KafkaConsumer是一个从Kafka集群消费消息的客户端。这个客户端可以明显处理Kafka Broker的失败,也能明显适应在集群内获取的topic分区。这个客户端也与broker交互,允许一群consumer之间均衡消费。
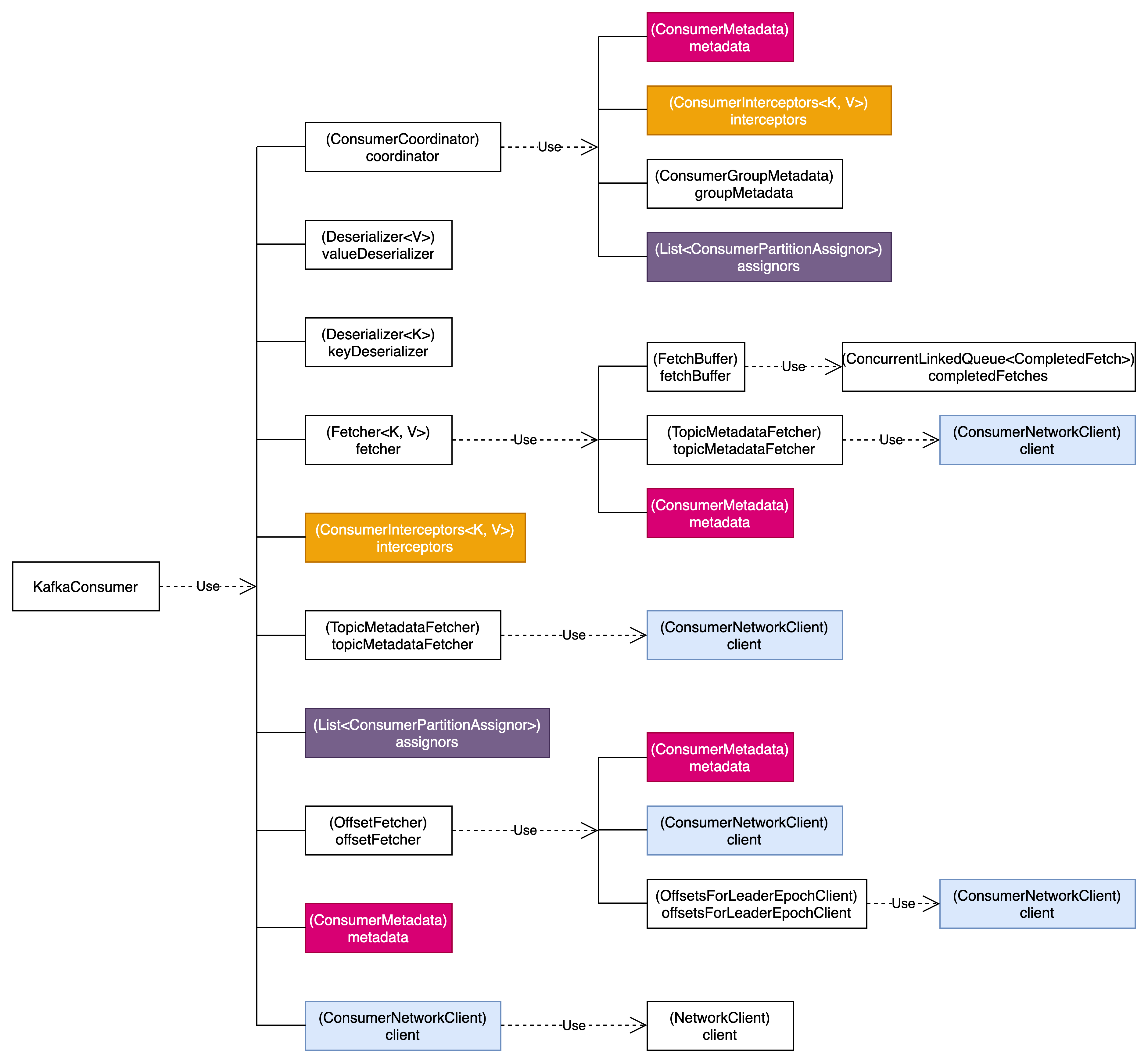
KafkaConsumer引用链
KafkaConsumer维护了与必要的Broker之间的TCP连接,用于提取数据。如果使用之后没有关闭consumer,就会失去这些连接。
KafkaConsumer线程不安全
KafkaConsumer不是线程安全的,在执行每个公用方法之前,KafkaConsumer会调用acquire()方法,该方法用于检测是否只有一个线程在进行操作。
/**
* Acquire the light lock protecting this consumer from multi-threaded access. Instead of blocking
* when the lock is not available, however, we just throw an exception (since multi-threaded usage is not
* supported).
* @throws ConcurrentModificationException if another thread already has the lock
*/
private void acquire() {
final Thread thread = Thread.currentThread();
final long threadId = thread.getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access. " +
"currentThread(name: " + thread.getName() + ", id: " + threadId + ")" +
" otherThread(id: " + currentThread.get() + ")"
);
refcount.incrementAndGet();
}这实际上通过CAS的方式来获取当前KafkaConsumer的使用权。如果获取不到,则抛出异常。
在执行线程完成后,会调用release()方法来释放KafkaConsumer的使用权。
/**
* Release the light lock protecting the consumer from multi-threaded access.
*/
private void release() {
if (refcount.decrementAndGet() == 0)
currentThread.set(NO_CURRENT_THREAD);
}poll机制
Kafka采用消息拉取模型,要求消费者通过主动调用KafkaConsumer#poll(java.time.Duration)方法向broker拉取数据。虽然Kafka并未限制获取数据后的消费方式,但为了平衡完备的功能和客户端易用性,将consumer设计为以单线程持续调用poll方法的形式来拉取消息。
poll方法内部并非简单地发送请求给broker并等待响应,然后将消息数据返回给调用方。实际上Fetch内部维护了一个链表ConcurrentLinkedQueue completedFetches,用来缓存已经拉取到的消息数据。
每次当Kafka Consumer调用poll方法的时候会先从completedFetches缓存中(线程安全的链表)查找是否存在未消费的数据,如果存在未消费的数据,Kafka直接解码后返回。
如果缓冲区中没有未消费数据,则根据订阅的情况向所有相关的broker节点发送异步请求,异步响应的结果都会存储在缓存冲区。
消费者线程会等到知道缓冲区有可用数据或者超时,循环解析缓冲链表中的数据,返回不超过(max.poll.records)的消息。
Fetch过程
KafkaConsumer实例中会创建一个Fetcher实例,用于发送FetchRequest,针对订阅到的Partition发送FetchRequest。
与四个参数相关
(1)fetch.max.bytes:一个FetchRequest最大请求的数据量。
(2)fetch.min.bytes:一个FetchRequest最少请求的数据量。
(3)max.partition.fetch.bytes:一个FetchRequest在每个分区上最多拉取多少数据。
(4)fetch.max.wait.ms:服务端返回FetchRequest请求最长等待时间。
Kafka消费过程源码解析
以下内容来自Kafka-3.9.0源码。
Kafka消费的完整过程可分为以下步骤。
KafkaConsumer初始化
KafkaConsumer初始化过程如下所示:
new KafkaConsumer(config)
ConsumerDelegateCreator#create(config)
// 根据group.protocol配置进行不同类的初始化
if 配置值为CONSUMER
new AsyncKafkaConsumer(config)
else
// 配置值为Classic,表示经典的消费者,默认模式
new ClassicKafkaConsumer(config)
groupRebalanceConfig = new GroupRebalanceConfig(config)
this.groupId = Optional.ofNullable(groupRebalanceConfig.groupId);
this.clientId = config.getString('client.id');
boolean enableAutoCommit = config.getBoolean('enable.auto.commit');
this.requestTimeoutMs = config.getInt('request.timeout.ms');
this.defaultApiTimeoutMs = config.getInt('default.api.timeout.ms');
this.retryBackoffMs = config.getLong('retry.backoff.ms');
this.retryBackoffMaxMs = config.getLong('retry.backoff.max.ms');
// 初始化消费者元数据管理器
this.metadata = new ConsumerMetadata(config)
// 初始化ConsumerNetworkClient
this.client = createConsumerNetworkClient(config, metadata)
// 分区分配策略
this.assignors = ConsumerPartitionAssignor.getAssignorInstances(config)
// 消费组协调器
this.coordinator = new ConsumerCoordinator(config, client, metadata)
this.fetcher = new Fetcher<>(client, metadata)
this.offsetFetcher = new OffsetFetcher(client, metadata)
this.topicMetadataFetcher = new TopicMetadataFetcher(client)ClassicKafkaConsumer是最常用的。
订阅topic或分区
通过subscribe方法进行topic的订阅,也可以通过assign方法指定对应的分区进行消费。
subscribe模式
subscribe模式下,coordinator会为consumer自动分配partition,有内部算法保证topic-partition以最优的方式均匀分配给相同group下的不同consumer。
subscribe方法执行过程如下:
org.apache.kafka.clients.consumer.internals.ClassicKafkaConsumer#subscribe(topics)
ClassicKafkaConsumer#acquireAndEnsureOpen()
// 获取轻量级锁,确保消费者未被关闭
ClassicKafkaConsumer#acquire()
// 检测是否只有一个线程在进行操作。如果有其他线程正在操作,acquire()将抛出ConcurrentModificationException异常。
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(-1, threadId))
// 当前线程不是消费者标记的currentThread,则说明是多线程不安全导致,抛异常
throw new ConcurrentModificationException()
refcount.incrementAndGet()
if (this.closed)
// 如果消费者被关闭了,则释放轻量级锁,确保consumer不会被多线程访问
ClassicKafkaConsumer#release
currentThread.set(-1);
// 获取当前订阅的topic-partitions信息
Set<TopicPartition> currentTopicPartitions
// 清理未被订阅的topic-partitions信息
fetcher.clearBufferedDataForUnassignedPartitions(currentTopicPartitions)
if(this.subscriptions.subscribe(topics))
// 更新元数据
metadata.requestUpdateForNewTopics()主要就是准备和更新订阅的topic-partition元数据信息
执行线程完成后,会调用release()方法来释放KafkaConsumer的使用权。
assign模式
assign模式下,需要开发者明确为consumer指定需要消费的topic-partitions,不受group.id限制,相当于指定的group.id无效。
assign方法执行过程如下:
org.apache.kafka.clients.consumer.internals.ClassicKafkaConsumer#assign(partitions)
ClassicKafkaConsumer#acquireAndEnsureOpen()
// 获取轻量级锁,确保消费者未被关闭
ClassicKafkaConsumer#acquire()
// 检测是否只有一个线程在进行操作。如果有其他线程正在操作,acquire()将抛出ConcurrentModificationException异常。
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(-1, threadId))
// 当前线程不是消费者标记的currentThread,则说明是多线程不安全导致,抛异常
throw new ConcurrentModificationException()
refcount.incrementAndGet()
if (this.closed)
// 如果消费者被关闭了,则释放轻量级锁,确保consumer不会被多线程访问
ClassicKafkaConsumer#release
currentThread.set(-1);
// 清理未被订阅的topic-partitions信息
fetcher.clearBufferedDataForUnassignedPartitions(partitions)
if (coordinator != null)
// 如果enable.auto.commit为true,尝试指定异步自动offset提交,
this.coordinator.maybeAutoCommitOffsetsAsync(time.milliseconds());
if (this.subscriptions.assignFromUser(new HashSet<>(partitions)))
// 更新元数据
metadata.requestUpdateForNewTopics()执行线程完成后,会调用release()方法来释放KafkaConsumer的使用权。
poll拉取消息
通过poll方法阻塞式拉取消息
poll方法执行过程如下所示:
org.apache.kafka.clients.consumer.internals.ClassicKafkaConsumer#poll(timeout)
// 初始化定时器
Timer timer = time.timer(timeout)
// Consumer检查
ClassicKafkaConsumer#acquireAndEnsureOpen()
while (timer.notExpired()) // 定时器未超时,则循环执行以下逻辑
// 唤醒NetworkClient
ConsumerNetworkClient#maybeTriggerWakeup()
ClassicKafkaConsumer#updateAssignmentMetadataIfNeeded(timer, false)
Fetch<K, V> fetch = ClassicKafkaConsumer#pollForFetches(timer);
Fetch<K, V> fetch = fetcher.collectFetch();
if (!fetch.isEmpty())
// 如果数据集已然可得,则直接返回
return fetch;
ClassicKafkaConsumer#sendFetches();
return fetcher.sendFetches()
ConsumerNetworkClient#poll()
NetworkClient#poll()
return fetcher.collectFetch();
if (!fetch.isEmpty()) // fetch结果不为空
// 返回fetch结果集之前,我们可以发送下一轮的fetch请求,避免用户处理fetch结果集时管道流被阻塞等待
if (sendFetches() > 0 || client.hasPendingRequests())
ConsumerNetworkClient#transmitSends();
return this.interceptors.onConsume(new ConsumerRecords<>(fetch.records()));
// 定时器超时后,返回空结果集
return ConsumerRecords.empty();Fetcher内部维护了一个链表ConcurrentLinkedQueue completedFetches,用来缓存已经拉取到的消息数据。
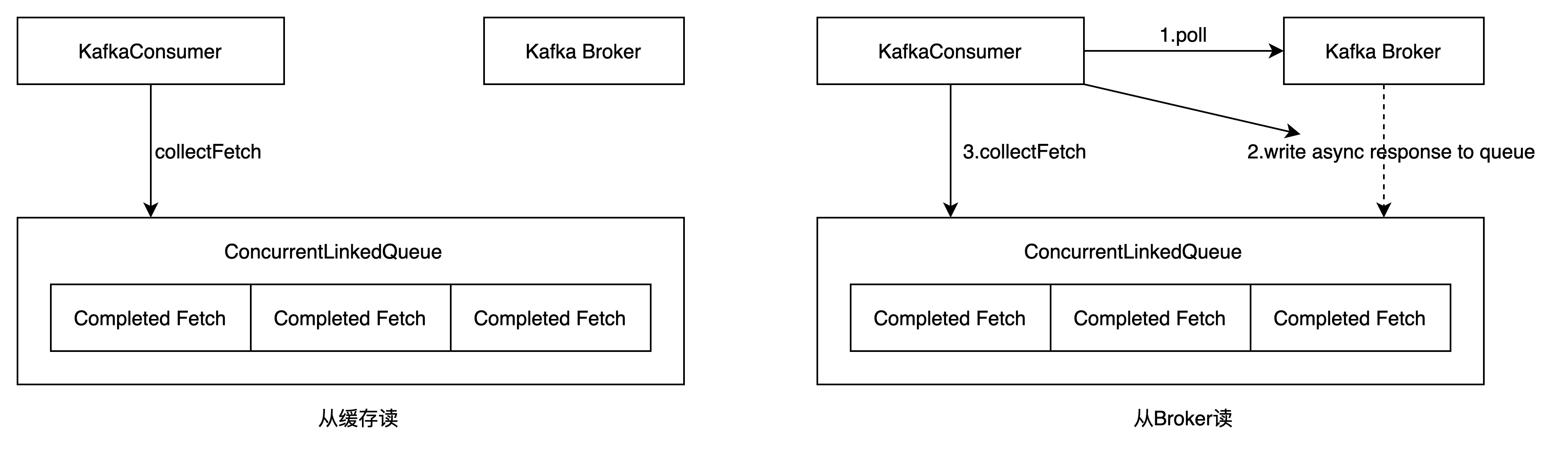
每次当Kafka Consumer调用poll方法的时候会先从completedFetches缓存中(线程安全的链表)查找是否存在未消费的数据,如果存在未消费的数据,Kafka直接解码后返回。
如果缓冲区中没有未消费数据,则根据订阅的情况向所有相关的broker节点发送异步请求,异步响应的结果都会存储在缓存冲区。
消费者线程会等到知道缓冲区有可用数据或者超时,循环解析缓冲链表中的数据,返回不超过(max.poll.records)的消息。