1.logback概述
logback是由log4j创始人设计的一个开源日志组件。
1.1.logback子模块
logback主要分为以下三个模块:
(1)logback-core:提供了LogBack的核心功能,是另外两个组件的基础。
(2)logback-classic:实现了Slf4j的API,所以当想配合Slf4j使用时,需要引入logback-classic。
(3)logback-access:为了集成Servlet环境而准备的,可提供HTTP-access的日志接口。
1.2.logback优点
相比其他日志框架,logback具备非常多优点。
1.2.1.更快的实现
Logback的内核重写了,在一些关键执行路径上性能提升10倍以上。而且logback不仅性能提升了,初始化内存加载也更小了。
1.2.2.非常充分的测试
Logback经过了几年,数不清小时的测试。Logback的测试完全不同级别的。在作者的观点,这是简单重要的原因选择logback而不是log4j。
1.2.3.Logback-classic非常自然实现了SLF4j
Logback-classic实现了SLF4j。在使用SLF4j中,你都感觉不到logback-classic。而且因为logback-classic非常自然地实现了SLF4J,所以切换到log4j或者其他,非常容易,只需要提供成另一个jar包就OK,根本不需要去动那些通过SLF4JAPI实现的代码。
1.2.4.非常充分的文档
官方网站有两百多页的文档。
1.2.5.自动重新加载配置文件
当配置文件修改了,Logback-classic能自动重新加载配置文件。扫描过程快且安全,它并不需要另外创建一个扫描线程。这个技术充分保证了应用程序能跑得很欢在JEE环境里面。
1.2.6.Lilith
Lilith是log事件的观察者,和log4j的chainsaw类似。而lilith还能处理大数量的log数据 。
1.2.7.谨慎的模式和非常友好的恢复
在谨慎模式下,多个FileAppender实例跑在多个JVM下,能够安全地写道同一个日志文件。RollingFileAppender会有些限制。Logback的FileAppender和它的子类包括 RollingFileAppender能够非常友好地从I/O异常中恢复。
1.2.8.配置文件可以处理不同的情况
开发人员经常需要判断不同的Logback配置文件在不同的环境下(开发,测试,生产)。而这些配置文件仅仅只有一些很小的不同,可以通过 <if>,<then>和<else>标签来实现,这样一个配置文件就可以适应多个环境。
1.2.9.Filters(过滤器)
有些时候,需要诊断一个问题,需要打出日志。在log4j,只有降低日志级别,不过这样会打出大量的日志,会影响应用性能。在Logback,你可以继续 保持那个日志级别而除掉某种特殊情况,如alice这个用户登录,她的日志将打在DEBUG级别而其他用户可以继续打在WARN级别。要实现这个功能只需 加4行XML配置。可以参考MDCFIlter 。
1.2.10.SiftingAppender
这是一个多功能的Appender,它可以用来分割日志文件根据任何一个给定的运行参数。如,SiftingAppender能够区别日志事件跟进用户的Session,然后每个用户会有一个日志文件。
1.2.11.历史日志压缩归档
RollingFileAppender在产生新文件的时候,会自动压缩已经打出来的日志文件。压缩是个异步过程,所以甚至对于大的日志文件,在压缩过程中应用不会受任何影响。
1.2.12.堆栈树带有包版本
Logback在打出堆栈树日志时,会带上包的数据。
1.2.13.日志滚动机制
通过设置TimeBasedRollingPolicy或者SizeAndTimeBasedFNATP的maxHistory属性,你可以控制已经产生日志文件的最大数量。如果设置maxHistory 12,那那些log文件超过12个月的都会被自动移除。
2.logback源码解析
源码解析分为以下三大块。
2.1.Logback日志打印流程
下面通过logger.info为例进行说明,整个过程函数调用链如下图所示:
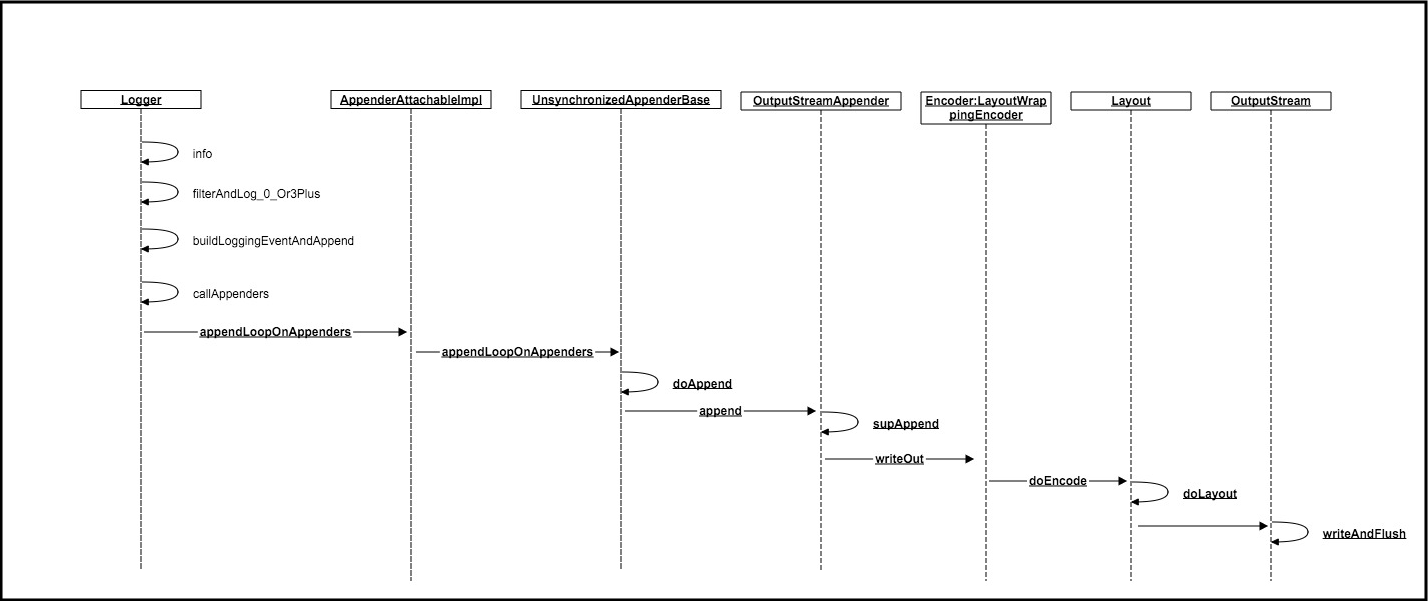
整个过程中起关键作用的几个类为:AppenderAttatchableImpl,OutputStreamAppender、Encoder、Layout、OutputStream。这几类和配置文件中相应元素一一对应。logback通过类的继承和组合层层封装方法,最后通过OutputStream写入到控制台(ConsoleAppender)或者是文件(FileAppender)中。
logback日志打印流程相关类图如下所示:
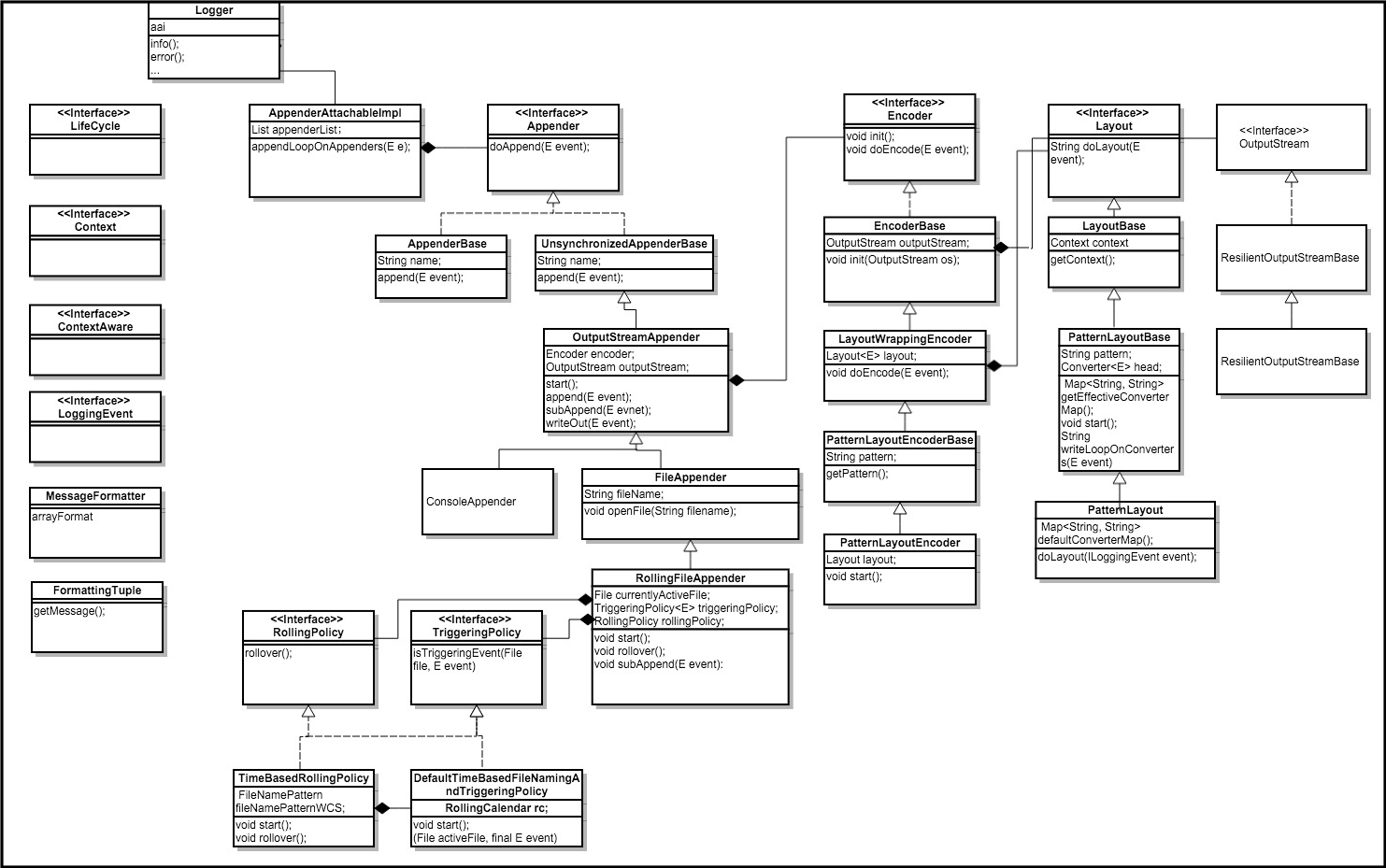
可以看出,Appender、Encoder、Layout、OutputStream是其中的核心,上图列出了我们经常使用的一些Appender,例如ConsoleAppender、RollingFileAppender;文件的滚动策略:TimeBasedRollingPolicy;格式化日志输出的PatternLayout,以及相应的pattern。
2.2.logback中logger匹配顺序
logger的匹配是根据名称进行匹配的,如下所示的logback的配置:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration scan="false" scanPeriod="60000" debug="false">
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern>
</layout>
</appender>
<logger name="java" additivity="false" />
<logger name="java.lang" level="warn">
<appender-ref ref="STDOUT" />
</logger>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
</configuration>对于LoggerFactory.getLogger(Object.class)获得的Logger,首先找到name=”java.lang”这个<logger>,将日志级别大于等于warn的使用”STDOUT”这个<appender>打印出来,name=”java.lang”这个<logger>没有配置additivity,那么additivity=true,打印信息向上传递,传递给父级name=”java”这个<logger>。name=”java”这个<logger>的additivity=false且不关联任何<appender>,那么name=”java”这个<appender>不会打印任何信息。
2.3.异步写日志
日志通常来说都是以文件形式记录到磁盘,例如使用<RollingFileAppender>,这样的话,每一次写日志就会发生一次磁盘IO,这对于性能是一种损耗,因此更多的,对于每次请求必打的日志(比如请求日志、记录请求API、参数、请求时间),我们会采取异步写日志的方式而不让此次写日志发生磁盘IO,阻塞现场从而造成不必要的性能损耗。这对整个QPS的性能有大幅提高。
下面是一个异步写日志的配置:
<appender name="ROLLING-FILE-1" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>D:/rolling-file-%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%-4relative [%thread] %-5level %lo{35} - %msg%n</pattern>
</encoder>
</appender>
<!-- 异步输出 -->
<appender name ="ASYNC" class= "ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>256</queueSize>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref ="ROLLING-FILE-1"/>
</appender>当我们配置了AsyncAppender,系统启动时会初始化一条名为"AsyncAppender-Worker-ASYNC"的线程。
当Logging Event进入AsyncAppender后,AsyncAppender会调用appender方法,appender方法中再将event填入Buffer(使用的Buffer为BlockingQueue,具体实现为ArrayBlockingQueye)前,会先判断当前Buffer的容量以及丢弃日志特性是否开启,当消费能力不如生产能力时,AsyncAppender会将超出Buffer容量的Logging Event的级别进行丢弃,作为消费速度一旦跟不上生产速度导致Buffer溢出处理的一种方式。
上面的线程的作用,就是从Buffer中取出Event,交给对应的appender进行后面的日志推送。
从上面的描述我们可以看出,AsyncAppender并不处理日志,只是将日志缓冲到一个BlockingQueue里面去,并在内部创建一个工作线程从队列头部获取日志,之后将获取的日志循环记录到附加的其他appender上去,从而达到不阻塞主线程的效果。因此AsyncAppender仅仅充当的是事件转发器,必须引用另外一个appender来做事。
配置AsyncAppender有以下四个重要的参数:
(1)discardingThreshold:假如等于20则表示,表示当还剩20%容量时,将丢弃TRACE、DEBUG、INFO级别的Event,只保留WARN与ERROR级别的Event,为了保留所有的events,可以将这个值设置为0,默认值为queueSize/5。
(2)queueSize:BlockingQueue的最大容量,默认为256。
(3)includeCallerData:表示是否提取调用者数据,这个值被设置为true的代价是相当昂贵的,为了提升性能,默认当event被加入BlockingQueue时,event关联的调用者数据不会被提取,只有线程名这些比较简单的数据。
(4)appender-ref:表示AsyncAppender使用哪个具体的<appender>进行日志输出。