Segments过多导致OOM
这是生产环境遇到的一个问题,因为业务上没有针对集群做完备的性能评估,导致kafka broker不断重启。
环境情况
生产环境的kafka有3个节点,服务器配置为128C256G,kafka broker堆内存为32GB,kafka版本为2.8
默认topic的副本数为3,共有400个topic,总分区数为9000,总segment数为50000。
生产消息和消息同步的流量,每个Broker节点的吞吐量为3500条/秒,合计33MB/s。
消费的流量,每个Broker节点的吞吐量为11MB/s。
问题描述
近期新上了业务,之后KafkaBroker会不断挂掉,然后被后台watchdog自动拉起,也就是隔一两天就重启一次,而且集群中的三个节点轮流重启。
查看了服务器监控,cpu、内存、磁盘io都正常,服务器层面没有瓶颈。
查看了kafka broker的gc日志,也是能够正常进行gc,进程挂掉的时间点前没发现full gc。
查看了kafka broker的服务日志,都是直接停止,然后正常启动。没有发现异常日志。
查看了服务器auditd日志,没有发现人为kill的痕迹。
后来,发现了进程oom的日志,因为没有在kakfa broker进程中指定“-XX:ErrorFile=/data/kafka/logs/hs_err_pid%p.log”,所以对应的jvm crash日志会输出到“{user.home}/hs_err_pid%p.log”。
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 16424 bytes for committing reserved memory.
# Possible reasons:
# The system is out of physical RAM or swap space
# Possible solutions:
# Reduce memory load on the system
# Increase physical memory or swap space
# Check if swap backing store is full
# Decrease Java heap size (-Xmx/-Xms)
# Decrease number of Java threads
# Decrease Java thread stack sizes (-Xss)
# Set larger code cache with -XX:ReservedCodeCacheSize=
# This output file may be truncated or incomplete.
#
# Out of Memory Error (os_linux.cpp:3007), pid=676593, tid=516080
#
# JRE version: OpenJDK Runtime Environment OpenJDK (11.0.10) (build 11.0.10)
# Java VM: OpenJDK 64-Bit Server VM OpenJDK (11.0.10, mixed mode, tiered, g1 gc, linux-amd64)
# Core dump will be written. Default location: Core dumps may be processed with "/usr/lib/systemd/systemd-coredump %P %u %g %s %t %c %h" (or dumping to /home/kafka/core.676593)
#问题根因
通过kafka.log.AbstractIndex源码,我们发现:kafka为了避免阻塞式磁盘IO,会将所有分区的每个segment对应的index和timeindex文件通过mmap方式进行读取,对每一个index和timeindex文件保留一个虚拟缓冲区,读写操作也都是通过操作系统的页缓存来实现。
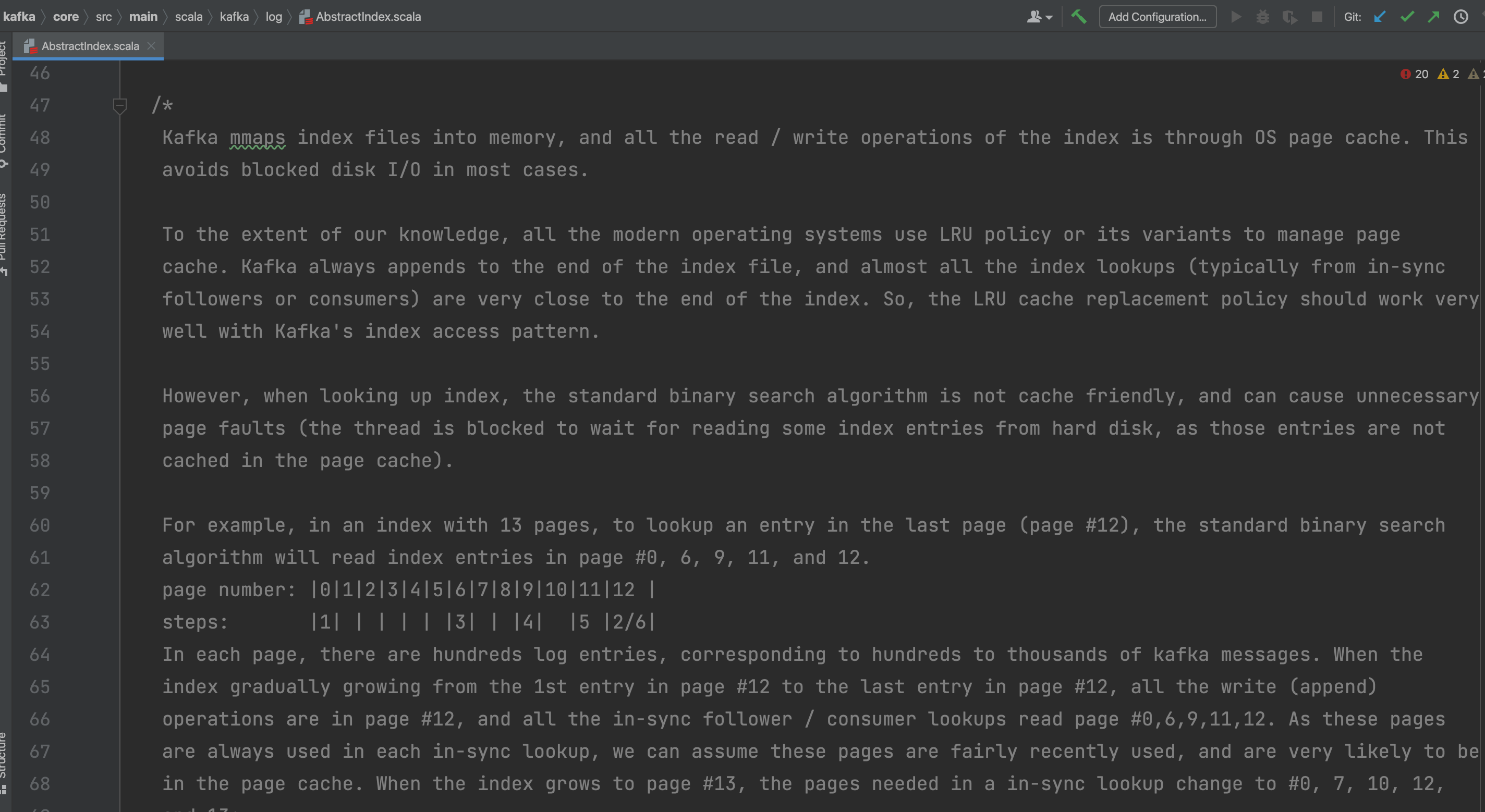
业务扩容后,一个broker节点加载的index文件和timeindex文件过多,超过服务器限制(可查看/proc/sys/vm/max_map_count文件),默认是65530。
最终JVM crash。
重要注意点
有以下注意点:
(1)jvm crash日志输出点
如果遇到jvm crash,进程的err输出流会输出类似以下日志:
#
# A fatal error has been detected by the Java Runtime Environment:
#
# SIGBUS (0x7) at pc=0x0000fffd68e1992c (sent by kill), pid=1758690, tid=1758690
#
# JRE version: OpenJDK Runtime Environment OpenJDK (11.0.10) (build 11.0.10)
# Java VM: OpenJDK 64-Bit Server VM OpenJDK (11.0.10, mixed mode, tiered, compressed oops, g1 gc, linux-aarch64)
# Problematic frame:
# C [libpthread.so.0+0x992c]
#
# Core dump will be written. Default location: Core dumps may be processed with "/usr/lib/systemd/systemd-coredump %P %u %g %s %t %c %h" (or dumping to /home/kafka/core.1758690)
#
# An error report file with more information is saved as:
# /home/kafka/hs_err_pid1758690.log
#如果将err输出流重定向到了/dev/null,则无法看到上述信息,可以直接查看jvm crash日志,对应的日志路径可以通过JVM进程参数“-XX:ErrorFile={log path}”来指定,如果也没有指定此参数,则默认输出到“{user.home}”环境变量指定的目录下。
“{user.home}”的值可通过进程id进行查看,命令如下所示:
{JAVA_HOME}/bin/jinfo {pid} | grep "user.home"一般是进程启动用户的主目录。
Topic过多导致CMAK访问超时
这是测试阶段遇到的问题。
问题描述
对kafka进行容量测试时,创建了上万个topic,在kafkamanager上查看集群summary页面时,报超时。具体错误如下所示:
Yikes! Ask timed out on [ActorSelection[Anchor(akka://kafka-manager-system/), Path(/user/kafka-manager/my_kafka/kafka-state)]] after [2000 ms]. Message of type [kafka.manager.model.ActorModel$KSGetBrokers$] was sent by [Actor[akka://kafka-manager-system/user/kafka-manager/my_kafka#-2334434557]]. A typical reason for `AskTimeoutException` is that the recipient actor didn't send a reply.问题根因
kafkamanager在处理集群概览请求时,会遍历所有的topic,并对每个topic进行元数据请求,如果topic数过多,会导致请求超时。
目前配置的超时时间为2000ms,上万个topic后,总体请求会超时。
解决方案
暂不对请求过程进行优化。
选择简单的方式:即调整超时参数,经测试,以下参数可满足1Wtopic的请求。
cmak.api-timeout-millis = 25000
cmak.cluster-actors-ask-timeout-millis = 12000