Flink Stream API主要有:Environment、Source、Transformation、Sink。
1.Environment
在定义Flink Job时,我们都需要先指定一个执行环境,表示当前执行程序的上下文。一般使用getExecutionEnvironment方法,如果程序时独立调用的,则此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法返回此集群的执行环境,也就是说getExecutionEnvironment方法会根据查询运行的方式决定返回什么样的执行环境。
2.Source
表示数据源,定义从哪里读取数据,以及怎样读取数据。StreamExecutionEnvironment中主要有以下方法可以生成Source:
3.Transformation
从Source读取的数据,需要经过一定的处理逻辑,Transformation正是用来实现这些逻辑的算子。
flink和spark一样,主要有以下几类算子:转换算子、聚合统计算子、多流转换算子。
3.1.转换算子
转换算子,对从Source读取的数据,进行转换并输出。
map:对数据进行一一映射,即map算子的输入和输出数据都是一一对应的。如下图所示:

flatMap:对数据进行一对多的映射,即输入一条,可输出多条。
filter:对数据进行过滤,即输入一条,输出不大于1条。
3.2.聚合统计算子
有时候需要对数据进行一定的聚合统计,下面这些数据就是实现这个功能的。
keyBy:根据key进行分组。从DataStream转换为KeyedStream,逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部是以hash的形式实现的。如下图所示:
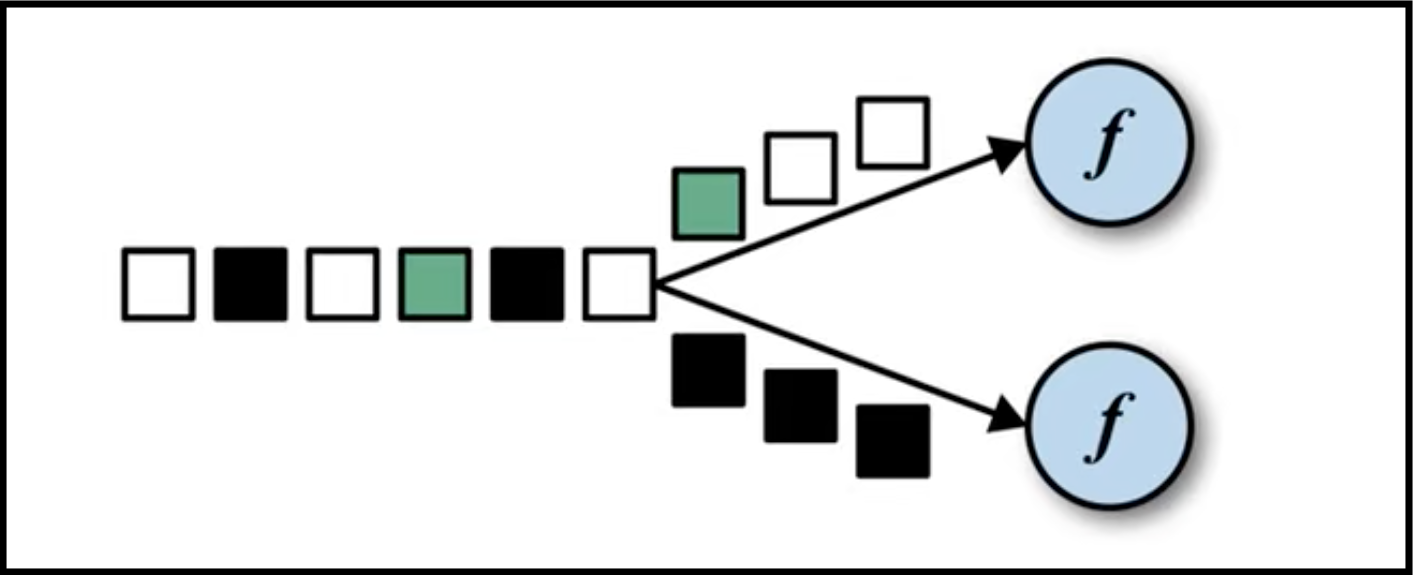
得到KeyedStream后,就可以做滚动聚合操作,针对每个支流做聚合,滚动聚合算子主要有以下五个:
(1)sum:求和。
(2)min:求小值。
(3)max:求最大值。
(4)minBy:最小值所对应的对象。
(5)maxBy:最大值所对应的对象。
一个分组的聚合操作还可以通过reduce算子来实现。reduce算子用于合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。reduce把KeyedStream聚合成DataStream。
3.3.多流转换算子
多流转换算子表示输入流或输出流有多个,主要有以下几个算子。
(1)split:根据某些特征把一个DataStream拆分成两个或者多个DataStream,即DataStream转换成SplitStream。
(2)select:从一个SplitStream中获取一个活着多个DataStream,即把SplitStream转换成DataStream。
(3)connect:连接两个保持他们类型的数据流,两个数据流被connect之后,只是被放在了同一个流中,内部依然包吃个字的数据且形式不发生任何变化,两个流相互独立。即两个DataStream转换成一个ConnectedStreams。
(4)coMap/coFlatmap:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。即把ConnectedStreams转换成DataStream。
(5)union:对两个或两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream。
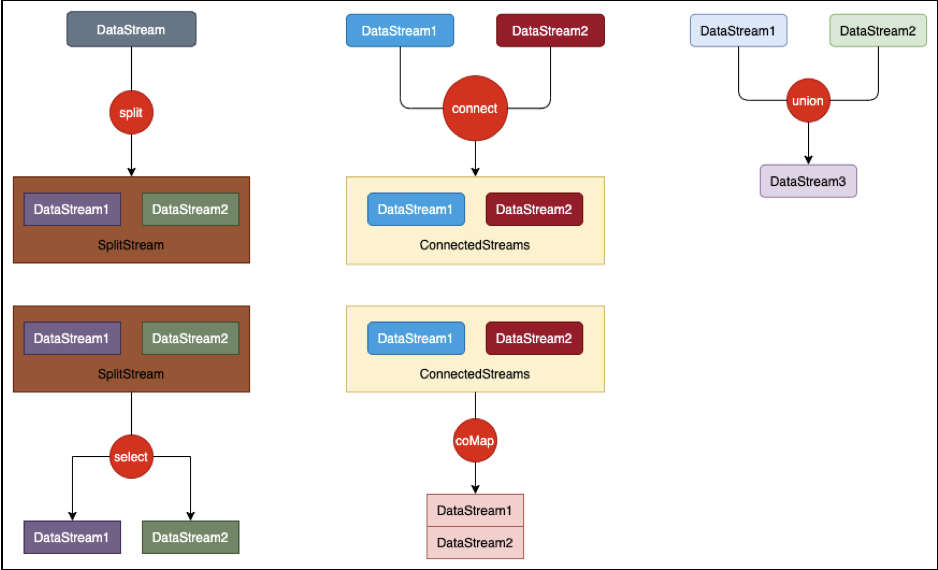
多流转换算子数据流模型如上图所示。
4.Sink
Flink没有类似于spark中foreach方法,让用户进行迭代操作。虽有对外的输出操作都要利用Sink完成,通过addSink方法来实现整个任务的最终输出操作。官方提供了一部分框架的Sink,比如Kafka、Cassandra、Kinesis、Elasticsearch、HDFS、RabbitMQ、NiFi等。第三方框架apache-bahir还提供了一些其他的Sink,比如ActiveMQ、Flume、Redis、Akka、Netty等。除此之外,用户还可自定义实现Sink。