官网中,flink的定义为:Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale。
简而言之,Flink就是实时处理大数据的框架。
1.传统数据处理框架
传统数据处理框架无非两种:OLTP(在线事务处理)和OLAP(在线分析处理)。
1.1.事务处理框架
框架结构如下图所示:
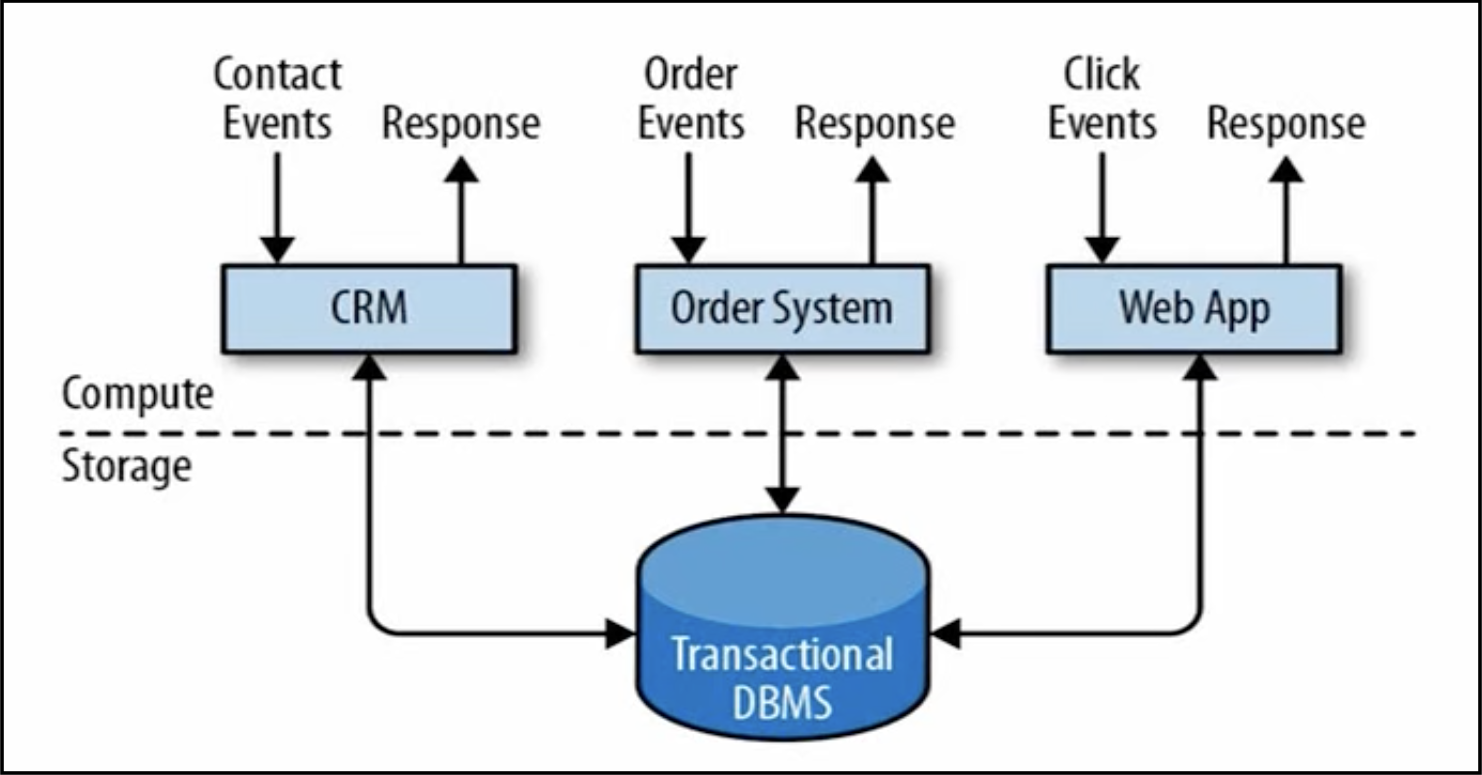
事务处理框架的优点是:实时性好。
最大的问题是:同一时间所能并发处理的数据量有限。
1.2.分析处理框架
框架结构如下图所示:
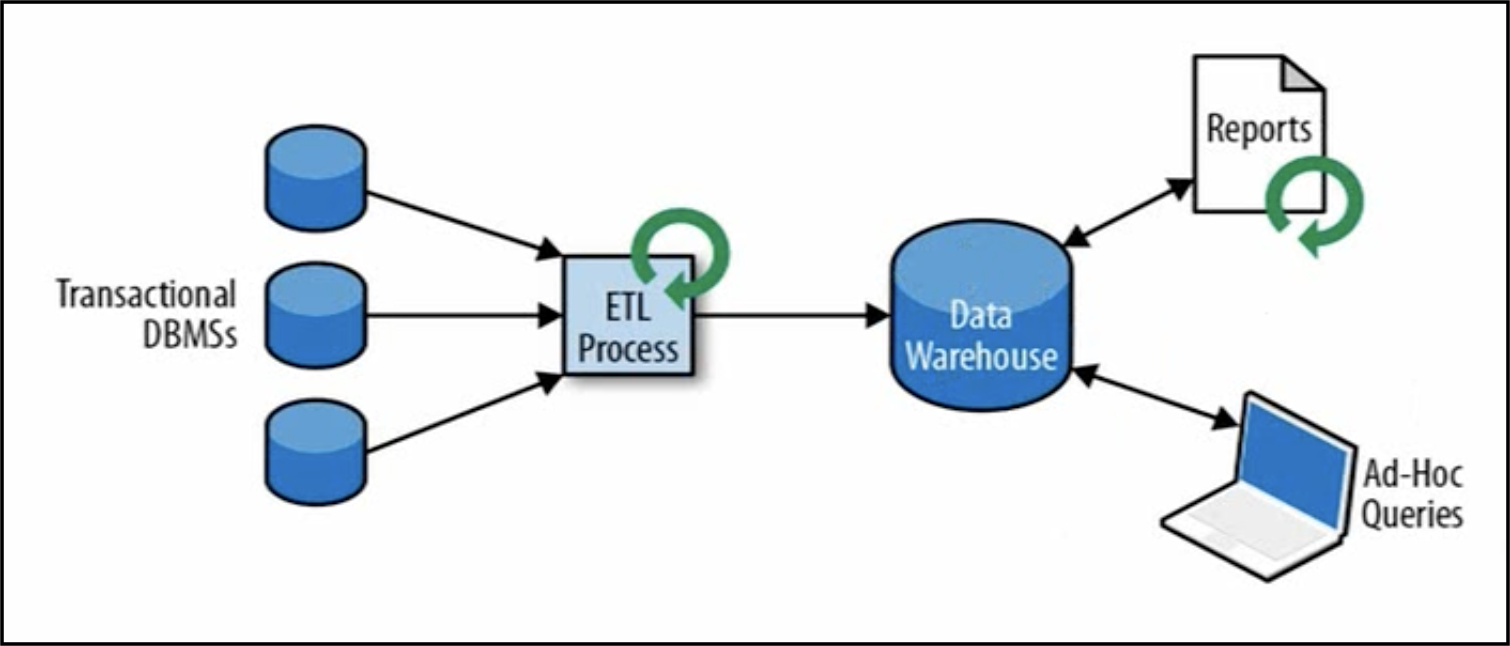
将数据从业务数据库通过ETL加载到数据仓库中,在进行分析和查询。
分析处理框架缺点是:流程长,无法做到实时处理。优点是:支持高并发和海量数据处理。
2.流处理框架
流处理框架主要是基于连续不断的数据流的处理,常用的有storm、spark streaming、flink。其中,storm以低延迟的特点而著称;Spark Streaming以高吞吐和压力下保持数据正确而著称;而Flink则继承了Storm和Spark Streaming的优点,并能实现操作简单、表现力好、输入输出数据时间准确、以及语义化窗口。
2.1.有状态的流式处理
处理框架如下图所示:
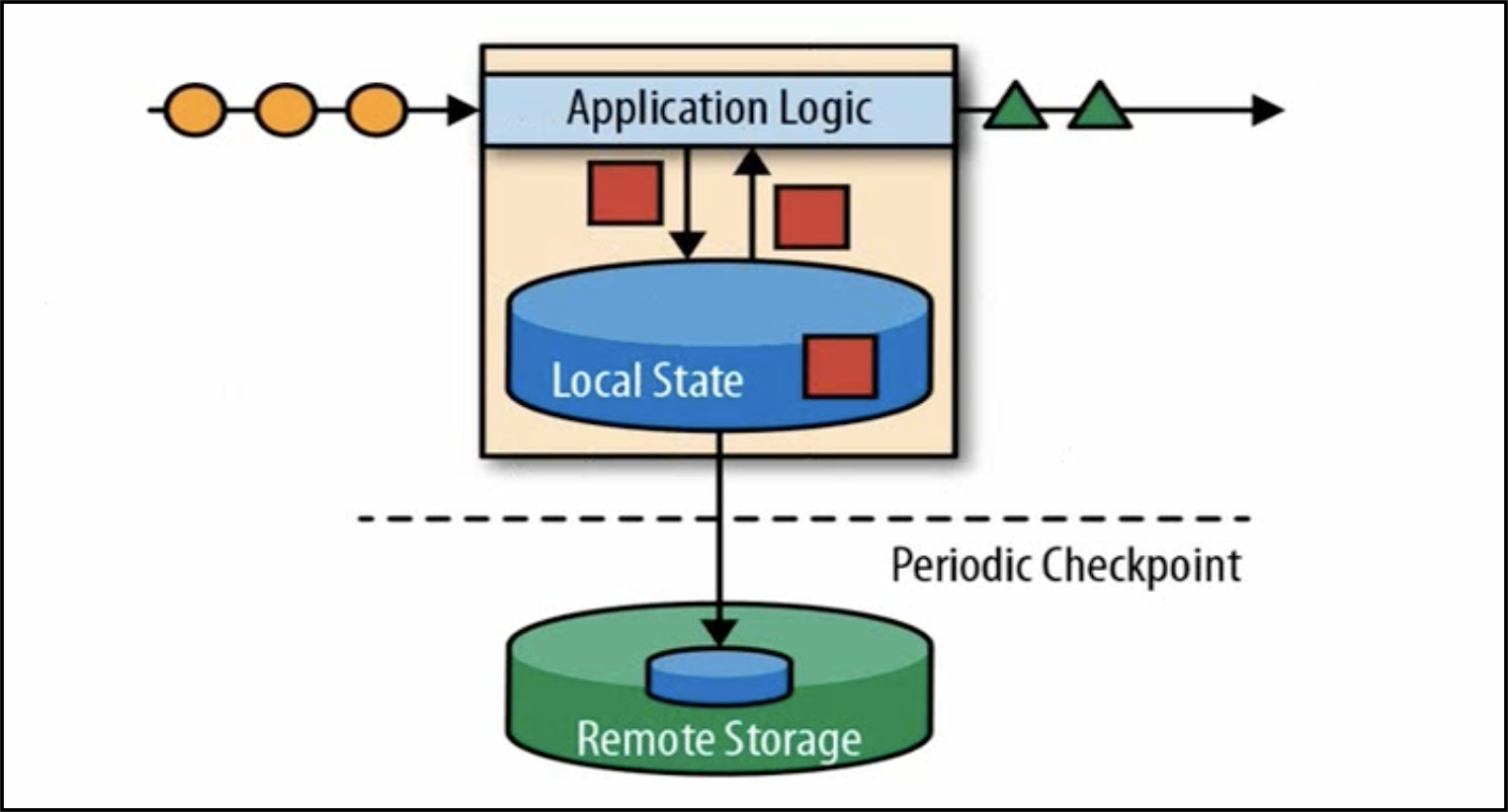
这是第一代流处理架构,把应用逻辑处理过程当中用到的数据同步到本地缓存(local state)中,不是直接从关系型数据库中查询。本地缓存通过checkpoint机制保证故障恢复。
优点是:低延迟、高吞吐、有一定容错能力。但有个非常严重的问题:在分布式架构下,如果输入数据是根据时间有序的,在处理完后,无法保证顺序。
2.2.lambda架构
基于有状态的流处理框架的问题,提出了lambda架构,如下图所示:
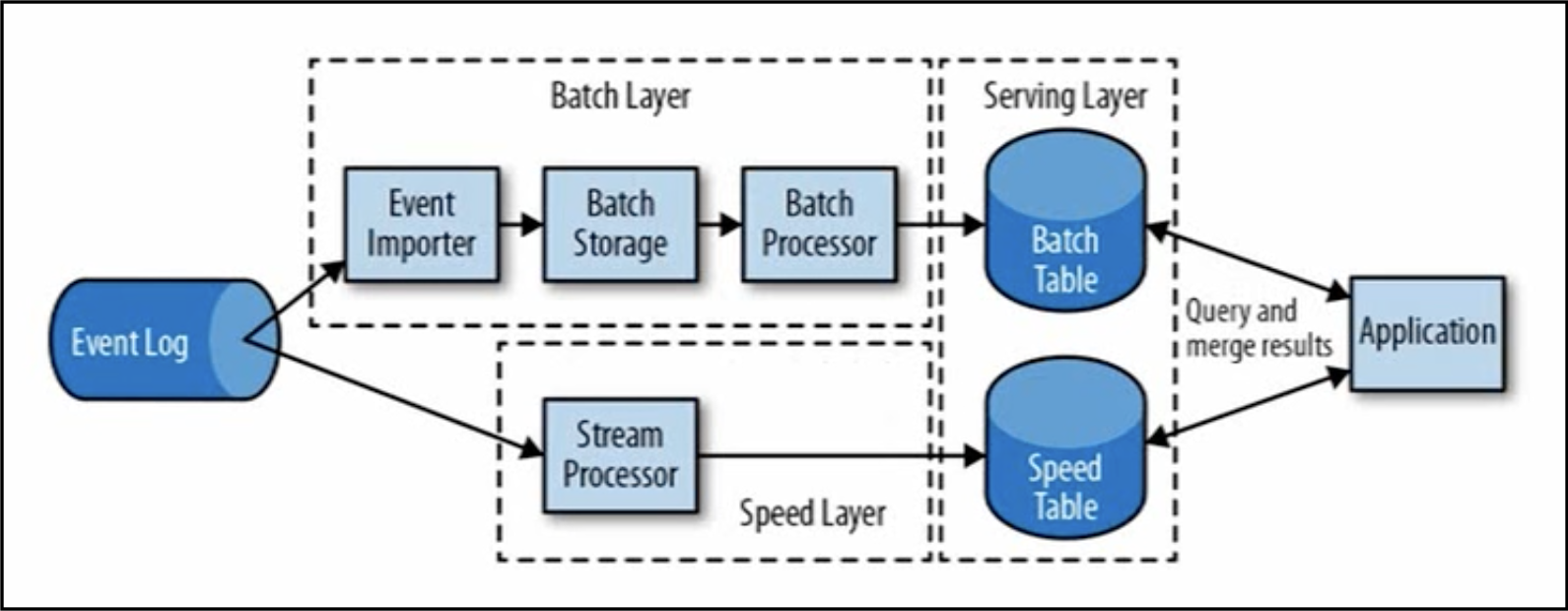
用两套系统(批处理和流处理),同时保证低延迟和结果顺序准确。流处理保证速度,批处理保证数据的准确。
lambda的框架的问题是:需要实现两套系统,代价高。
能解决lambda架构的问题的正是flink。
3.Flink的特点
flink的特点可归为以下几种:事件驱动、基于流的世界观。
3.1.事件驱动
事件驱动模型如下图所示:
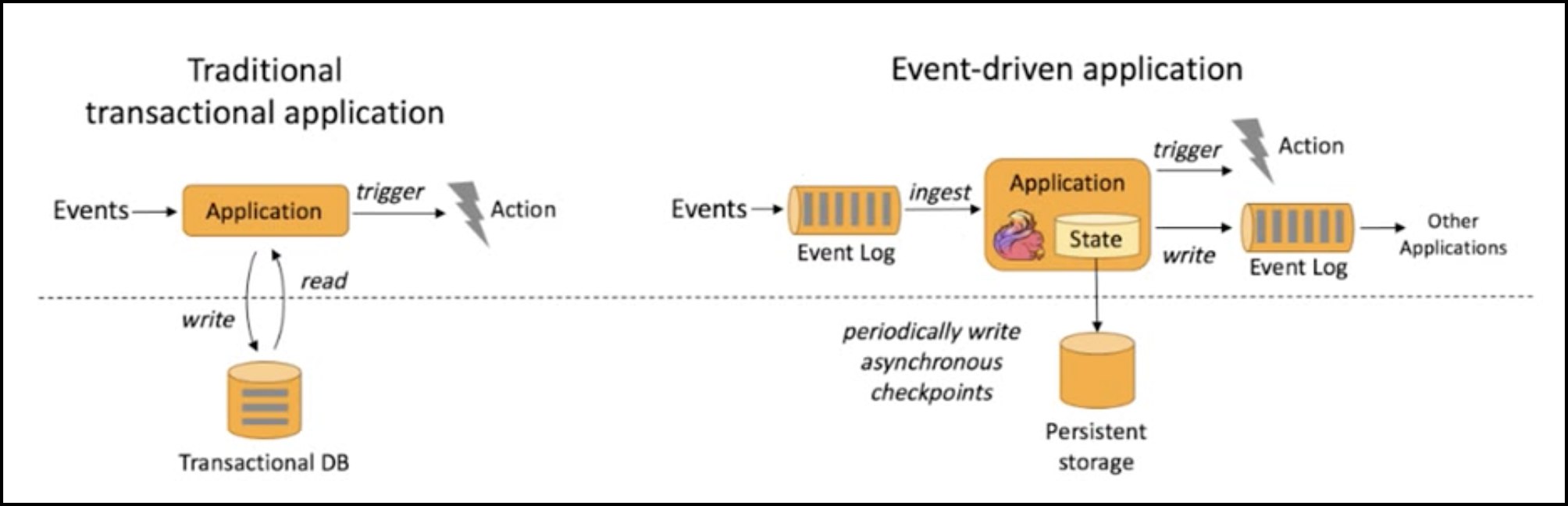
从模型上看,flink的处理方式与事务处理类似,只不过flink与本地状态交互,而不是数据库。
3.2.基于流的世界观
在flink的世界中,一切都是由流组成的:离线数据是有界的流(有界流),实时数据是一个没有界限的流(无界流)。流的分类解释如下图所示:
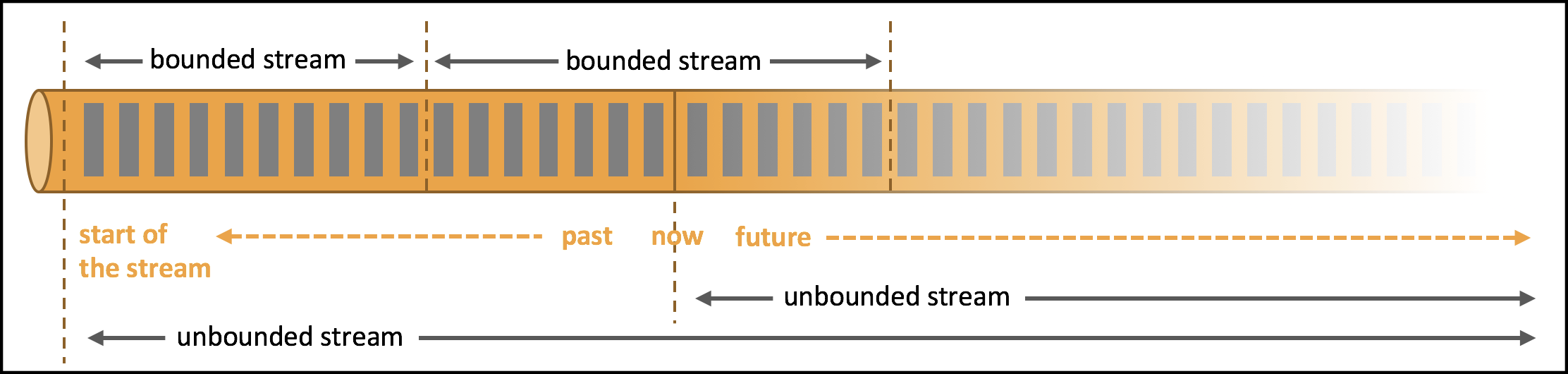
无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
精确的时间控制和状态化使得Flink在运行时能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
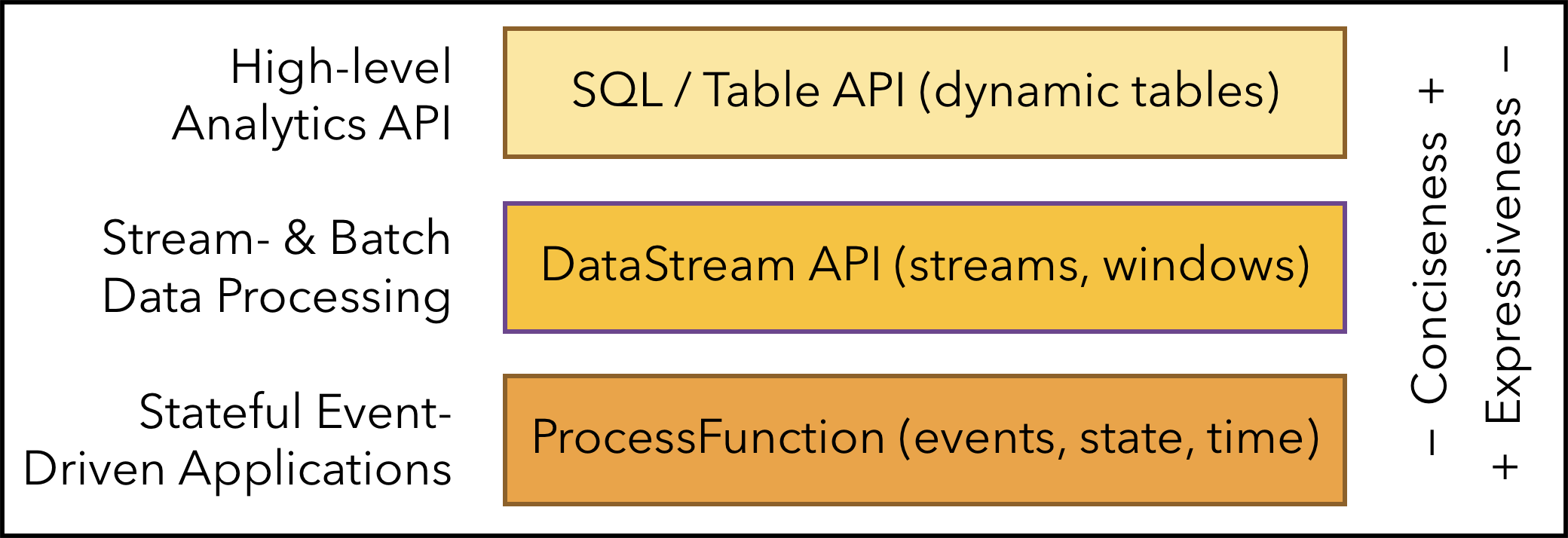
3.3.分层API
Flink根据抽象程度分层,提供了三种不同的API,如上图所示。每一种API在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。越顶层越抽象,表达含义越简明,使用越方便。越底层越具体,表达能力越丰富,使用越灵活。
3.4.其他特点
除上述特点外,Flink还有以下的几个特点:
(1)支持事件时间(event-time)和处理时间(processing-time)语义。
(2)精确一次(exactly-once)的状态一致性保证。
(3)低延迟、每秒处理数百万个事件,毫秒级延迟。
(4)与众多常用存储系统的链接。
(5)高可用,动态扩展,实现7*24小时全天候运行。
4.Flink与Spark Streaming对比
严格意义上讲,Flink是流式(strem)处理,而Spark Streaming是微批(micro-batching)处理。
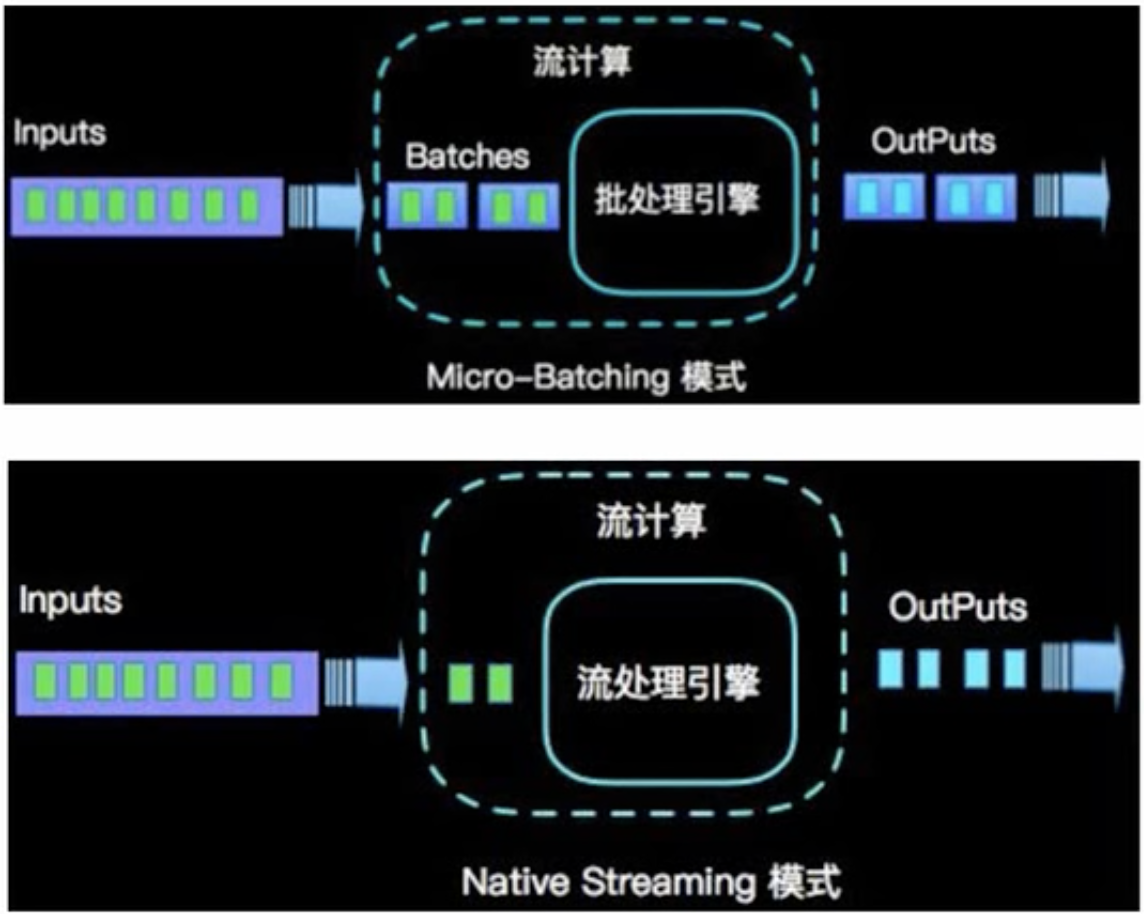
从数据模型上看:
spark采用RDD模型,spark streaming的DStream实际上也是一组组小批数据RDD的集合。
flink基本数据模型是数据流,以及事件(event)序列。
从运行时架构上看:
spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个。
flink是标准的流处理模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。