1.布隆过滤器定义
布隆过滤器是一种空间效率高和时间效率高的概率型数据结构,用于判断某个元素是否在一个集合中。
它通过多个哈希函数将元素映射到一个位数组中,虽然能快速判断元素是否存在,但有一定的误判率,即可能会误认为元素存在,但不会漏掉实际存在的元素。
简而言之布隆过滤器确实是一个很长的二进制向量(位数组)和一系列哈希函数的组合。
2.布隆过滤器操作
当一个元素被添加到集合中时,它会通过m个哈希函数映射到位数组中的m个位置,并将这些位置的值设置为 1。
在检查元素是否在集合中时,检查这些位置是否全为 1。
如果其中有任何一个位置为 0,则该元素一定不在集合中;如果所有位置均为 1,则该元素可能在集合中。
3.布隆过滤器案例
如下图所示
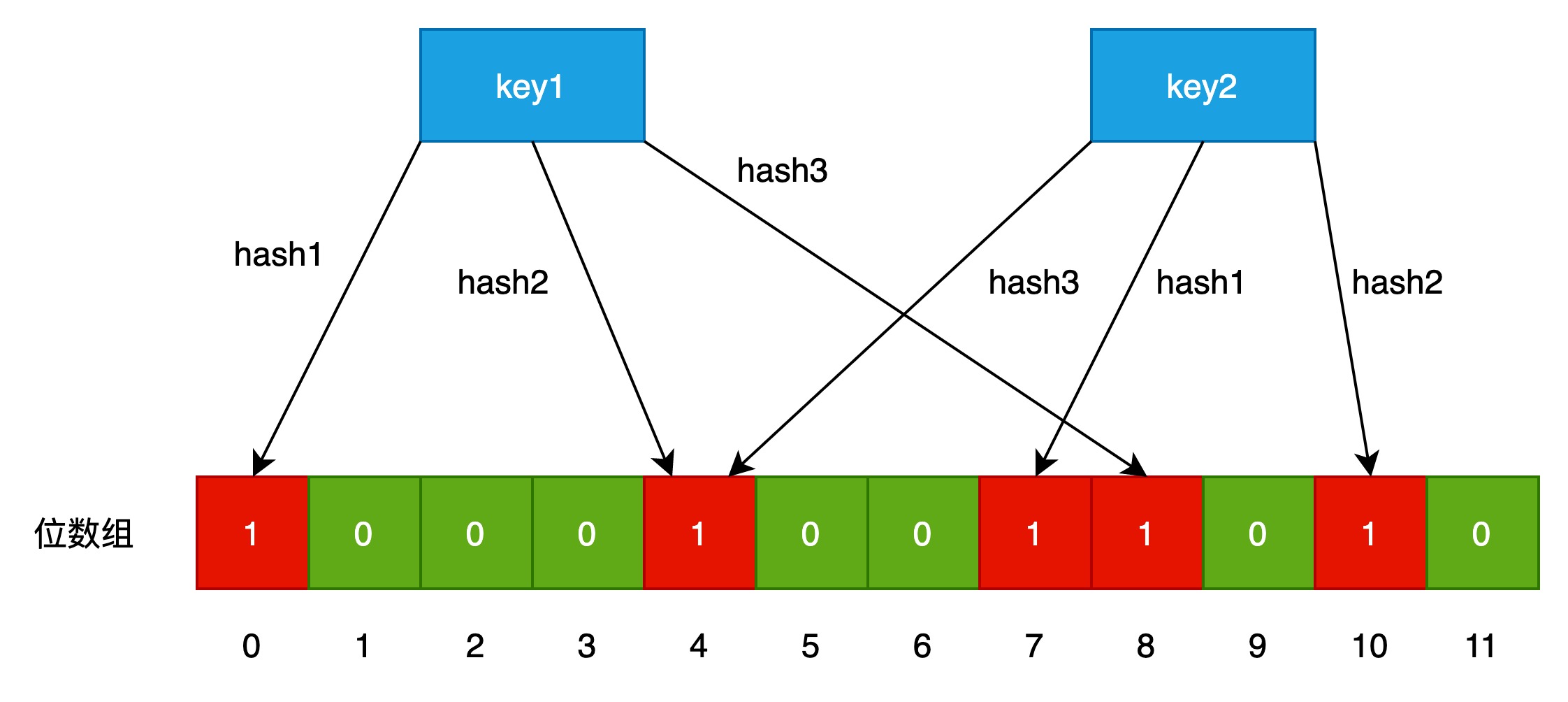
布隆过滤器有3个hash函数,位数组是12位的。
对key1进行过滤后,key1在三个hash函数的映射下,对应key1--->(0, 4, 8)。
对key2进行过滤后,key2在三个hash函数的映射下,对应key1--->(7, 10, 4)。
如过新增一个key3,在三个hash函数映射下的数组位不全是1,那就可以判断key3在布隆过滤器中是不存在的。
可以看到4号位是有重叠的,正是这种重叠的特性,导致布隆过滤器是可能存在误判的,通俗点说就是假阳性。重叠性也布隆过滤器不支持删除操作的原因。
3.1.布隆过滤器的缺点
其实就是,存在一定误判。
如果要降低误判率的话,有以下方法:
(1)增加位数组的大小:增大位数组的长度可以减少每个位的填充率,从而降低假阳性率。较大的位数组可以容纳更多的元素,并且哈希值的碰撞几率减少。
(2)增加哈希函数的数量:使用更多的哈希函数可以进一步分散哈希映射,降低假阳性率。
(3)使用分级布隆过滤器:在布隆过滤器前使用一个较小的布隆过滤器作为初步过滤器,只有在初步过滤器确认元素可能存在时,才使用主要布隆过滤器,这可以减少对主要布隆过滤器的查询次数。
有人发布过paper,论证过最低误判率下二进制向量的大小。
K为哈希次数,N为元素个数,则设计K*N*ln2的二进制位数的布隆过滤器可以保证最佳的误判率。
3.2.布隆过滤器的优点
优点也很明确,它的空间效率和查询效率极佳。
4.布隆过滤器适用场景
在消息量大、内存空间有限的情况下,使用布隆过滤器是个很不错的选择。
有以下几个经典的场景。
4.1.缓存穿透保护
在分布式缓存系统中,布隆过滤器可以用来防止缓存穿透。通过在缓存前面加一个布隆过滤器,可以有效地阻止不存在的数据请求直接到达后端数据库,从而减少数据库负载和提高系统性能。
4.2.检测恶意网址
通过将已知的恶意网址存储在布隆过滤器中,可以快速判断一个网址是否可能是恶意的。
4.3.防止消息重复消费
布隆过滤器还可以用于防止MQ消息重复消费。比如说,我们在发送消息时可以对每个消息设置唯一的key,在消费者消费处理时,利用布隆过滤器对消息的key检索。如果不存在则进行消费,然后插入布隆过滤器,如果存在则说明消息已经消费过。