Hudi索引的作用
Apache Hudi索引在数据读和写的过程中都有应用。
(1)读的过程主要是查询引擎利用MetaDataTable使用索引进行Data Skipping以提高查找速度
(2)写的过程主要应用在upsert写上,即利用索引查找该纪录是新增(I)还是更新(U),以提高写入过程中纪录的打标(tag)速度。
Hudi索引的类型
Hudi支持以下类型的索引
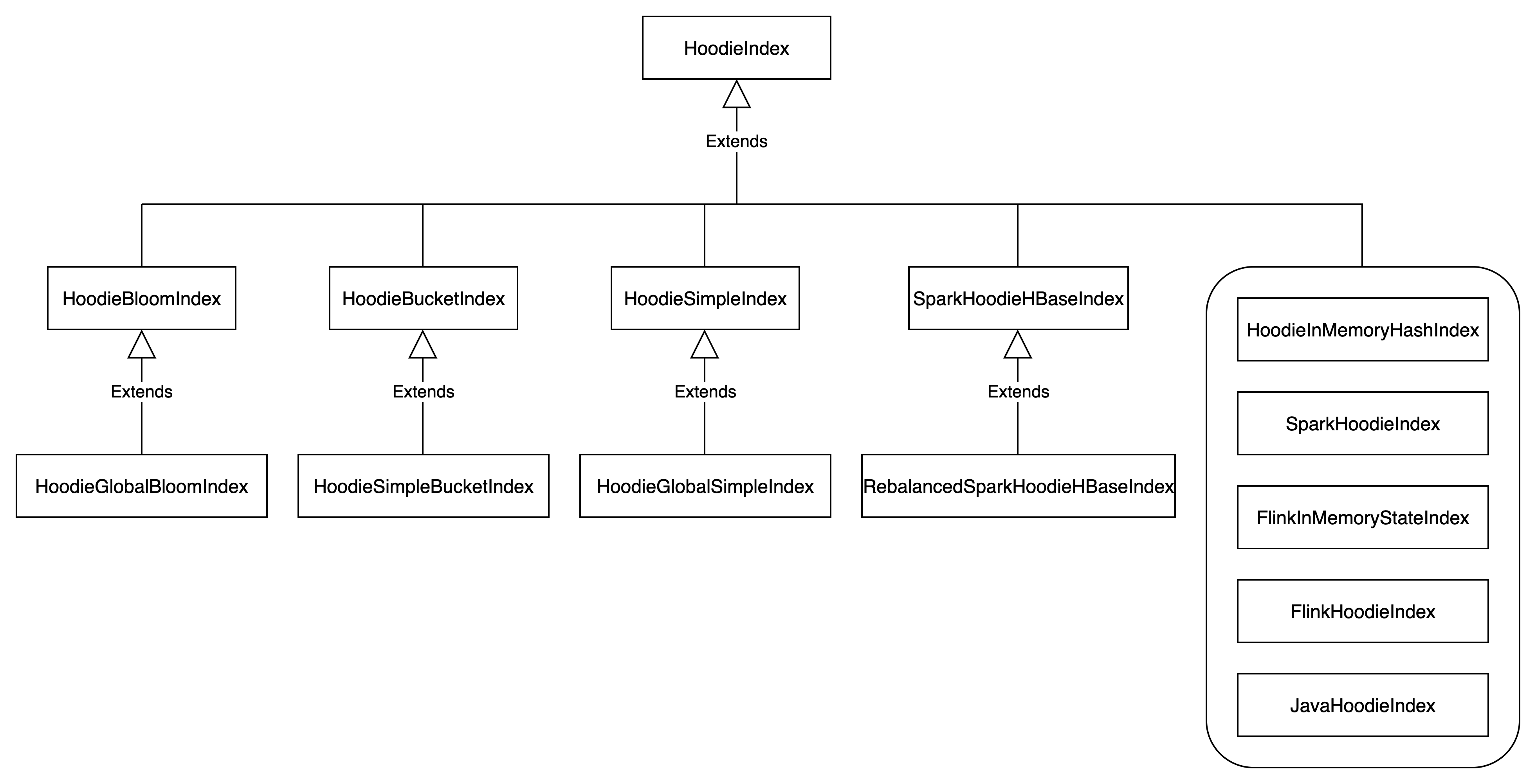
HoodieIndex
HoodieIndex是所有索引类型的基类
核心方法如下:
public abstract class HoodieIndex<I, O> implements Serializable {
/**
* Looks up the index and tags each incoming record with a location of a file that contains
* the row (if it is actually present).
*/
public abstract <R> HoodieData<HoodieRecord<R>> tagLocation(
HoodieData<HoodieRecord<R>> records, HoodieEngineContext context,
HoodieTable hoodieTable) throws HoodieIndexException;
/**
* Extracts the location of written records, and updates the index.
*/
public abstract HoodieData<WriteStatus> updateLocation(
HoodieData<WriteStatus> writeStatuses, HoodieEngineContext context,
HoodieTable hoodieTable) throws HoodieIndexException;
/**
* Rollback the effects of the commit made at instantTime.
*/
public abstract boolean rollbackCommit(String instantTime);
/**
* An index is `global` if {@link HoodieKey} to fileID mapping, does not depend on the `partitionPath`. Such an
* implementation is able to obtain the same mapping, for two hoodie keys with same `recordKey` but different
* `partitionPath`
*
* @return whether the index implementation is global in nature
*/
public abstract boolean isGlobal();
/**
* This is used by storage to determine, if it is safe to send inserts, straight to the log, i.e. having a
* {@link FileSlice}, with no data file.
*
* @return Returns true/false depending on whether the impl has this capability
*/
public abstract boolean canIndexLogFiles();
/**
* An index is "implicit" with respect to storage, if just writing new data to a file slice, updates the index as
* well. This is used by storage, to save memory footprint in certain cases.
*/
public abstract boolean isImplicitWithStorage();
}HoodieBloomIndex
Hudi默认采用的HoodieBloomIndex索引,其依赖布隆过滤器来判断记录存在与否,当记录存在时,会读取实际文件进行二次判断,以便修正布隆过滤器带来的误差。同时还在每个文件元数据中添加了该文件保存的最大和最小的recordKey,借助该值可过滤出无需对比的文件。
HoodieBloomIndex是基于分区记录所在文件,即分区路径+recordKey唯一即可。
HoodieGlobalBloomIndex
HoodieGlobalBloomIndex继承自HoodieBloomIndex,表示全局的索引,即会在所有分区内查找指定的recordKey,而非像 HoodieBloomIndex只在指定的分区内查找。
HoodieGlobalBloomIndex在加载分区下所有最新文件时,其会首先获取所有分区,然后再获取所有分区下的最新文件,而非使用从原始记录中解析出来的分区路径。
HoodieBucketIndex
HoodieSimpleIndex
HoodieInMemoryHashIndex
SparkHoodieHBaseIndex
Hudi内置了HBase外置存储系统索引的实现,用户可直接配置HBase索引,将记录索引信息存入HBase。
RebalancedSparkHoodieHBaseIndex
继承自SparkHoodieHBaseIndex类,通过给key添加随机的前缀来解决hbase region数据倾斜的问题。