1.CPU架构
CPU有三大架构:SMP、NUMA、MPP。
1.1.SMP架构
经典的CPU架构为对称多处理结构,也就是Symmetric Multi-Processing,简称SMP。
如下图所示:
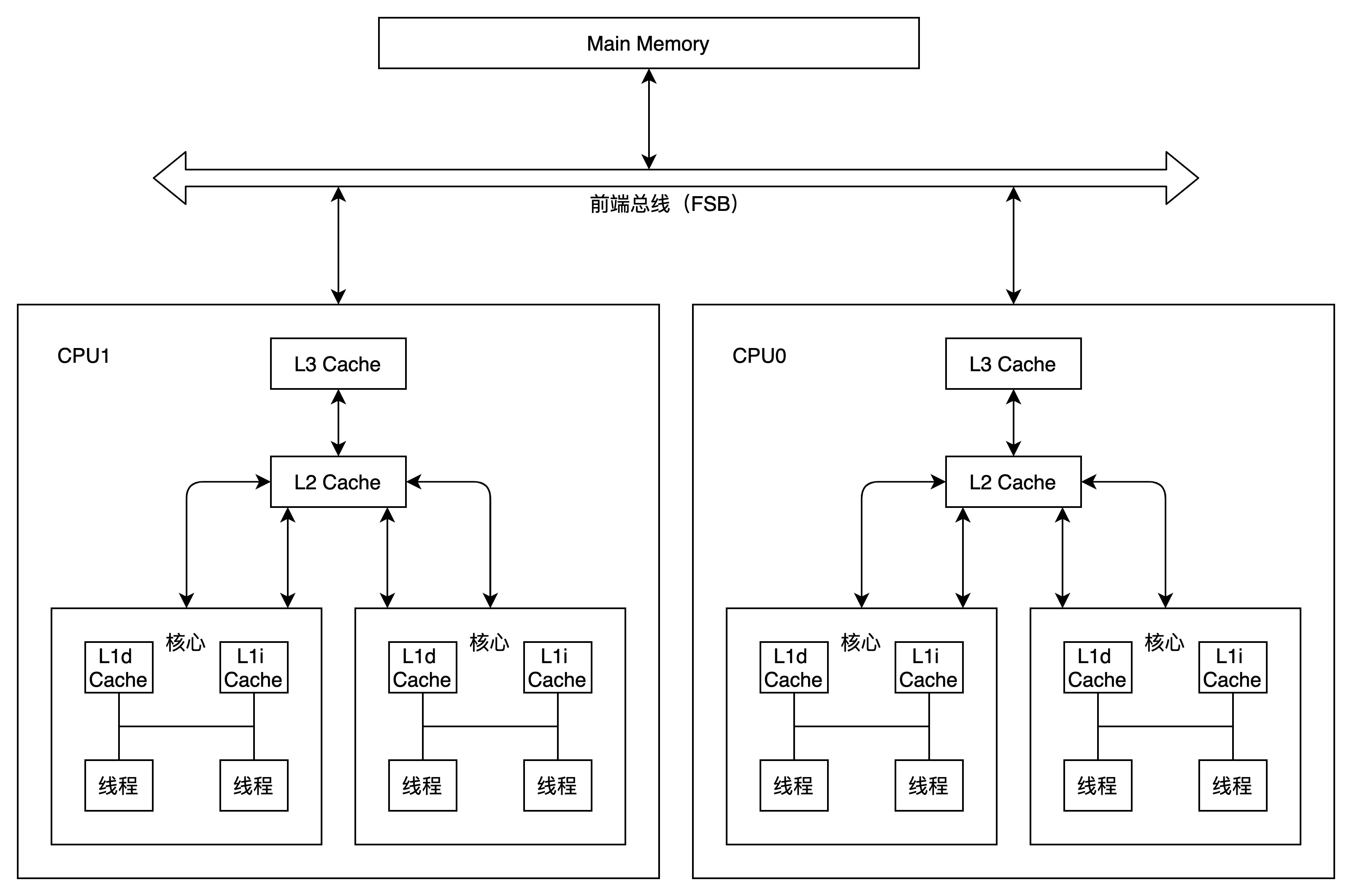
图中有两个CPU,每个CPU有两个核心(core),每个核心有独立的L1d Cache(L1数据缓存)和L1i Cache(L1指令缓存)。同一个CPU的多个核心共享L2和L3缓存。
某些CPU还可以通过超线程技术(Hyper-Threading Technology)使一个核心具有同时执行两个线程的能力。超线程技术第一次出现在2002年,但intel core i7当前已砍掉此技术。通过硬件指令让一个物理核心充当两个核心的角色。如果负荷小,此技术并无实质效果;如果开了多个后台或者某个程序需要利用多线程资源,此技术能提升13%~20%的处理效率。
1.2.MPP架构
MPP全称Massive Parallel Processing,大规模并行处理模型。
MPP系统是由许多松耦合的处理单元组成的(指的是处理单元而不是处理器)。每个处理单元内的CPU都有自己私有的资源,如总线、内存、磁盘等,且都有操作系统和管理数据库的实例副本。一个处理单元类似于一个SMP服务器。每个处理单元之间均有高性能的网络设备进行交互。
1.3.NUMA架构
NUMA全称Non-Uniform Memory Access,非均匀访问存储模型。
NUMA技术有效结合了SMP系统易编程和MPP系统易扩展性的特点。
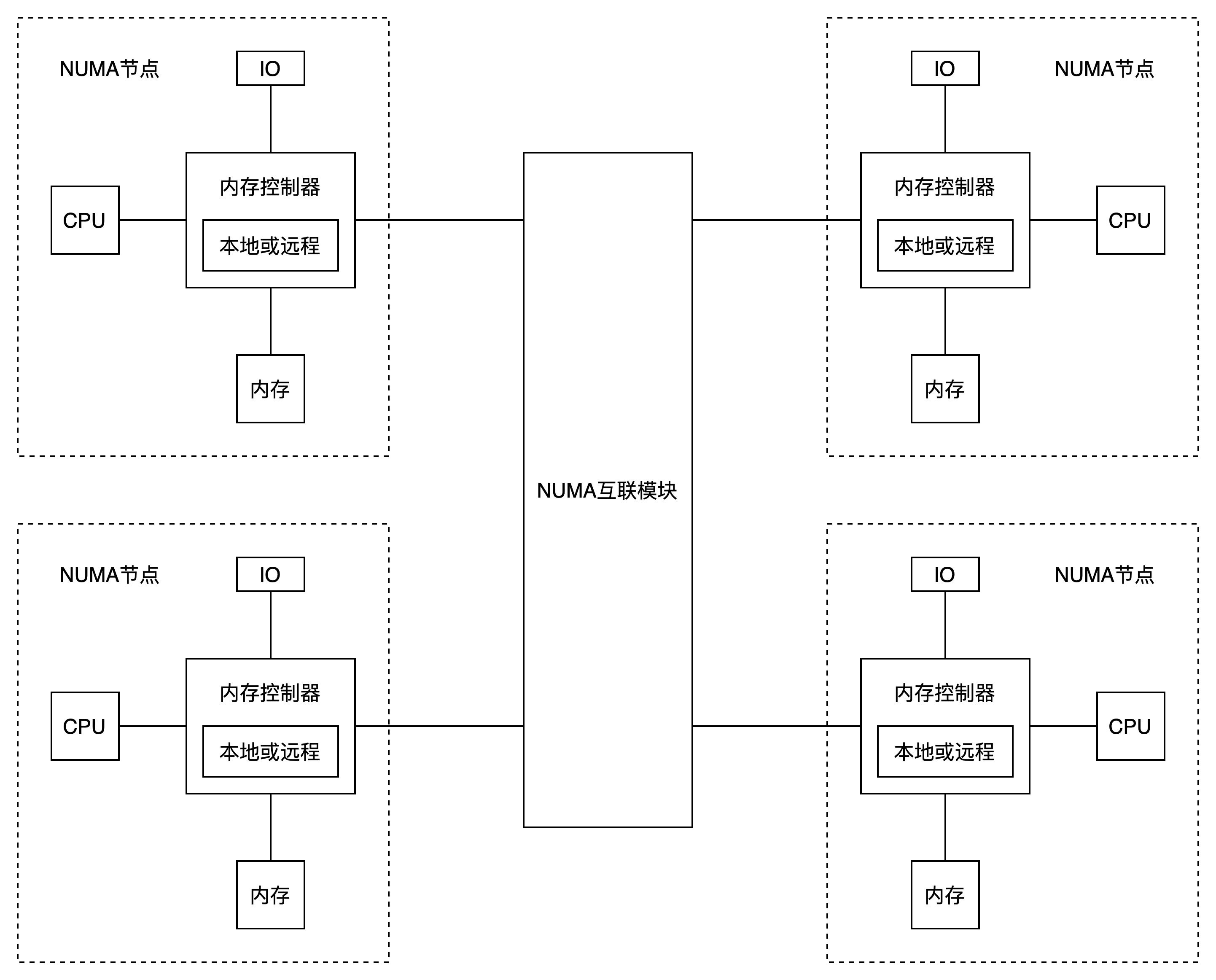
NUMA将CPU的资源分开,以node为单位进行分割,每个node是一个SMP结构,具有独有的core、memory和IO槽口等资源。node可直接访问本地内存,也可以通过NUMA互联模块访问其他node的内存,访问本地内存的速度远远高于远程访问的速度。
2.CPU高速缓存
一次内存访问所需要的时间是200~300个时钟周期,这也意味着内存和CPU的访问速度相差200~300倍。为了弥补两者间性能差异,在CPU中引入Cache,也就是高速缓存。
2.1.高速缓存的结构
CPU Cache通常分为大小不等的三级缓存:L1、L2和L3 Cache。如下图所示:
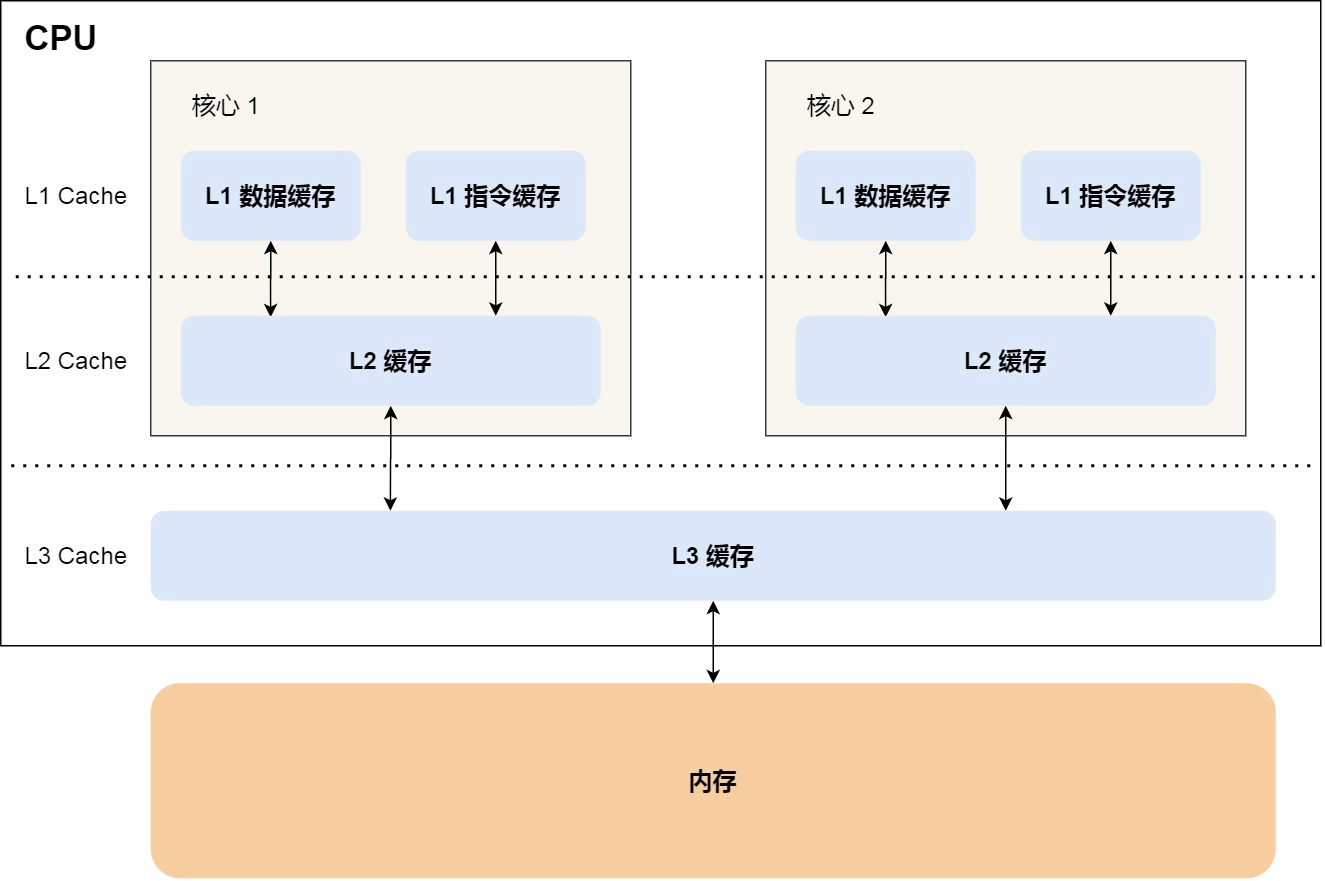
程序执行时,会先将内存中的数据加载到L3,再加载到L2,最后进入L1,之后才被CPU读取。
每层高速缓存的读写速率如下表所示:
2.2.高速缓存大小
CPU Cache所使用的材料是SRAM(Static Random-Access Memory,静态随机存储器),价格比内存使用的DRAM高出许多,同等储量的高速缓存和内存造价比接近500倍,这也是高速缓存储量较小的原因,一般以KB计,查看高速缓存大小的方法例如下图所示:
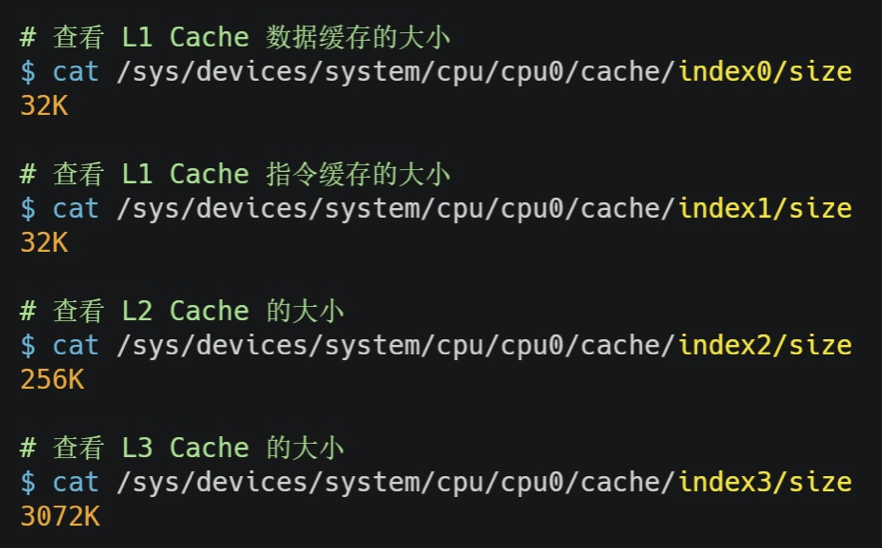
L3比L1和L2都大许多,因为L1和L2是每个CPU核心独有,而L3是多个CPU核心共享。
2.3.CPU读取内存过程
CPU读取内存是一小块一小块读取的,每块大小取决于coherency_line_size的值,一般是64字节。内存中,这一块数据称为内存块。

对于直接映射Cache采用的策略,就是把内存块的地址始终映射在一个CPU Line(缓存行),映射关系使用取模运算,运算的结果是内存块地址对应的CPU Line的地址。
一个内存的访问地址,包括组标记、CPU Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。而对于 CPU Cache 里的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成,如下图。
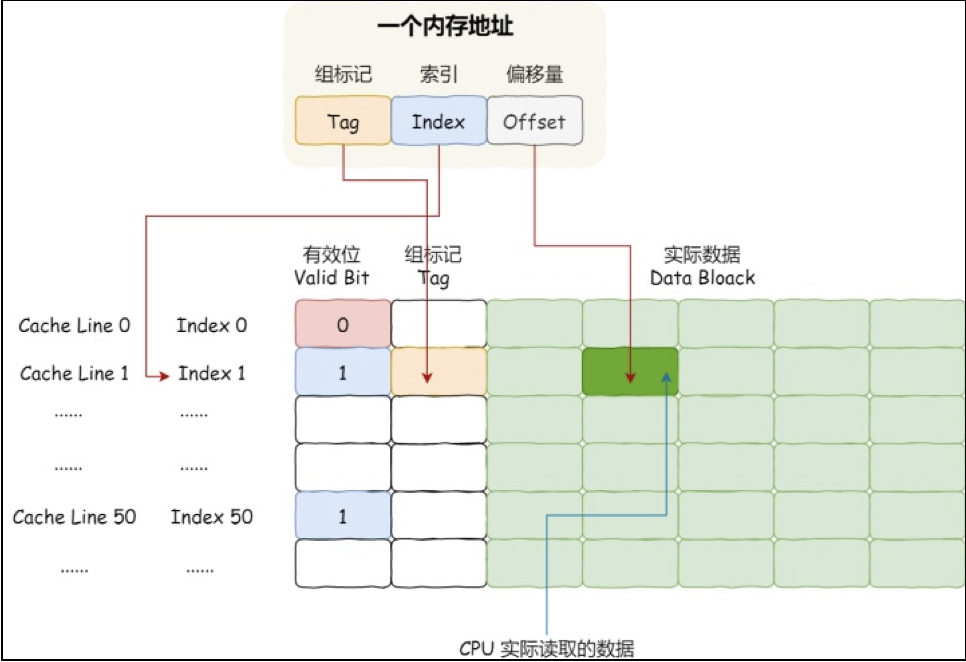
如果内存中的数据已经在 CPU Cahe 中了,那 CPU 访问一个内存地址的时候,会经历这 4 个步骤:
(1)根据内存地址中索引信息,计算在 CPU Cahe 中的索引,也就是找出对应的 CPU Line 的地址。
(2)找到对应 CPU Line 后,判断 CPU Line 中的有效位,确认 CPU Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行。
(3)对比内存地址中组标记和 CPU Line 中的组标记,确认 CPU Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行。
(4)根据内存地址中偏移量信息,从 CPU Line 的数据块中,读取对应的字。
3.存储器
现代计算机系统与冯诺依曼计算机差别不大,最大的区别是冯诺依曼计算机以运算器为中心,而现代计算机以存储器为中心。
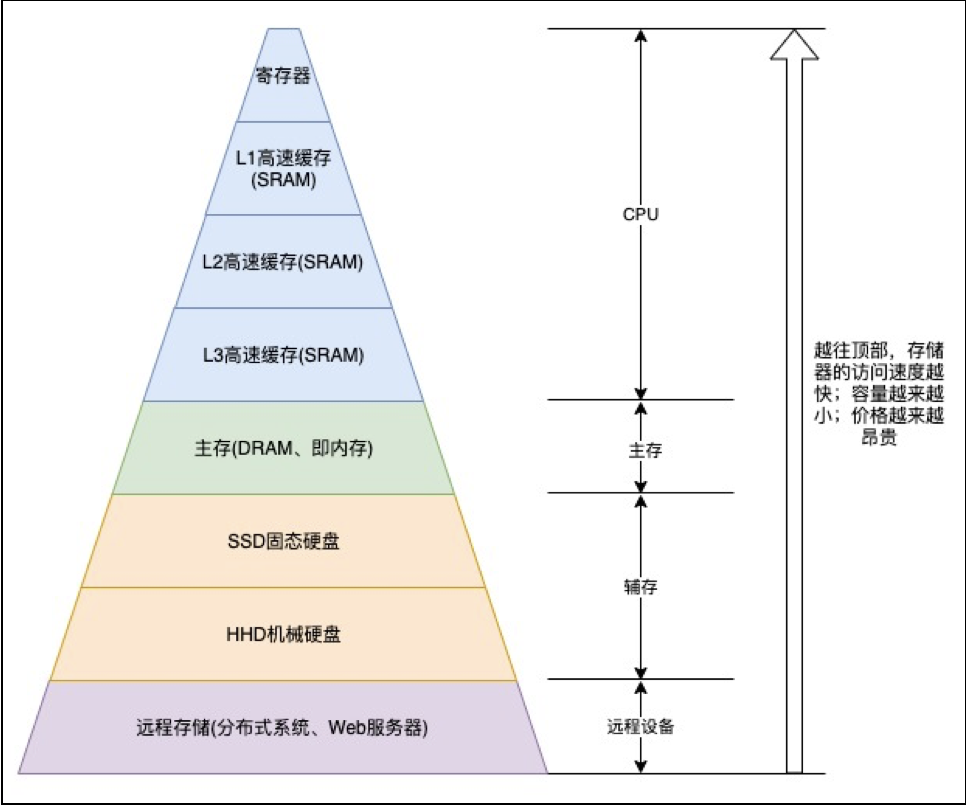
3.1.寄存器
现代CPU内部,有一个常见的组件——寄存器,是CPU内部用来存放数据的一些小型存储区域,用来暂时存放参与运算的数据以及运算结果。寄存器由电子线路组成,存取速度非常快,寄存器的成本较高,因而数量较少。
在CPU中常见的有六类寄存器:指令寄存器(IR)、程序计数器(PC)、地址寄存器(AR)、数据寄存器(DR)、累加寄存器(AC)、程序状态字寄存器(PSW)。
3.2.主存
直接与CPU交换信息,就是我们熟悉的内存。它使用的是一种叫做DRAM(Dynamic Random Access Memory)的芯片,也叫作动态随机存储器。
断电后,内存的数据是会丢失的。DRAM芯片的密度较高,功耗更低,有更大的容量,造价比SRAM芯片便宜很多,但速度比SRAM芯片慢很多。内存访问速度大概在200~300个时钟周期。
3.3.固态硬盘
固体硬盘,Solid-state Disk,简称SSD。数据直接存放在闪存颗粒中,并且由主控单元记录数据存储位置和数据操作,每一个闪存颗粒的存储容量是有限的。但是它相比内存的优点是:断电后,数据还是存在的。SSD固体硬盘的读写速度相比内存大概慢10~1000倍,但是比机械硬盘快多了。
SSD比HDD快多了,当让价格也贵,不过随着时代的发展,SSD的价格慢慢趋于HDD。
3.4.机械硬盘
Hard Disk Drive,简称HDD,它是通过物理读写的方式来访问数据,机械硬盘在盘面上写数据、磁盘转动、机械臂移动,比较原始的数据读写方式,就像近现代的留声机发声原理一样。
由于受限于转盘速度与指针寻址的时间限制,因此它访问速度非常慢,他的速度比内存慢10W倍左右。当然HDD也是有优点的:容量大、价格便宜、恢复数据难度低,因此数据放在HDD中比较保险。
4.CPU相关操作
(1)基本运算公式
# 总核数 = 物理CPU个数 * 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 每颗物理CPU的核数 超线程数(2)查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l(3)查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq(4)查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l