets.get(bucketID);
this.tracer.trace(bucket.getLastRecordSize());
// 3. 如果flush满了,则将bucket中的数据执行flush操作
if (bucket.isFull()) {
if (flushBucket(bucket)) {
this.tracer.countDown(bucket.getBufferSize());
disposeBucket(bucket);
}
}
// 更新缓冲持续相关的监控指标数据
writeMetrics.setWriteBufferedSize(this.tracer.bufferSize);
}flushBucket
flushBucket方法将bucket数据执行flush操作。
private boolean flushBucket(RowDataBucket bucket) {
// 获取上一次成功checkpoint的时间
String instant = instantToWrite(true);
if (instant == null) {
// in case there are empty checkpoints that has no input data
LOG.info("No inflight instant when flushing data, skip.");
return false;
}
ValidationUtils.checkState(!bucket.isEmpty(), "Data bucket to flush has no buffering records");
// 调用org.apache.hudi.sink.StreamWriteFunction.WriteFunction#write执行写入
final List<WriteStatus> writeStatus = writeRecords(instant, bucket);
// 构建元数据写入事件
final WriteMetadataEvent event = WriteMetadataEvent.builder()
.taskID(taskID)
.checkpointId(this.checkpointId)
.instantTime(instant) // the write instant may shift but the event still use the currentInstant.
.writeStatus(writeStatus)
.lastBatch(false)
.endInput(false)
.build();
// 发送这个事件到coordinator
this.eventGateway.sendEventToCoordinator(event);
// 加入写入状态到writeStatuses集合
writeStatuses.addAll(writeStatus);
// 返回flush成功
return true;
}Flink Hudi刷写数据到磁盘的3个时机:
(1)某个bucket数据量达到配置的bucket最大容量(write.batch.size),刷写这个bucket。
(2)所有bucket数据量总和达到了配置值(write.task.max.size),刷写数据量最多的bucket。
(3)Flink checkpoint的时候,刷写所有的缓存数据。
WriteFunction#write
org.apache.hudi.sink.StreamWriteFunction.WriteFunction#write
在启动任务的时候,根据任务配置的write.operation参数(默认是UPSERT)确定不同的WriteFunction。
private void initWriteFunction() {
final String writeOperation = this.config.get(FlinkOptions.OPERATION);
switch (WriteOperationType.fromValue(writeOperation)) {
case INSERT:
this.writeFunction = (records, bucketInfo, instantTime) -> this.writeClient.insert(records, bucketInfo, instantTime);
break;
case UPSERT:
case DELETE: // shares the code path with UPSERT
case DELETE_PREPPED:
this.writeFunction = (records, bucketInfo, instantTime) -> this.writeClient.upsert(records, bucketInfo, instantTime);
break;
case INSERT_OVERWRITE:
this.writeFunction = (records, bucketInfo, instantTime) -> this.writeClient.insertOverwrite(records, bucketInfo, instantTime);
break;
case INSERT_OVERWRITE_TABLE:
this.writeFunction = (records, bucketInfo, instantTime) -> this.writeClient.insertOverwriteTable(records, bucketInfo, instantTime);
break;
default:
throw new RuntimeException("Unsupported write operation : " + writeOperation);
}
}这里的writeClient为HoodieFlinkWriteClient
Hudi表UPSERT
最终通过org.apache.hudi.client.HoodieFlinkWriteClient#upsert方法来实现Hudi表的UPSERT
HoodieFlinkWriteClient#upsert
org.apache.hudi.client.HoodieFlinkWriteClient#upsert
// 初始化AutoCloseableWriteHandle实例
closeableHandle = new AutoCloseableWriteHandle
// 初始化HoodieWriteHandle
writeHandle = HoodieFlinkWriteClient#getOrCreateWriteHandle
// 获取工厂方法类
writeHandleFactory = FlinkWriteHandleFactory.getFactory
// 由工厂方法类创建HoodieWriteHandle实例
writeHandleFactory.create
HoodieFlinkTable.upsert(closeableHandle)
// 对应COW表,调用如下方法
org.apache.hudi.table.HoodieFlinkCopyOnWriteTable#upsert
// 对应MOR表,调用如下方法
org.apache.hudi.table.HoodieFlinkMergeOnReadTable#upsert这个方法将upsert逻辑交给了HoodieFlinkTable去执行。负责具体怎么写入的处理逻辑在closeableHandle.getWriteHandle()中。
下面看看什么条件下使用的具体是哪个writeHandle。
FlinkWriteHandleFactory#getFactory
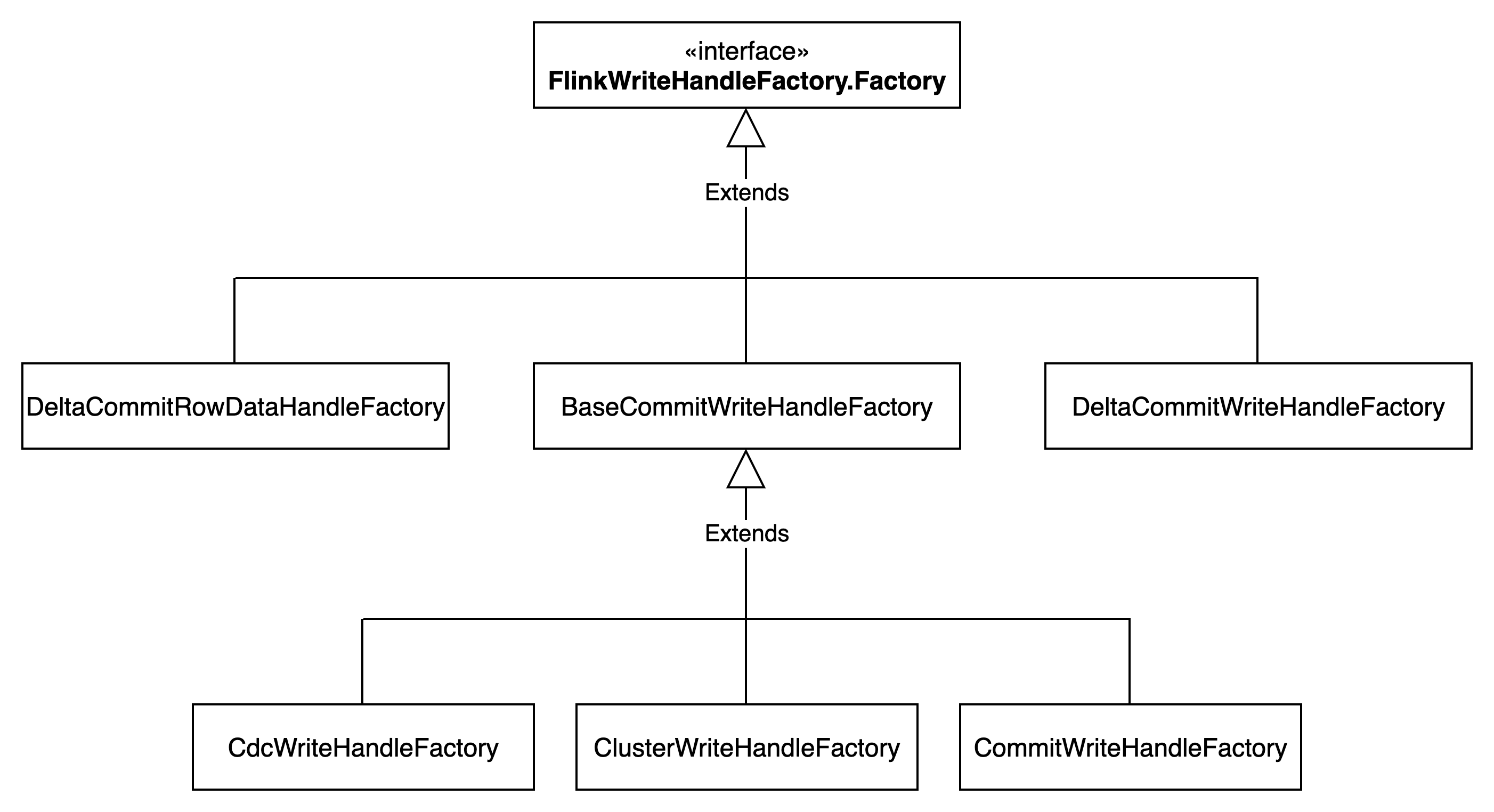
Hudi提供了多种Handle,分别对应不同类型的写入方式。对应的实现方法如FlinkWriteHandleFactory#getFactory源码所示
/**
* Returns the write handle factory with given write config.
*/
public static <T, I, K, O> Factory<T, I, K, O> getFactory(
HoodieTableConfig tableConfig,
HoodieWriteConfig writeConfig,
boolean overwrite) {
if (overwrite) {
return CommitWriteHandleFactory.getInstance();
}
if (writeConfig.allowDuplicateInserts()) {
return ClusterWriteHandleFactory.getInstance();
}
if (tableConfig.getTableType().equals(HoodieTableType.MERGE_ON_READ)) {
return HoodieTableMetadata.isMetadataTable(writeConfig.getBasePath())
? DeltaCommitWriteHandleFactory.getInstance() : DeltaCommitRowDataHandleFactory.getInstance();
} else if (tableConfig.isCDCEnabled()) {
return CdcWriteHandleFactory.getInstance();
} else {
return CommitWriteHandleFactory.getInstance();
}
}各个Factory的继承关系如下图所示