为了满足HBase客户端多样化的数据库查询需求,Scan操作必须能设置众多维度的属性,常用的有startRow、endRow、Filter、caching、batch、reversed、maxResultSize、version、timeRange等。
1.Scan的核心流程
如下图所示:
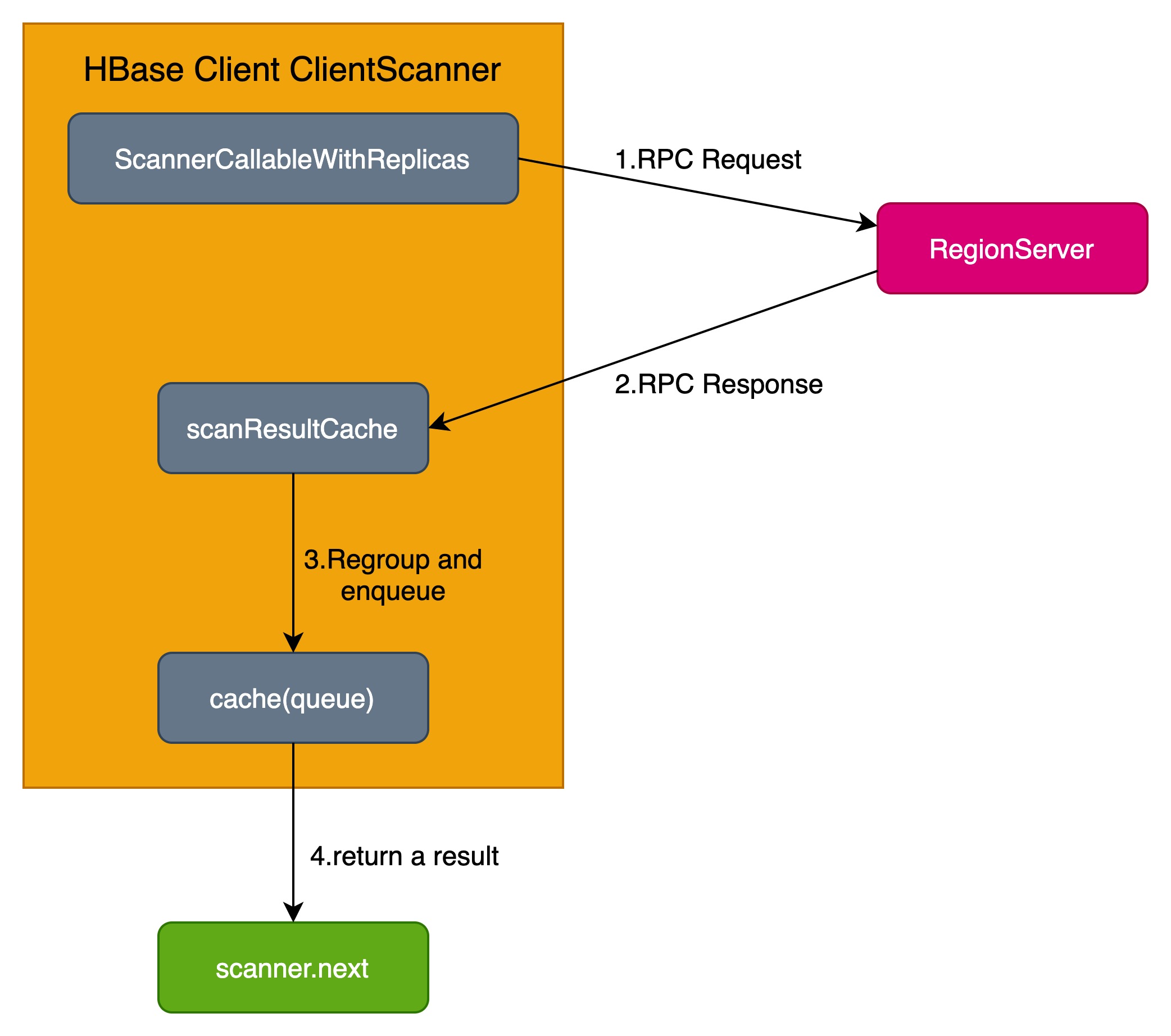
HBase RPC client通过table.getScanner可以拿到一个scanner实例,然后不断执行scanner.next可以得到一个Result。
客户端每次执行scanner.next,都会尝试去cache队列中获取一个result,如果cache队列为空,则会向RegionServer发起一次RPC请求,客户端收到RPC响应后,将result中的多个cell进行重组,然后放到cache队列中。
为什么需要对response的多个cell进行重组?因为RegionServer为了避免被当前RPC请求耗尽资源,实现了多个维度的资源限制,例如timeout、单次请求响应最大字节数等,一旦某个维度达到阈值,就马上把当前拿到的cell返回给客户端。这样客户端拿到的result可能就不是一行完整的数据,因此需要对result进行重组。