这里是从执行计划层面对Hive进行客户端优化。
1.Explain查看执行计划
Explain呈现的执行计划,有一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。
若某个Stage对应的一个MapReduce Job,其Map端和Reduce端计算逻辑分别由Map Operator Tree和Reduce Operator Tree进行描述,Operator Tree由一系列的Operator组成,一个Operator代表在Map或Reduce阶段的一个单一的逻辑操作,例如TableScan Operator、Select Operator、Join Operator等。
下面,以“explain select sum(id) from test1;”为例,查看Explain的输出demo,如下图所示:
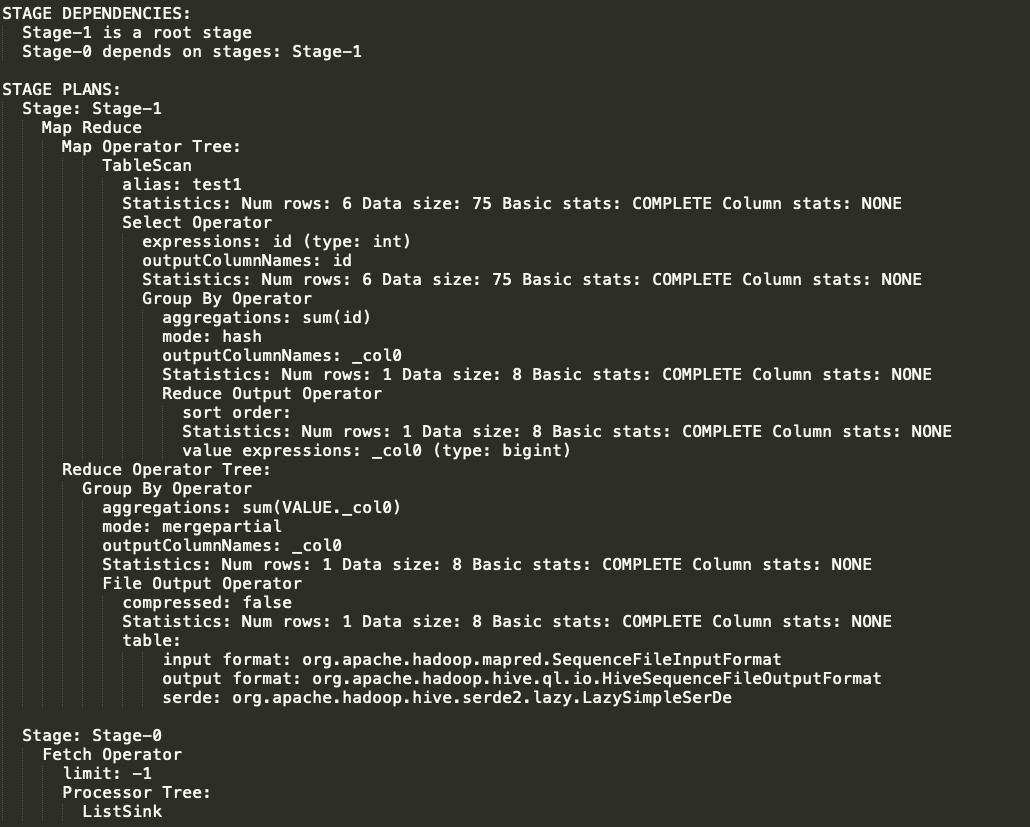
1.1.Explain语法说明
Explain语法如下:
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query-sql参数说明如下:
(1)EXTENDED:加上 extended 可以输出有关计划的额外信息。这通常是物理信息,例如文件名。这些额外信息对我们用处不大
(2)CBO:输出由Calcite优化器生成的计划。CBO 从 hive 4.0.0 版本开始支持
AST:输出查询的抽象语法树。AST 在hive 2.1.0 版本删除了,存在bug,转储AST可能会导致OOM错误,将在4.0.0版本修复
(3)DEPENDENCY:dependency在EXPLAIN语句中使用会产生有关计划中输入的额外信息。它显示了输入的各种属性,比如执行计划需要读取的表以及分区。
(4)AUTHORIZATION:显示所有的实体需要被授权执行(如果存在)的查询和授权失败
(5)LOCKS:这对于了解系统将获得哪些锁以运行指定的查询很有用。LOCKS 从 hive 3.2.0 开始支持
(6)VETORIZATION:将详细信息添加到EXPLAIN输出中,以显示为什么未对Map和Reduce进行矢量化。从 Hive 2.3.0 开始支持
(7)ANALYZE:用实际的行数注释计划。从 Hive 2.2.0 开始支持
(8)FORMATTED:将执行计划以JSON字符串的形式输出。
1.2.常见的Operator
常见的Operator及其作用如下:
(1)TableScan:表扫描操作,通常map端第一个操作是表扫描操作。
(2)Select Operator:select操作。
(3)Group By Operator:分组聚合操作。
(4)Reduce Output Operator:输出到reduce操作。
(5)Filter Operator:过滤操作。
(6)Join Operator:join操作。
(7)File Output Operator:文件输出操作。
(8)Fetch Operator:客户端获取数据操作。
获取到执行计划后,就可以通过调整SQL来优化执行计划。
2.分组聚合优化
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的,Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。Hive对分组聚合的优化主要围绕减少Shuffle的数据量进行,具体做法是map-side聚合。
map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能减少shuffle的数据量,提高分组聚合运算的效率。
Map-side聚合相关的参数有:
(1)set hive.map.aggr=true;——启用map-side聚合。默认为true。
(2)set hive.map.aggr.hash.min.reduction=0.5;——用于检测源表数据源是否适合进行map-side聚合。检测方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合钱的条数比值小于该配置值,则认为该表适合进行map-side聚合;否则认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
(3)set hive.goupby.mapaggr.checkinterval=100000;——用于检测源表是否适合map-side聚合的条数。
(4)set hive.map.aggr.hash.force.flush.memory.threshold=0.9;——map-side聚合所用的的hash table占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。