Iceberg在设计之初就是独立于任何引擎,它设计了一套自己的Catalog与schema,方便后续不依赖任何引擎的独立更新迭代。
Iceberg insert写流程
Iceberg insert写数据如下图所示:
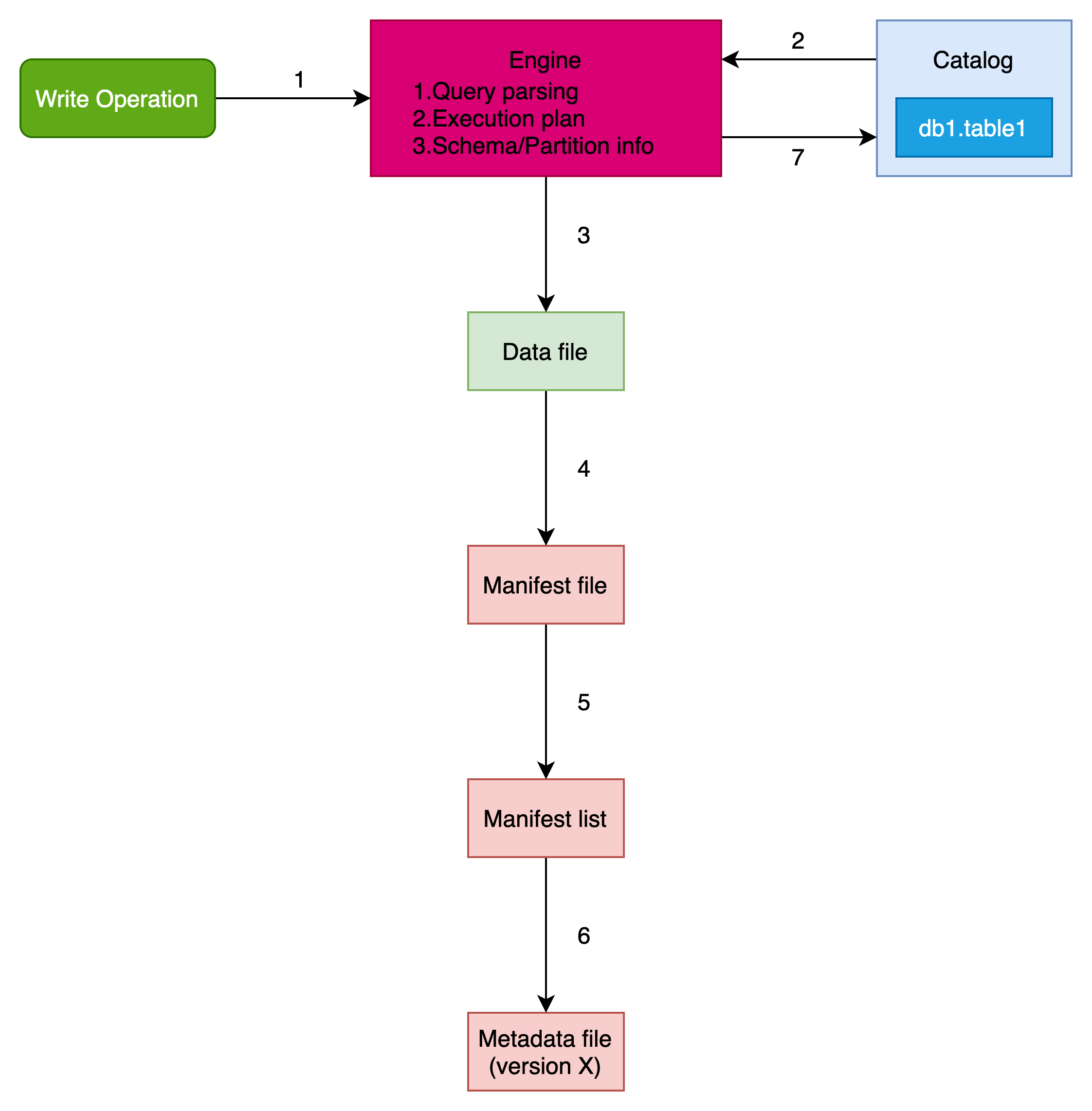
分为以下几个过程
引擎的解析与执行(1)
Iceberg定位只是一个表格式,数据的写入都是依赖于引擎。写数据操作首先会被引擎进行解析构图,生成执行计划。
读取元数据(2)
Iceberg的入口就是其Catalog,在写入时,执行引擎向Catalog发出请求以确定当前元数据文件的位置,然后读取它。
引擎读取元数据文件是为了:
(1)了解表的模式(v1, v2等架构)和数据结构
(2)了解表的分区方案,以便在写入时相应地组织数据
此时,表的元数据结构如下图所示:
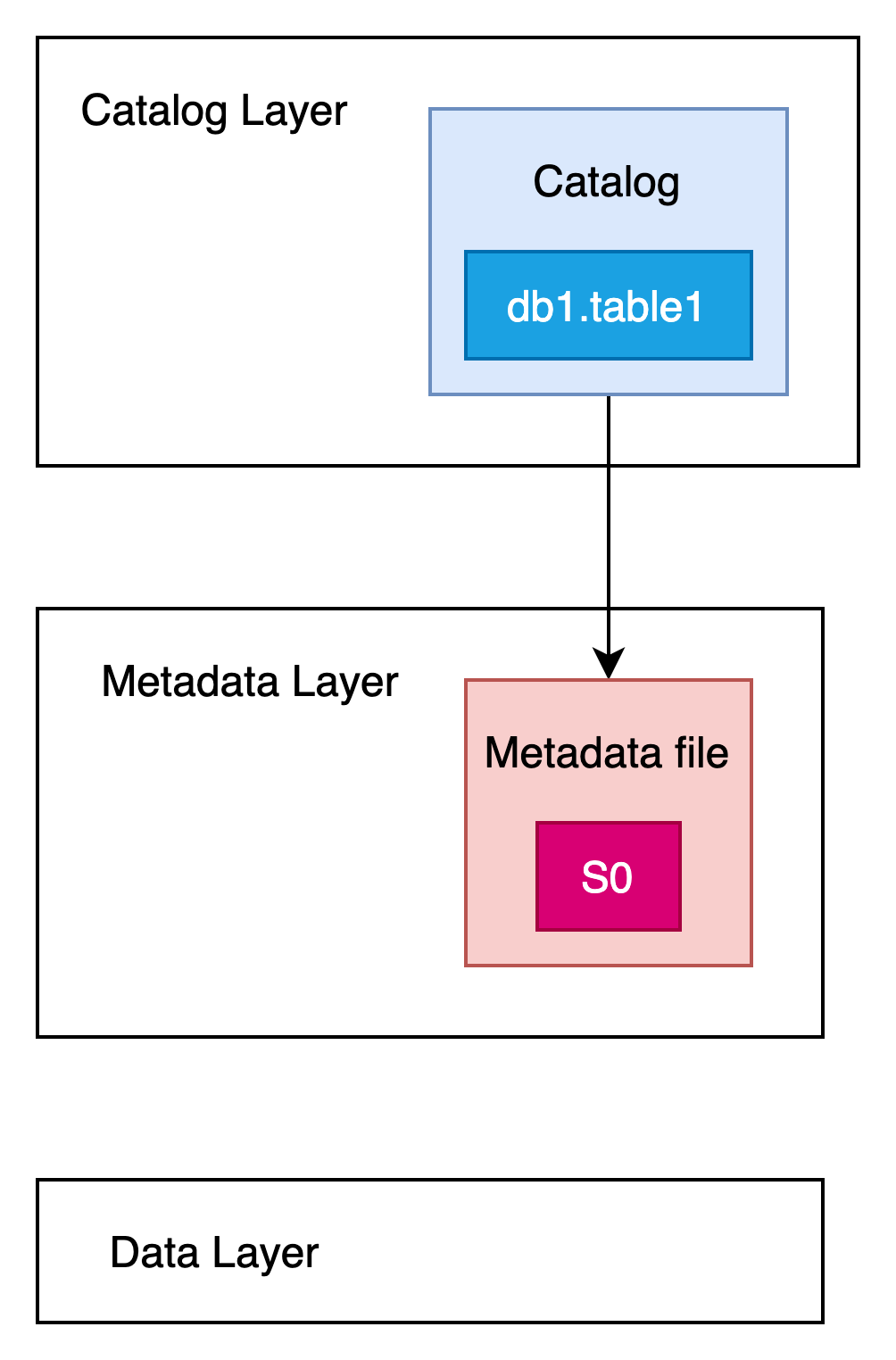
此时表db1.table1的最新快照版本为s0
写入数据文件(3)
首先,引擎根据表的分区定义方案方案将数据写入 Parquet 数据文件。
此外,如果为表定义了排序顺序,则数据将在写入数据文件之前进行排序。
创建新的快照(4~6)
创建新的快照就是创建元数据的过程。
创建manifest文件(4)
在写入数据文件后,引擎会创建一个清单文件。
该清单文件提供了有关引擎创建的实际数据文件的路径的信息和统计信息。统计信息包括有:列的上下界、空值计数等,这非常有利于查询引擎修剪文件并提供最佳性能。
需要注意的是,引擎在处理要写入的数据时统计这些信息,这是一个相对轻量级的操作。最终,清单文件将作为 .avro 文件写入存储系统中。
创建manifestlist文件(5)
接下来,引擎创建一个清单列表来跟踪清单文件。
如果现有清单文件与当前快照有关联的,那么这些文件也将被添加到这个新的清单列表中。
然后引擎会将此文件写入数据湖中,其中包含清单文件的路径、添加或删除的数据文件/行数以及有关分区的统计信息(例如分区列的下限和上限)等信息。
同样,引擎已经拥有所有这些信息,因此获取这些统计数据是一项轻量级操作。此信息有助于读取查询排除任何不需要的清单文件,从而促进更快的查询。
创建元数据文件(6)
最后,引擎通过现有元数据文件xxx1.metadata.json跟踪到先前的快照 s0。然后将s0和当前创建的新快照s1作为一部分创建新的元数据文件 xxx2.metadata.json ,同时跟踪s0,s1。
这个新的元数据文件包含有关引擎创建的清单列表的信息,其中包含清单列表文件路径、快照 ID、操作摘要等详细信息。此外,引擎还将引用当前的清单列表(或快照)。
执行commit(7)
最后,引擎再次访问Catalog,以确保运行此 INSERT 操作时没有提交其他快照。
通过进行此验证,Iceberg 保证在多个写入者同时写入数据的场景中不会干扰操作。Iceberg 确保第一个写入数据的人将首先提交,任何冲突的写入操作将返回到之前的步骤并重新尝试,直到写入成功或失败。
最后,引擎自动更新Catalog以引用新的元数据xxx2.metadata.json,该元数据现在成为当前的元数据文件。
commit完成后,表的元数据视图如下图所示:
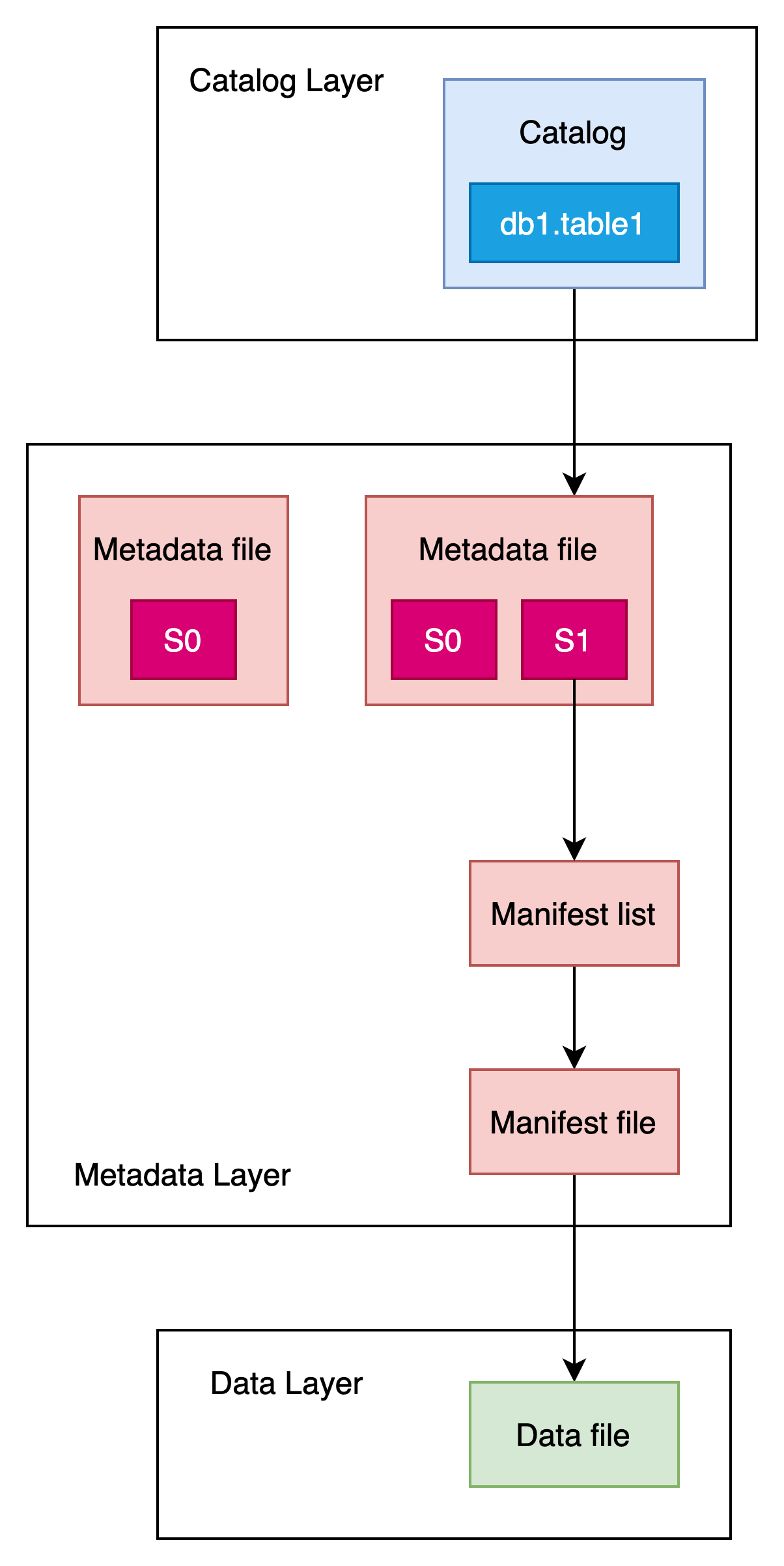
此时表db1.table1的最新快照版本为s1
iceberg COW表UPSERT/MERGE INTO更新流程
本质上讲数据湖并没有提供update的能力,它实际上就是通过Join来实现的数据更新。
下面我们通过Spark SQL,执行MERGE INTO数据更新操作,实现以下场景:当想要更新现有行(如果表中存在特定值)时,通常会运行此类查询,如果不存在,则只需插入新行。
# Spark SQL
MERGE INTO table1 t1
USING (SELECT * FROM table1_tmp) tmp
ON t1.id = tmp.id
WHEN MATCHED THEN UPDATE SET amount = tmp.amount
WHEN NOT MATCHED THEN INSERT *;假设有一个临时表table1_tmp,它由两条记录组成:一条记录对现有id(id=100)进行了更新,另一条记录是全新的行数据(id=200)。
我们希望将table1_tmp表中的数据合并到table1中,即将table1_tmp表“id=100”的数据更新到table1中,将table1_tmp表“id=200”的数据插入到table1中。
MERGE INTO执行过程如下
引擎的解析与执行
客户端向Spark引擎发送SQL,引擎会进行解析查询计划。由于涉及两个表(table1_tmp和table1),引擎需要两个表的数据来开始查询计划。
读取元数据
与 INSERT 操作类似,引擎首先向Catalog发出请求以确定当前元数据文件位置,然后读取它。
引擎读取到元数据文件,查看表的当前模式与分区信息,以便写入操作可以遵循表格式规范。
写入数据文件
首先,查询引擎将从table1_tmp和table1中读取数据并将其加载到内存中,以确定匹配的数据记录。
当引擎确定匹配时,内存中跟踪的数据内容将基于 Iceberg 表属性定义的两种策略(写入时复制COW或读取时合并MOR)进行写出。
COW写时复制策略,每当更新 Iceberg 表时,任何具有相关记录的关联数据文件都将被重写为新数据文件。
MOR读时合并策略,数据文件不会被重写;相反,将生成新的删除文件来跟踪更改。
生成元数据文件
写入数据文件后,引擎会创建一个新的清单文件,其中包含对这两个数据文件的文件路径的引用。此外,清单文件中还包含有关这些数据文件的各种统计信息。
然后,引擎生成一个新的清单列表,该列表指向上一步中创建的清单文件。和插入类似,清单列表还包括分区统计信息、添加和删除文件的数量等信息。
之后,引擎将通过当前元数据文件xxx2.metadata.json和跟踪到其快照s0与s1,以及新快照 s2 ,并为他们创建新元数据文件xxx3.metadata.json。
执行commit
最后,引擎此时运行检查以确保不存在写入冲突,如存在冲突,则重写。检测到不存在冲突后,使用最新元数据文件的值,即xxx3.metadata.json。
整体的Merge Into执行后,表组织结构视图如下:
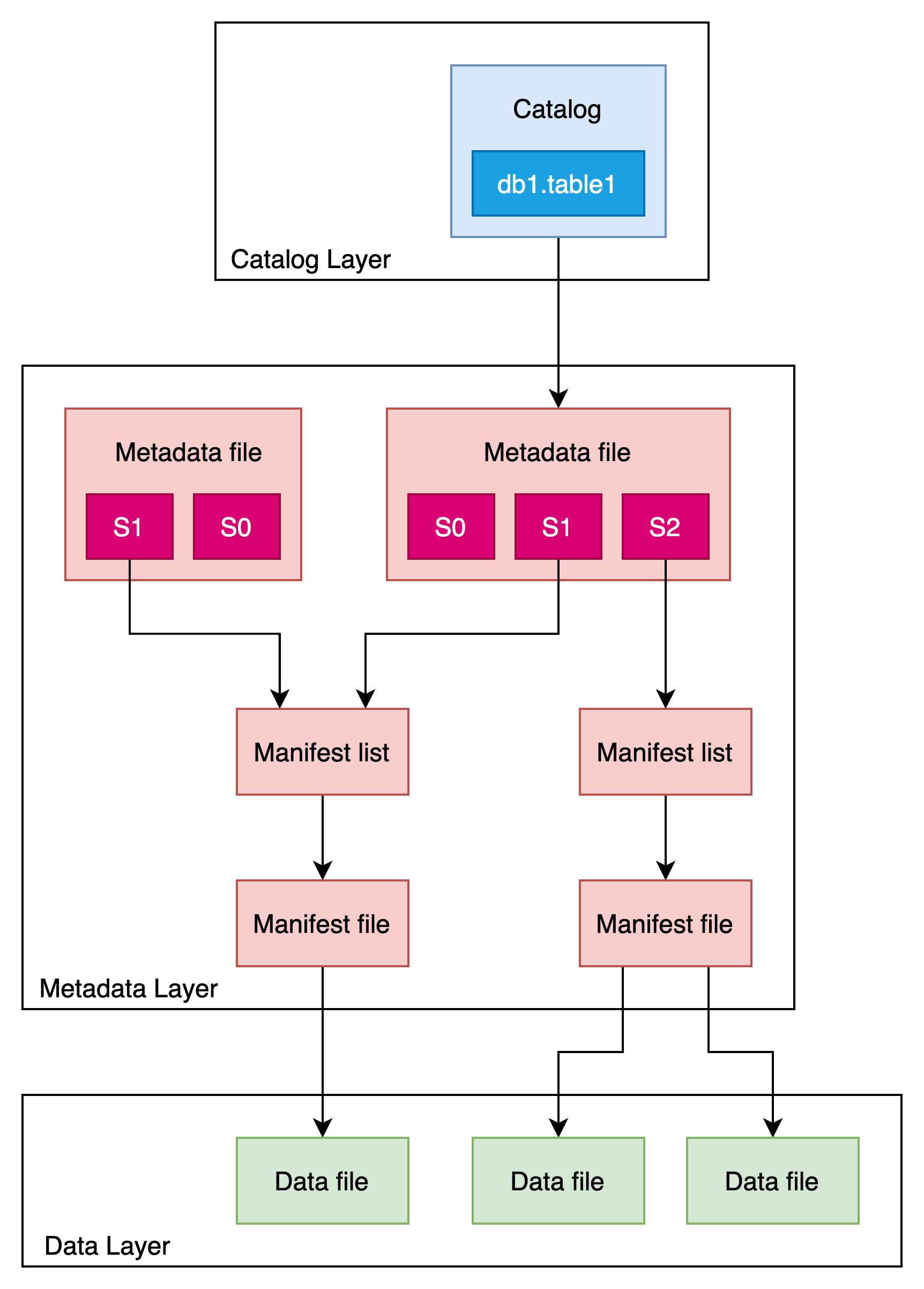
对于COW表,S2中存在两个Data file,一个是对S1 Data file的重写,一个是insert数据生成的Data file。
Iceberg MOR表更新
MOR就是在写入时只写入要更新的数据,在读取时通过Join将文件进行合并读取(也可在写入后的后台线程进行文件合并),拿到更新后的数据。
每次 Iceberg 的写操作,只有发生 commit 之后,才是可读的;如有多个线程同时在读,但一部分线程在写,可以实现:只有 commit 完整的数据之后,对用户的读操作才能被用户的读线程所看到,实现读写分离。
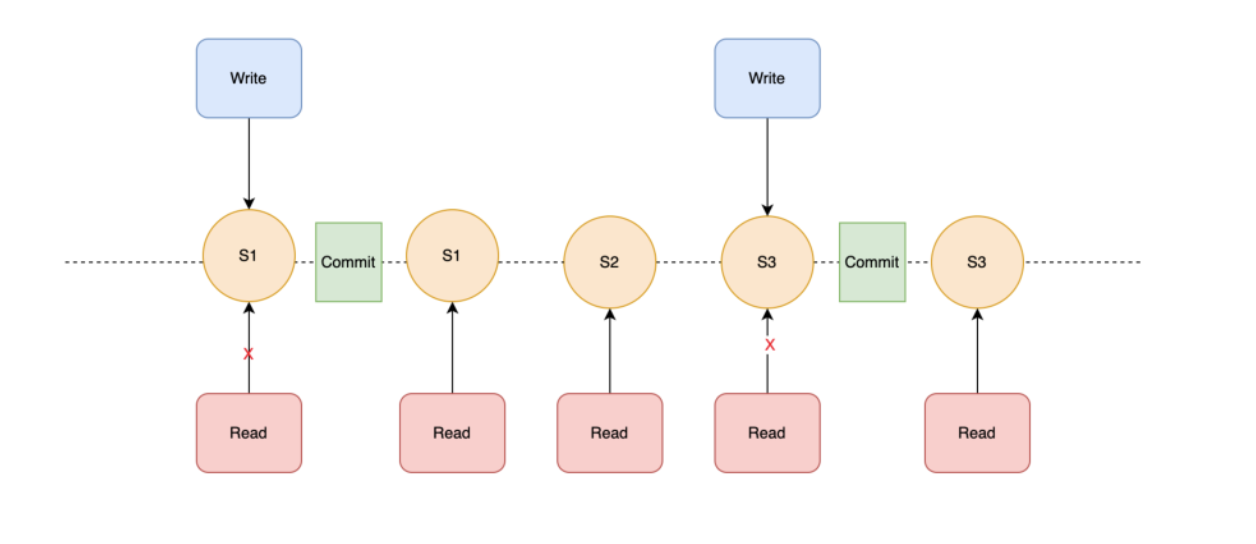
例如上图中,在对 S3 进行写操作的时候,S2、S1 的读操作是不受影响的;此时 S3 无法被读到,只有 commit 之后 S3 才会被读到。此时 Current Snapshot 会指向 S3。
Iceberg 默认从最新 Current Snapshot 读取数据;如果读更早的数据,可指定对应的Snapshot 的 id ,实现数据回溯。
事务性提交
写操作:记录当前元数据的版本——base version,创建新的元数据以及 manifest 文件,原子性将 base version 替换为新的版本。
原子性替换:原子性替换保证了线性历史,通过元数据管理器所提供的能力,以及 HDFS 或本地文件系统所提供的原子化 rename 能力实现。
冲突解决:基于乐观锁实现,每一个 writer 假定当前没有其他的写操作,对表的 write 进行原子性的 commit,若遇到冲突则基于当前最新的元数据进行重试。
分区裁剪
直接定位到 parquet 文件,无需调用文件系统的 list 操作。
Partition 的存储方式对用户透明,用户在修改 partition 定义时,Iceberg 可以自动地修改存储布局,无需用户重复操作。
谓词下推
Iceberg 会在两个层面实现谓词下推:
在 snapshot 层面,过滤掉不满足条件的 data file。
在 data file 层面,过滤掉不满足条件的数据。
其中,snapshot 层面的过滤操作为 Iceberg 所特有,正是利用到 manifest 文件中的元数据信息,逐字段实现文件的筛选,大大地减少了文件的扫描量。而同为 Table Format 产品、在字节其他业务产线已投入使用的 Hudi,虽然同样具备分区剪枝功能,但是尚不具备谓词下推功能。