1.sed工具概述
sed称为流编辑器(stream editor),是Linux世界中使用最广泛的编辑器之一。流编辑器会在处理数据之前预先提供一组规则来编辑数据。这些规则即可以直接写在命令行中,也可以写在文件中。
1.1.sed处理流程
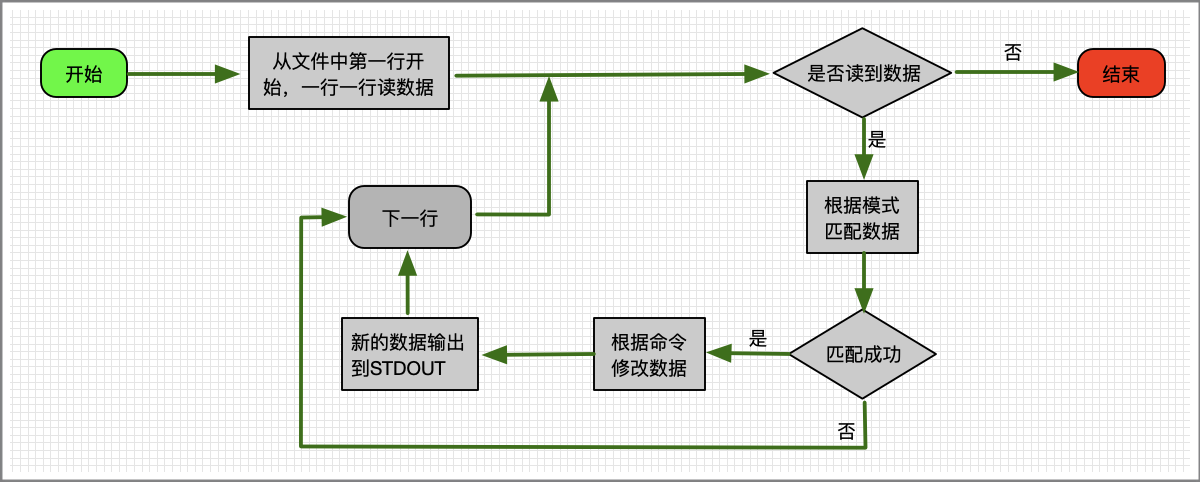
sed编辑器的处理流程如下:
(1)第一步,一次从输入中读取一行数据;
(2)第二步,根据所提供的编辑器命令匹配数据;
(3)第三步,按照命令修改流中的数据;
(4)第四步,将新的数据输出到STDOUT。
流程可用下图表示。
1.2.sed命令行格式
sed基本命令行格式如下:
sed options script file其中,options可选值如下表所示:
2.sed基本功能
sed有六个基本的功能,分别为:替换(s,substitute),删除(d,delete),插入(i,insert),附加(a,append),修改(c,change),转换(y,transform)。下面分别对这六种功能进行解析。
2.1.替换
sed最常用的功能是替换,替换命令格式为:
s/pattern/replacement/flags一般来说,“/”作为分隔符,但是如果“/”在pattern或replacement中被使用,则“/”分隔符可以被其他字符替代。例如:
echo "asdflls" | sed -e 's|asdf|bbbb|'上述案例用“|”来替代分隔符。
flags有四种模式,如下表所示:
很多情况下,我们只需要对指定的行进行操作,sed提供了寻址的功能,可以通过数字(从1开始)来指定某些行,也可以通过文本过滤器来匹配行数据。对于数字指定行,可以在命令行中出现单个数字(特殊地址符为$,表示最后一行)表示某一行。例如:
# 第2行进行替换
sed '2s/dog/cat/' data.txt也可以出现两个数字表示行区间,例如:
# 从第2行到最后一行进行替换
sed '2,$s/dog/cat/' data.txt文本过滤器格式为“/pattern/command”,例如:
# 从/etc/passwd筛选出helloworld的行数据进行替换操作
sed '/helloworld/s/bash/csh/' /etc/passwd选址可作用于单个命令,也可以作用于多个命令,命令行格式如下表所示。
2.2.删除
sed还有一个常用的功能——d命令。sed可以根据上面的选址功能对相应的行数据进行删除。模式匹配删除时需要特别注意,可以用两个模式来删除某个区间内的行,指定的第一个模式会“打开”行删除功能(开始模式),第二个模式会“关闭”行删除功能(停止模式),如果只匹配到了开始模式,而没有匹配到停止模式,则删除功能会一直进行删除。例如下图所示。

还可以使用相对行数的选址模式来对行数据进行删除。比如:
# 查找到dog数据行进行删除,并往后3行也删除
sed '/dog/,+3d' data.txt
# 从第一行开始,每隔一行删除,即删除第2、5、8……行
sed '2~3d' data.txt2.3.插入和附加
插入(insert)命令(i)会在指定行前插入一行新数据。附加(append)命令(a)会在指定行后插入一行新数据。命令行格式如下(new line将会出现在指定的位置):
sed '[address]command\
new line'使用案例如下图所示:
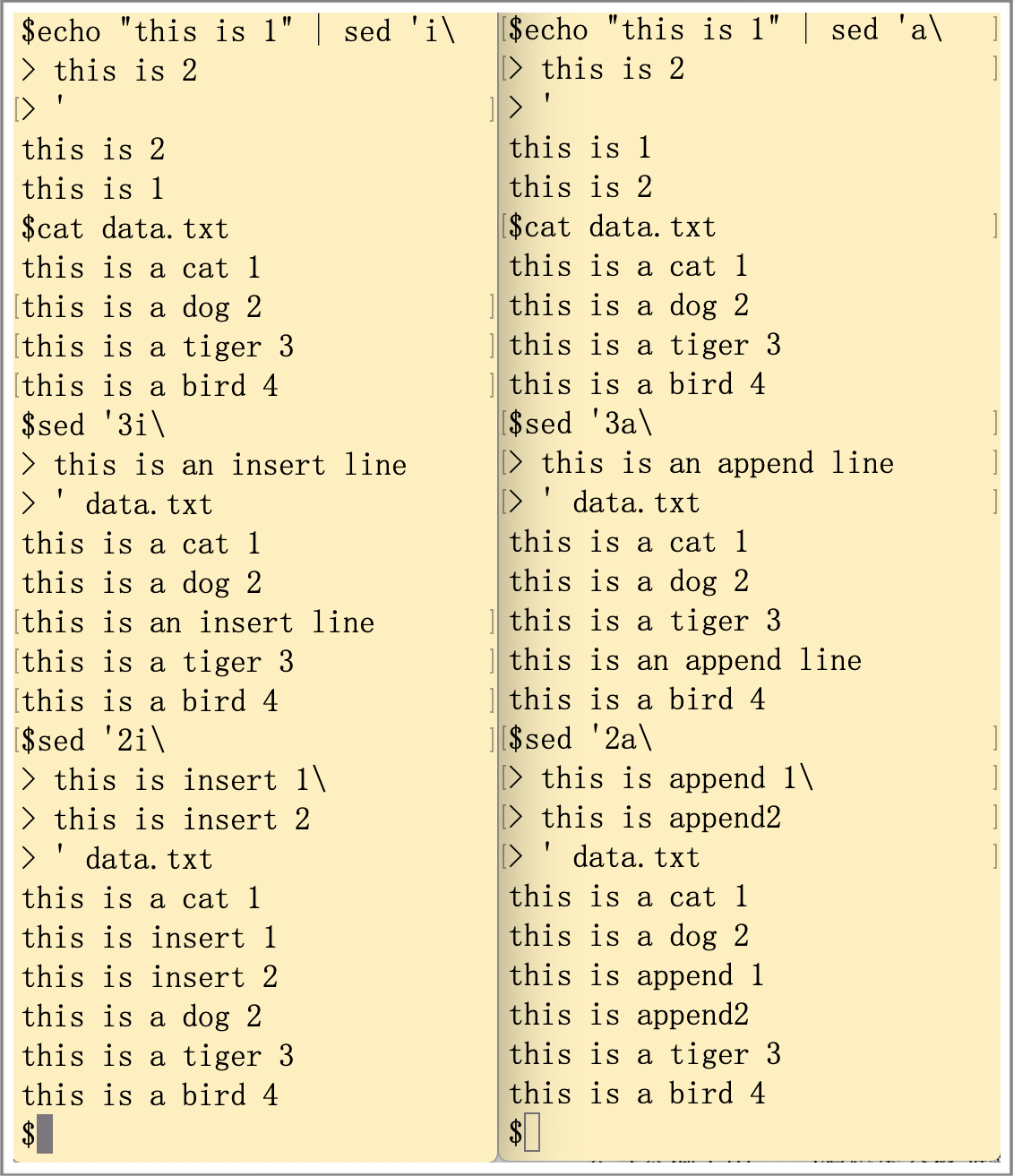
注意,如果要插入和附加多行,在每一行前面加“\”符号。案例如下图所示:
2.4.修改
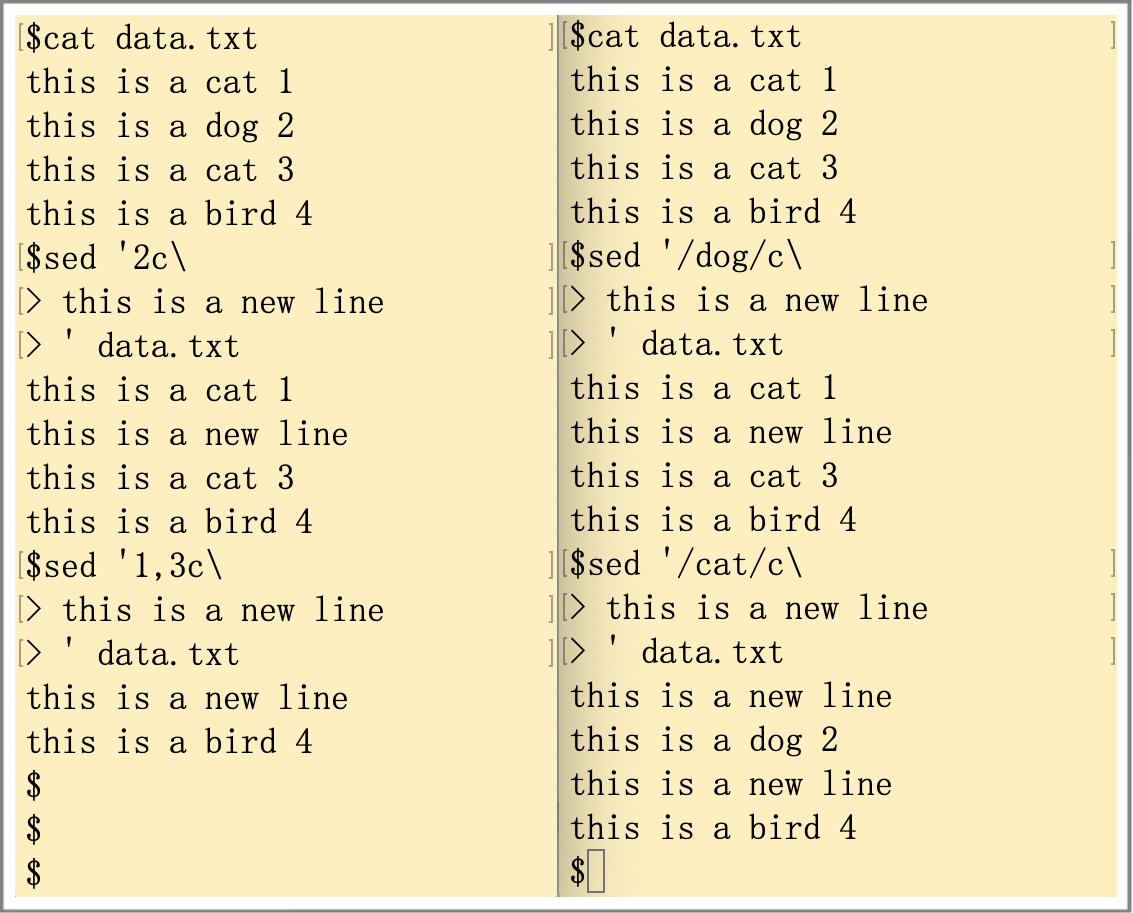
修改(change)命令允许修改数据流中的整行文本内容,即可以修改一行,也可以修改多行。案例如下图所示。图中左边第一个案例表示把第二行修改为“this is a new line”;第二个案例表示把第1到3行修改为一行数据“this is a new line”。图中右边的案例都是以字符匹配来寻址,对符合条件的每一行都会进行修改。
2.5.转换
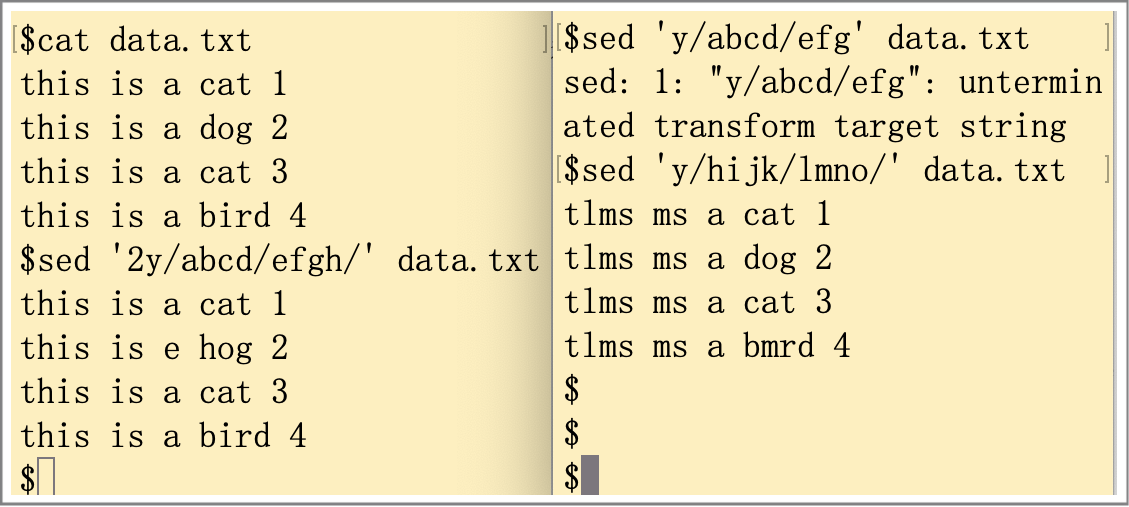
转换(transform)命令(y)是唯一可以处理单个字符的sed编辑器命令,命令格式为:
[address]y/inchars/outchars/转换命令会对inchars和outchars的值进行一对一的映射,如果inchars和outchars的字符长度不一致,sed编辑器会产生一条错误信息。案例如下图所示。
2.6.打印
sed中有三个命令可用于打印数据流中的信息:
(1)p命令打印文本行;
(2)等号(=)命令用了打印行号;
(3)l(小写的L)命令用来列出行。
p命令用来打印sed输出的每一行,如果使用-n选项,则只打印包含匹配文本模式的行。案例如下图所示。

l命令用来打印数据流中的文本和不可打印的ASCII字符,任何不可打印的字符要么在其八进制值前加一个反斜线,要么使用标准C风格的命名法,行尾用美元符表示换行符。
3.使用sed处理文件
我们可以使用sed对文件进行读和写。
其中,w命令用来向文件中写入行数据,命令格式为:
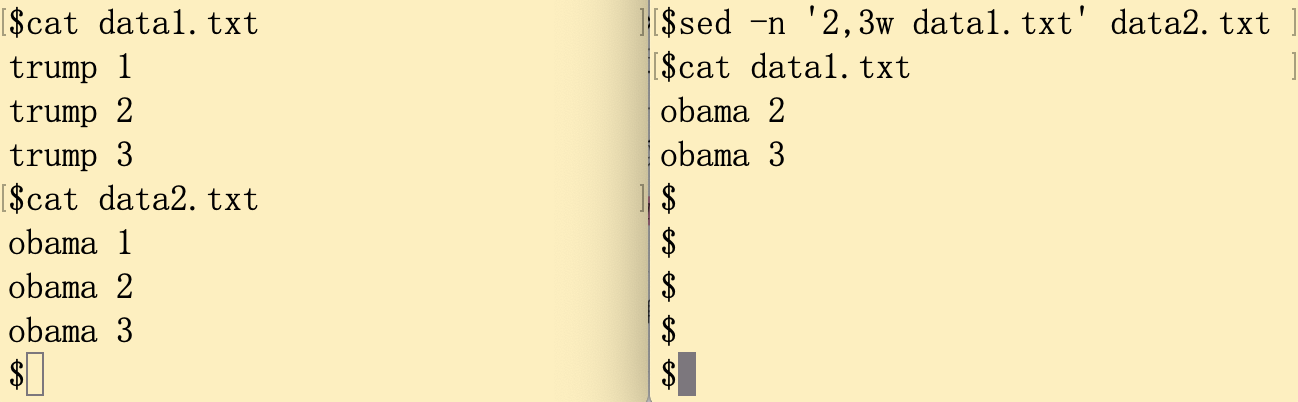
[address]w filename案例如下图所示,将data2.txt文件的第2到3行写入data1.txt,这种写如是覆盖式的。
r命令用来将文件中的数据插入到数据流中,命令格式为:
[address]r filename案例如下图所示,将data2.txt的数据作为数据流,并在第一行数据之后插入data1.txt文件的数据。

4.sed进阶
以上讲述了sed的基本用法,一般情况下,可以满足我们的使用需求。此外,sed还提供了其他更高级的使用方法。下面分别进行描述。
4.1.多行命令
之前我们讲述的sed命令都是基于单行进行处理的。但是,sed具备多行数据的处理功能,sed编辑器有三个可用来处理多行文本的特殊命令 :
(1)N——将数据流的下一行加进来构建一个多行组(multiline group);
(2)D——删除多行组中的一行;
(3)P——打印多行组中的一行。
4.1.1.next命令
单行next命令(小写n)会将数据流中的下一文本行移动到sed编辑器的工作空间(称为模式空间)。多行版本的next命令(用大写N)会将下一文本行添加到模式空间中已有的文本后。
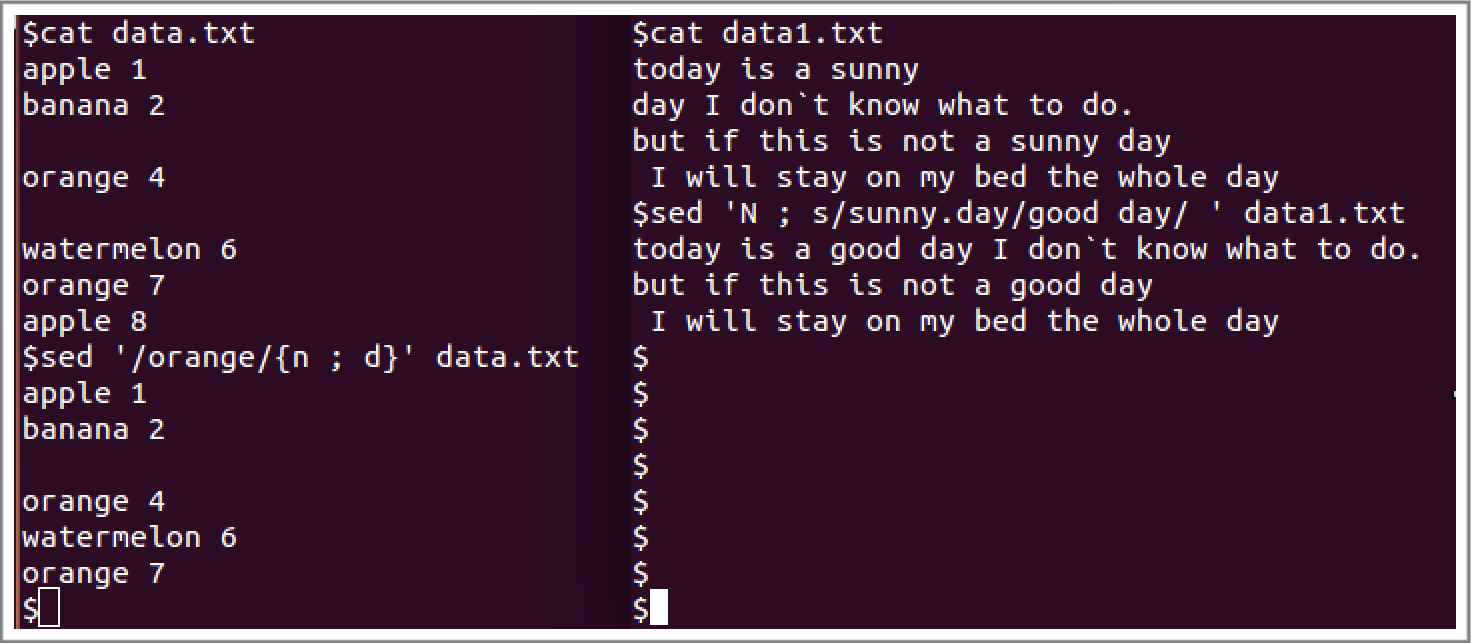
上述是next命令的替换案例中。data.txt的处理是单行命令,把带有orange单词的下一行删除。data1.txt的处理是多行命令,把“sunny.day”替换成“good day”,其中“.”是通配符。
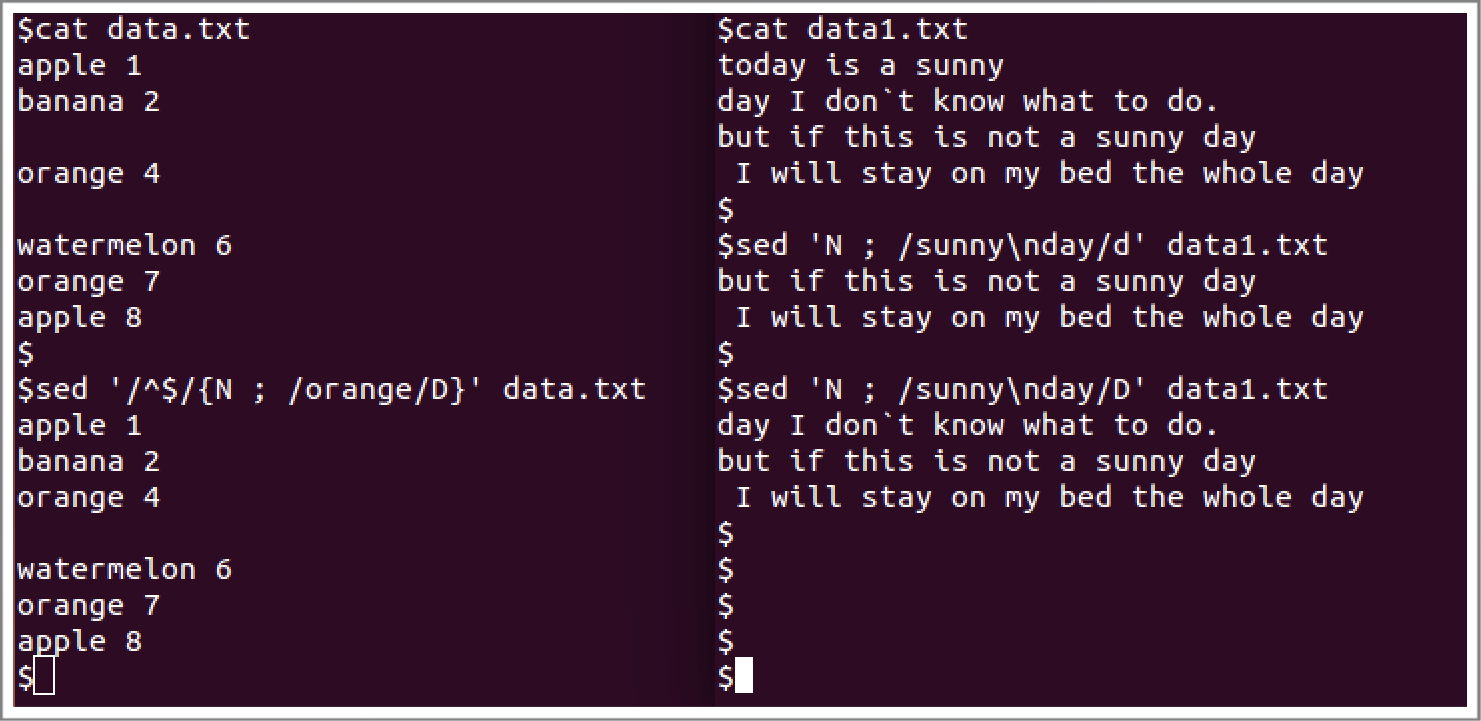
上图是next命令的删除案例。对data.txt的处理是找到空行,并把下一行加入模式空间,用orange匹配,如果匹配到,则把这个空行删除。对data1.txt的处理是“d”和“D”的区别,用d命令会把匹配到的两行都删除,而D命令则只会把模式空间中的第一行删除。
4.1.2.模式空间和保持空间
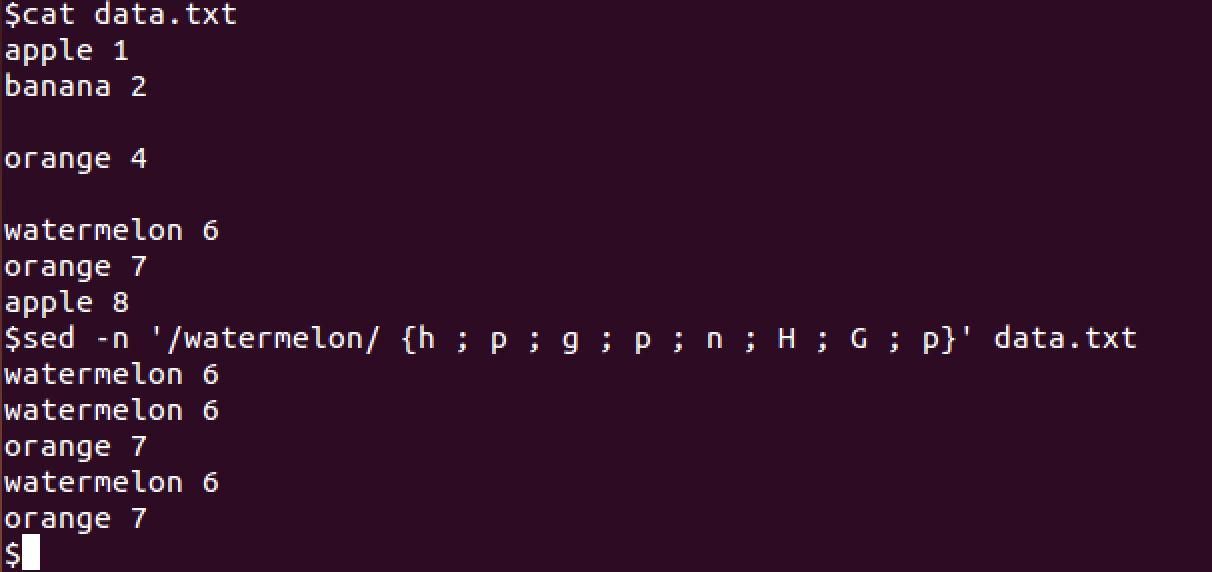
模式空间(pattern space)是一块活跃的缓冲区,在sed编辑器执行命令时会保存待检查的文本。保持空间(hold space)也是一块活跃的缓冲区,在处理模式空间中的某些行时,可以用保持空间来临时保存一些行。对保持空间的操作命令如下表所示。
案例如下图所示。
4.1.3.排除命令
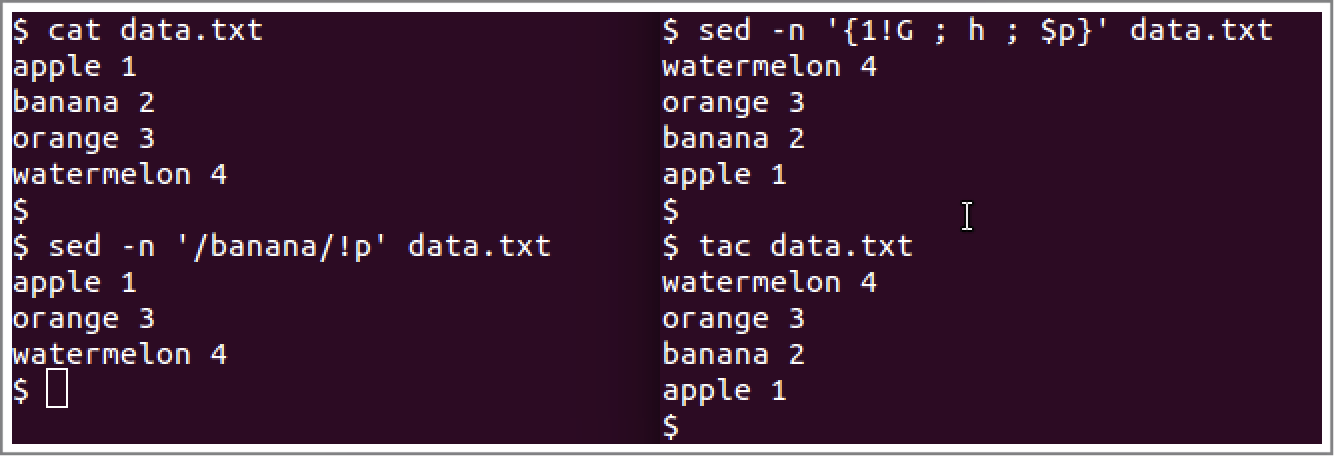
排除命令用感叹号(!)来表示,也就是让原先起作用的命令不起作用。案例如下图所示,左边的案例表示不打印包含banana单词的行数据。右边的表示对对data.txt文件中的行逆序打印,和tac命令的作用是一致的(tac与cat在拼写以及作用上都是相反的)。
4.2.改变流
一般来说,sed会从脚本的顶部开始处理,一直执行到最后一行。sed编辑器提供了一个方法来改变命令脚本的执行流程,其结果与结构化编程类似。这种方法是b命令和t命令,其中b命令基于地址、地址模式或地址区间来进行跳转,而t命令根据上一条命令的结果来决定跳转。
4.2.1.b命令
b命令行格式为:
[address]b [label]其中address决定了哪些行的数据会触发b命令。label参数定义了要跳转到的位置,如果没有加label参数,则命令会跳转到脚本的结尾。
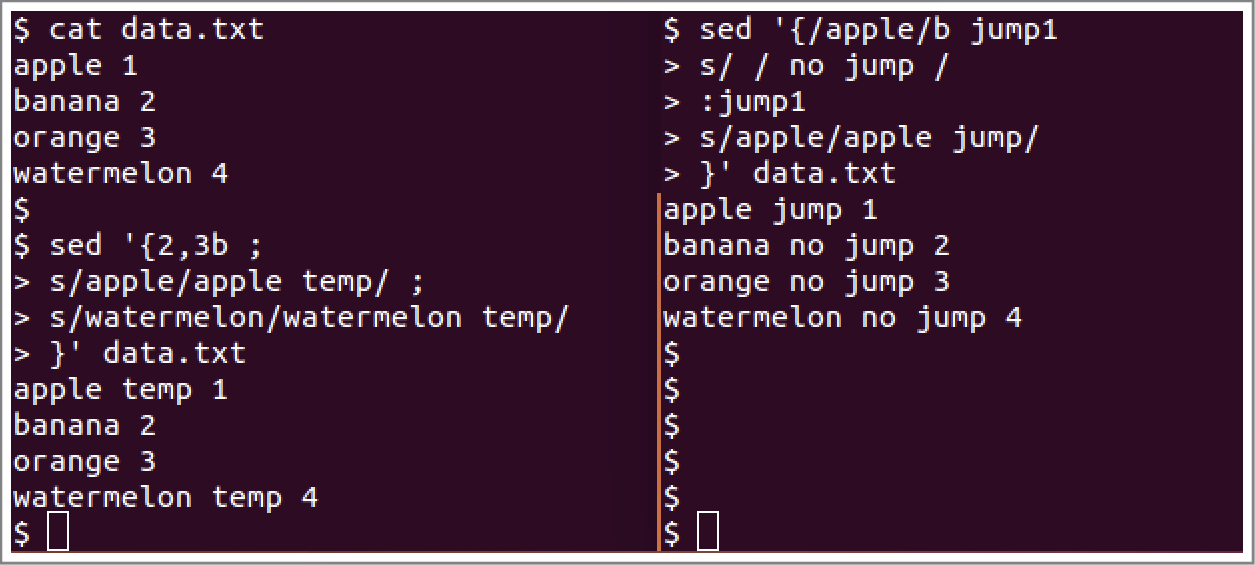
案例如上图所示,左边的案例表示无label的命令,第2到3行数据不执行替换命令。右边的是代label的命令。
我们还可以使用sed的b命令来构成循环,如下图所示:
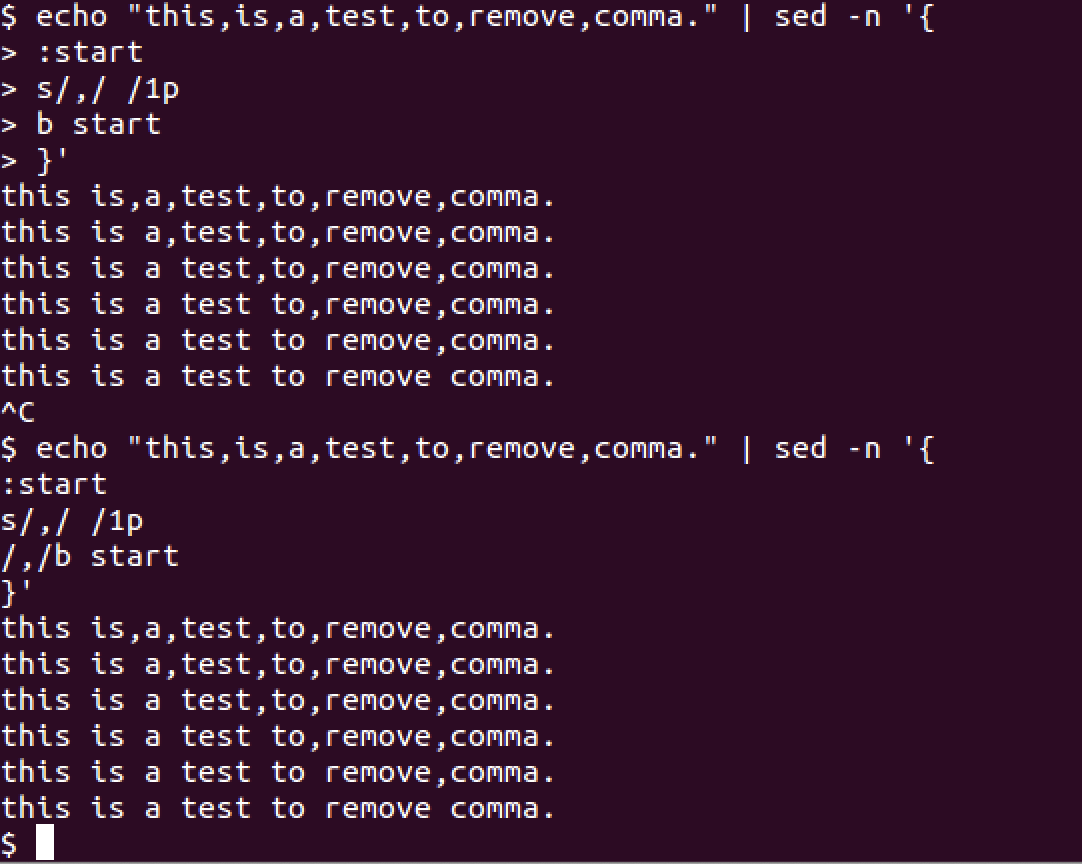
第一种情况,因无指定地址,b命令会一直执行,构成死循环,而第二种情况,指定了匹配条件,如果查找不到“,”则不会执行b命令。
4.2.2.t命令
t命令的命令行格式和b命令一致
[address]t [label]如果测试成功,则t命令会直接跳转到脚本的尾部,测试失败,则会继续执行t命令之后的脚本。案例如下图所示:
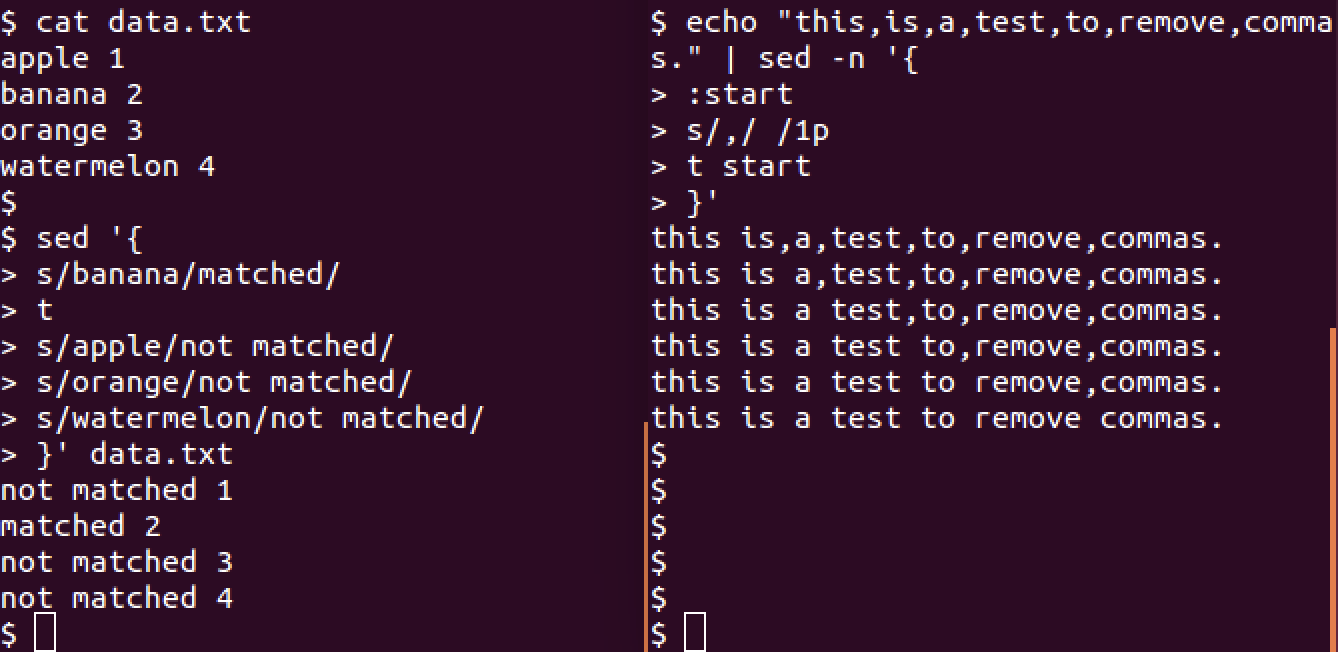
左边的案例是无label情况,如果第一条替换命令执行成功,则不会执行t命令后面的替换命令;如果第一条命令匹配失败,无法替换,则会执行t命令后面的替换命令。
右边的案例是有label的情况,循环替换行数据的逗号。
根据以上案例可以看出,t命令其实和if-else的逻辑是一致的,只有当t命令之前的命令匹配失败才会执行t命令之后的脚本或命令。
4.3.模式替代
以上介绍的sed的替换命令都是覆盖式的替换,即把匹配到的模式用其他的具体的单词覆盖。很多时候,我们需要修改式的替换,即在原来的单词基础上进行修改。为此,sed提供了一个解决方案——&符号。替代模式中,可以使用&来代替匹配到的单词。案例如下图所示:
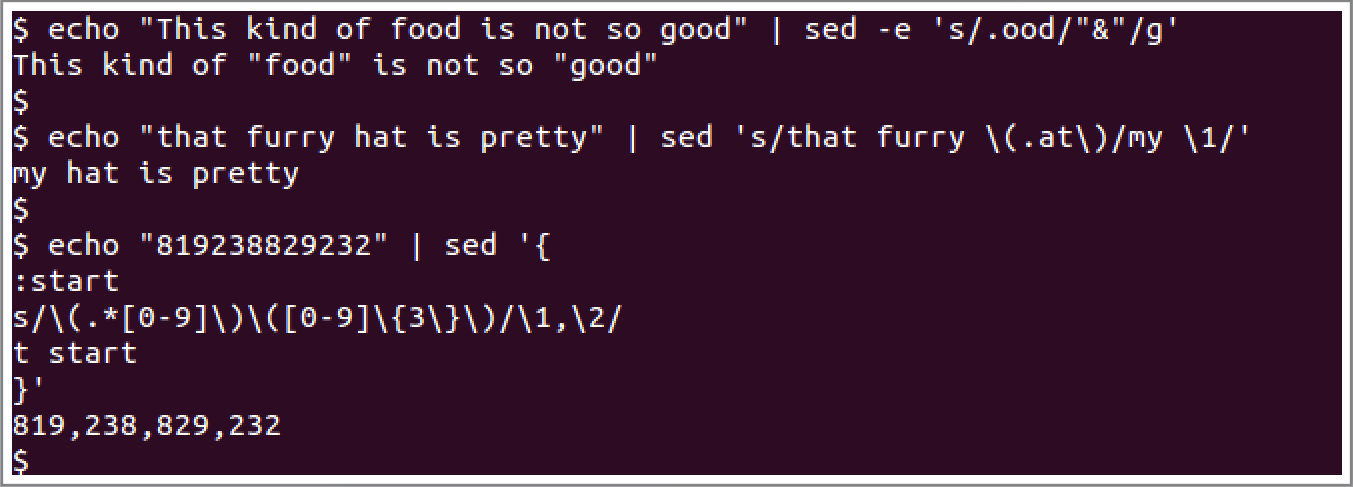
其中“.”是通配符,可匹配任意字符。
上图中第一个案例把ood结尾的四字符单词加上双引号。
第二个案例把that furry hat替换成my cat。
第三个案例给数字进行三位分隔。
第二、三个案例都用到了子模式,“\1”和“\2”指第一个和第二个子模式匹配到的字符串。如果有多个子模式,可同理递推。