Iceberg Catalog简介
所谓Catalog即数据目录,简单讲,Catalog是企业用于管理数据资产的方式,Catalog借助元数据来管理数据,包括数据收集、组织、访问、发现和治理。Catalog在数据资产管理中处于核心位置。
Iceberg Catalog的作用
Catalog的核心作用是将表名映射到其当前表元数据文件的位置。
Iceberg Catalog提供了基本的表创建、表替换、表删除、表改名和表加载、查询等操作。在对外接口参数中,Iceberg使用TableIdentifier来标识一个表,TableIdentifier内部又包含一个Namespace。
在Iceberg中,一个表的完整标识组成为: TableIdentifier=Namespace+table,其中Namespace是一个字符串数组,支持多层级的表修饰,第0层为table,第1层为database。
Iceberg Catalog的分类
Catalog的类结构如下图所示:
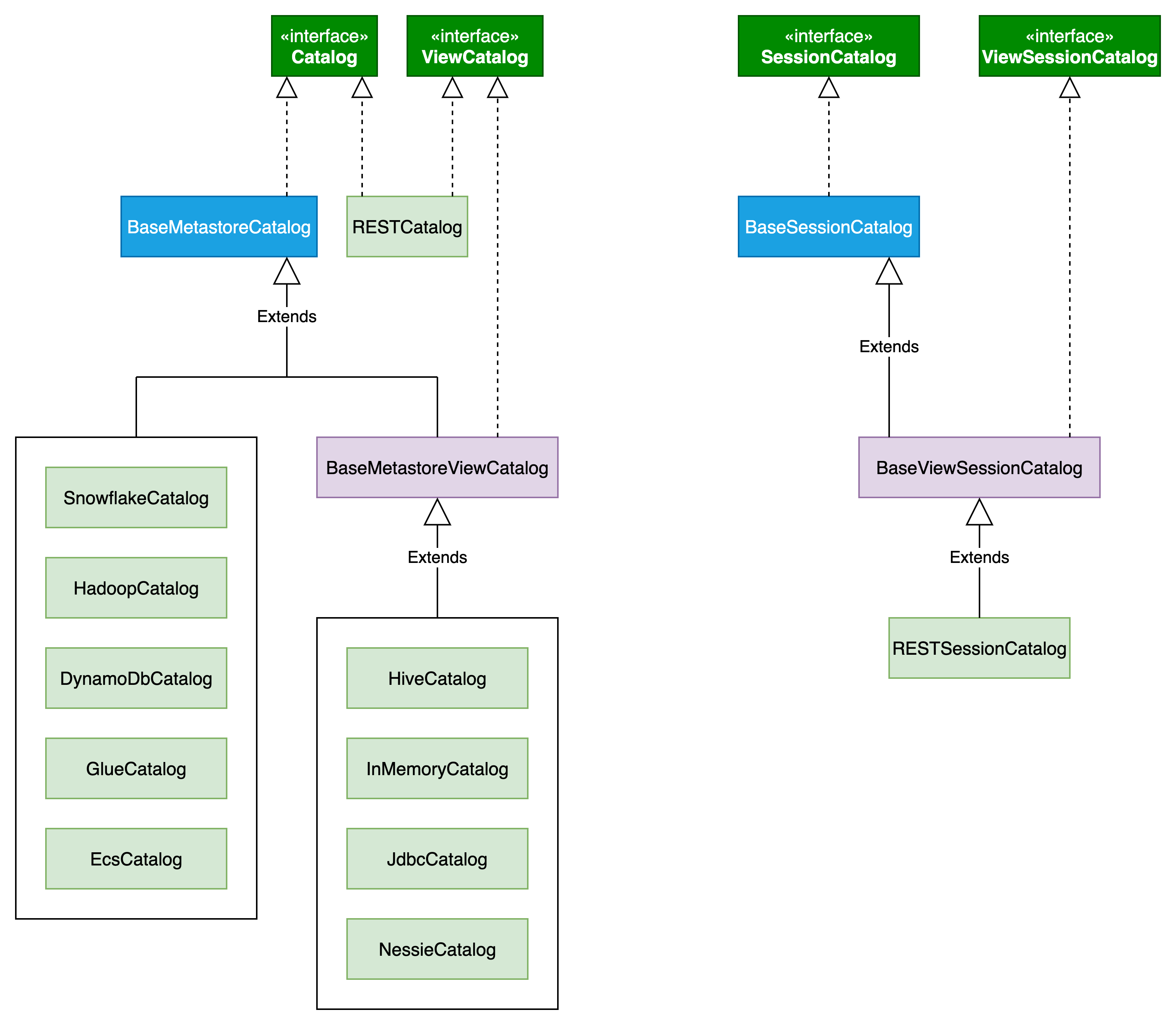
共有两种大类:Catalog和SessionCatalog。其中Catalog用于,
Iceberg Catalog抽象
org.apache.iceberg.catalog.Catalog是Iceberg Catalog的抽象类,接口定义如下:
package org.apache.iceberg.catalog;
public interface Catalog {
// 获取catalog的名称
default String name() {
return toString();
}
// 列举namespace下所有表
List<TableIdentifier> listTables(Namespace namespace);
// 创建一张表
default Table createTable(
TableIdentifier identifier,
Schema schema,
PartitionSpec spec,
String location,
Map<String, String> properties) {
return buildTable(identifier, schema)
.withPartitionSpec(spec)
.withLocation(location)
.withProperties(properties)
.create();
}
// 创建一张非分区表
default Table createTable(TableIdentifier identifier, Schema schema) {
return createTable(identifier, schema, PartitionSpec.unpartitioned(), null, null);
}
// 开启事务,用于create一张表。当表存在时,抛AlreadyExistsException异常
default Transaction newCreateTableTransaction(
TableIdentifier identifier,
Schema schema,
PartitionSpec spec,
String location,
Map<String, String> properties) {
return buildTable(identifier, schema)
.withPartitionSpec(spec)
.withLocation(location)
.withProperties(properties)
.createTransaction();
}
// 开启事务,用于replace一张表。orCreate表示是否当表不存在时创建一张表
default Transaction newReplaceTableTransaction(
TableIdentifier identifier,
Schema schema,
PartitionSpec spec,
String location,
Map<String, String> properties,
boolean orCreate) {
TableBuilder tableBuilder =
buildTable(identifier, schema)
.withPartitionSpec(spec)
.withLocation(location)
.withProperties(properties);
if (orCreate) {
return tableBuilder.createOrReplaceTransaction();
} else {
return tableBuilder.replaceTransaction();
}
}
// 检查表是否存在
default boolean tableExists(TableIdentifier identifier) {
try {
loadTable(identifier);
return true;
} catch (NoSuchTableException e) {
return false;
}
}
// 删除一张表,删除所有的数据和元数据
default boolean dropTable(TableIdentifier identifier) {
return dropTable(identifier, true /* drop data and metadata files */);
}
// 删除一张表,可选择性删除数据和元数据。purge为true,则删除所有的数据和元数据;purge为false,则不删除数据,只删除元数据
boolean dropTable(TableIdentifier identifier, boolean purge);
// 重命名一张表
void renameTable(TableIdentifier from, TableIdentifier to);
// 加载一张表
Table loadTable(TableIdentifier identifier);
// 使当前catalog相关的表元数据缓存失效
default void invalidateTable(TableIdentifier identifier) {}
// catalog中,如果表不存在则注册表,表存在则抛AlreadyExistsException异常
default Table registerTable(TableIdentifier identifier, String metadataFileLocation) {
throw new UnsupportedOperationException("Registering tables is not supported");
}
// 初始化一个建表builder
default TableBuilder buildTable(TableIdentifier identifier, Schema schema) {
throw new UnsupportedOperationException(
this.getClass().getName() + " does not implement buildTable");
}
// 根据给定的自定义名称和一系列catalog属性初始化一个catalog实例
default void initialize(String name, Map<String, String> properties) {}
// 建表接口
interface TableBuilder {
// 为表设置分区
TableBuilder withPartitionSpec(PartitionSpec spec);
// 为表设置一个排序规则
TableBuilder withSortOrder(SortOrder sortOrder);
// 为表设置path location
TableBuilder withLocation(String location);
// 给表添加一个或多个属性
TableBuilder withProperties(Map<String, String> properties);
// 给表添加一个属性
TableBuilder withProperty(String key, String value);
// 建表
Table create();
// 启动事务用于create表
Transaction createTransaction();
// 启动事务用于replace表
Transaction replaceTransaction();
// 启动事务用于create或replace表
Transaction createOrReplaceTransaction();
}
}主要是表生命周期管理,包括表的创建、删除、更新、重命名和加载等操作。
Iceberg Catalog的实现
Iceberg-1.9.x提供了10种不同的catalog。
HiveCatalog
HiveCatalog将表的元数据信息存储在Hive Metastore,使用HiveMetastore中表的location属性作为表的路径。为了兼容HMS,Namespace必须包含table和database。
HiveCatalog优缺点
优点如下:
(1)应用广泛,被多种引擎和工具支持,不依赖云厂商。
缺点如下:
(1)需要部署和维护额外的Hive Metastore服务
(2)不支持涉及多表操作的一致性和原子性
HiveCatalog源码解析
HiveCatalog类结构如下图所示:
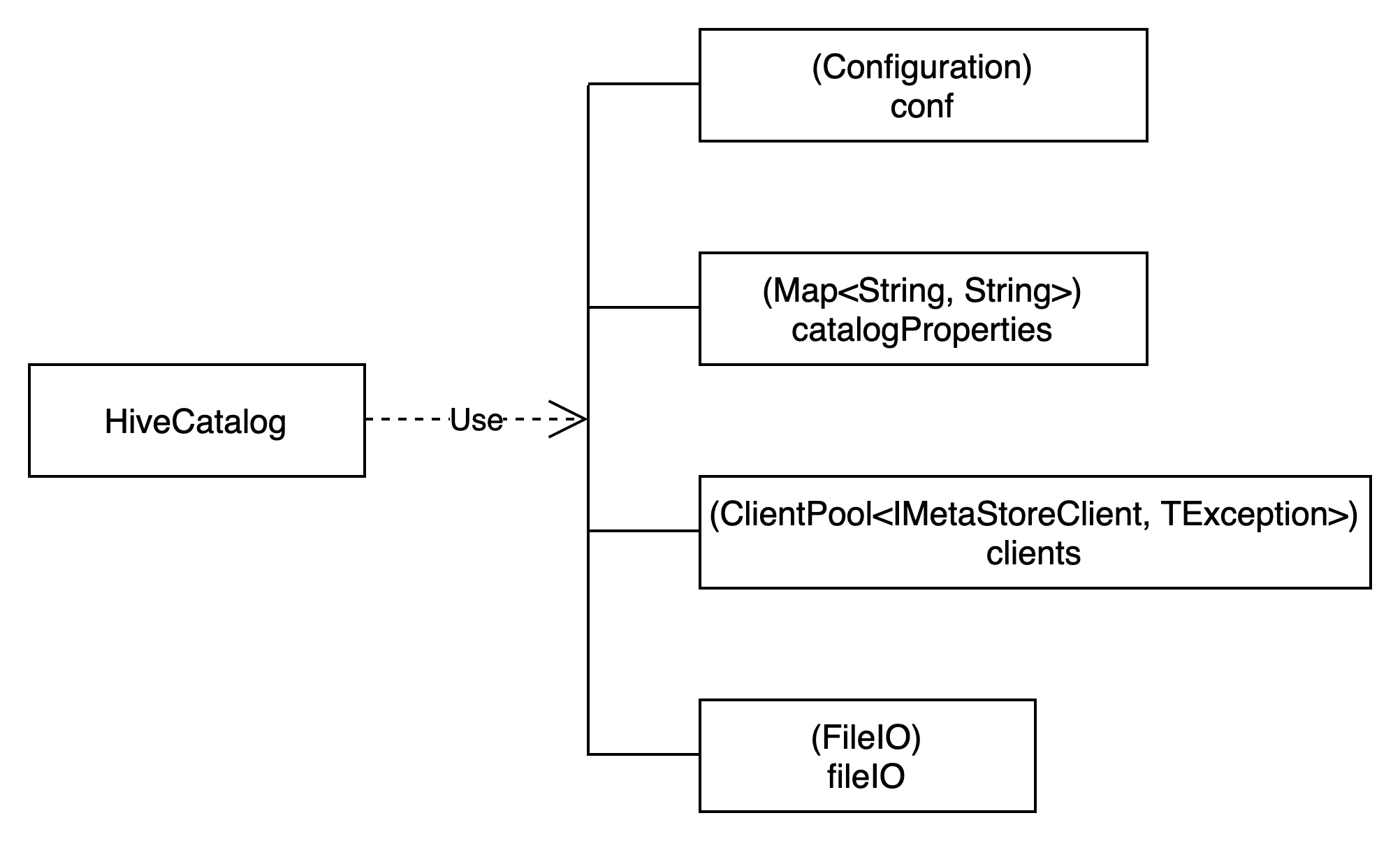
IMetaStoreClient全限定名为org.apache.hadoop.hive.metastore.IMetaStoreClient,是hive-metastore-{version}.jar包为访问hive metastore提供的客户端thrift api。
HadoopCatalog
HadoopCatalog将表的元数据信息存储在Hadoop之上,因为Hadoop支持存算分离,因此底层的数据文件可以是HDFS或者是S3这样的对象系统,对HadoopCatalog来讲,定位一个表的位置,只需要提供表的路径即可,因为表的元信息都存储在文件中,比如TableIdentifier为["my_table", "my_db", "my_nm1", "my_nm2"]的表全路径为:
[hdfs|s3]://data/my_db/my_nm1/my_nm2/my_table
对HadoopCatalog来讲,Namespace可以只有一层,即table 名称即可,它并不关心数据库的概念,只关心表的位置,但在实际应用中,为了规范管理表,建议使用规范的组织方式,具体如何组织,要看企业的行为习惯,目前没有最佳实践。
HadoopCatalog优缺点
优点如下:
(1)HadoopCatalog 是最简单的,不依赖外部系统。可以使用任意文件系统,包括 HDFS、S3等。
缺点如下:
(1)有些文件系统rename 操作是原子的,有些不是。像S3的rename 就不是原子的。
(2)仅使用数据仓库目录来列出表。如果使用对象存储,仅能使用一个 bucket。
(3)如果列出 namespaces(也就是 databases)或者 tables,当 namespaces 或者 tables 的数量比较多时,可能遇到性能问题。
(4)不能仅从 catalog删除一个表但是保留数据。
基于以上缺点,HadoopCatalog不推荐使用在生产环境。
HadoopCatalog源码解析
HadoopCatalog类结构如下图所示:
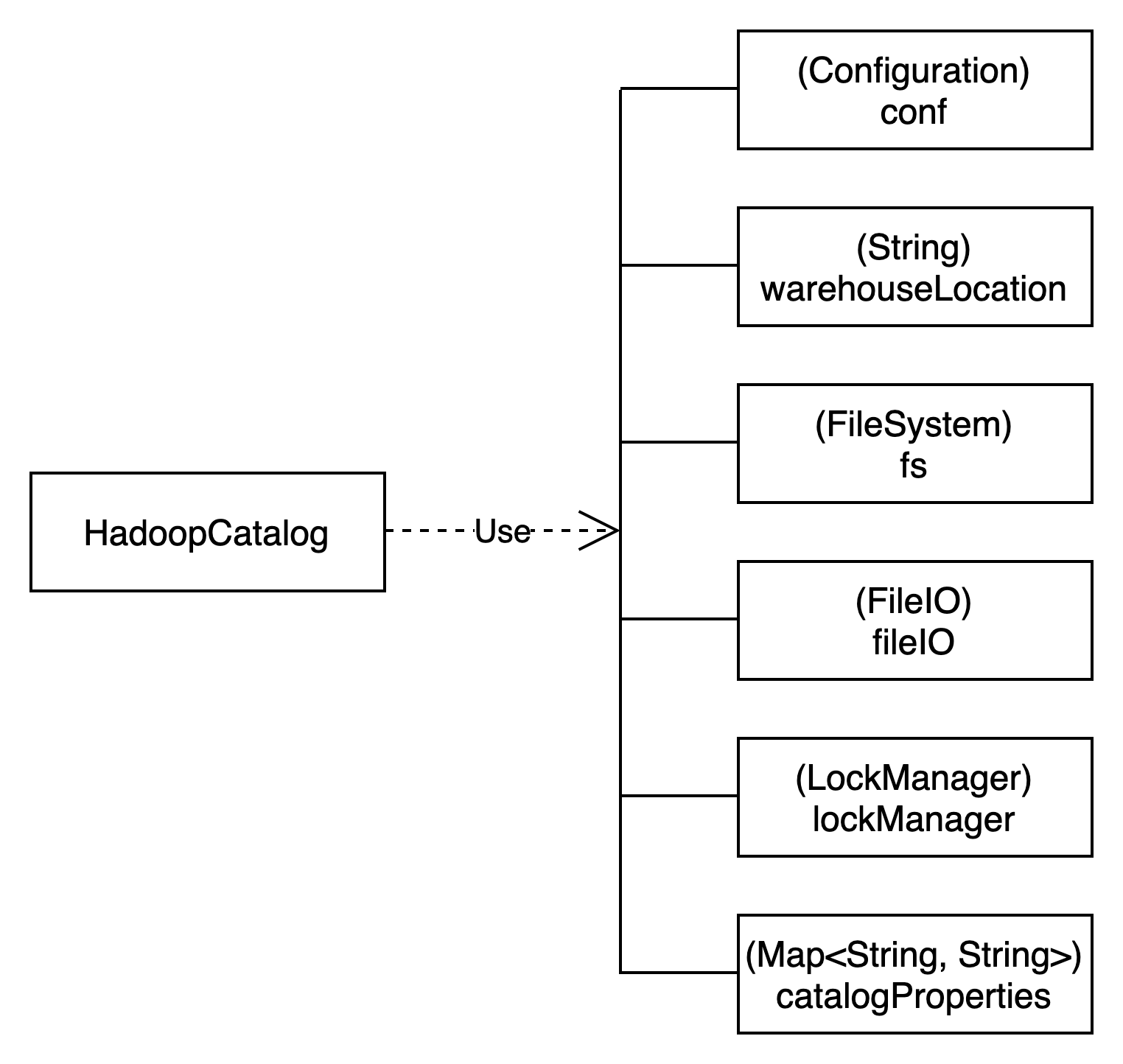
通过FileSystem来访问Hadoop获取元数据信息。拿到元数据信息后,通过FileIO读取具体的metadata文件内容。
JdbcCatalog
JdbcCatalog将表的元信息存储在支持JDBC协议的数据库中。
Iceberg的JdbcCatalog只是将本身的元数据存储在JDBC数据库中,Iceberg目前支持的数据来源也仅仅是Hadoop。
JdbcCatalog优缺点
优点如下:
(1)使用简单。
(2)数据库提供高可用性。
(3)不依赖云厂商。
缺点如下:
(1)不支持多表事务。
(2)所有的引擎和工具需要jdbc 驱动。
JdbcCatalog源码解析
JdbcCatalog类结构如下图所示:
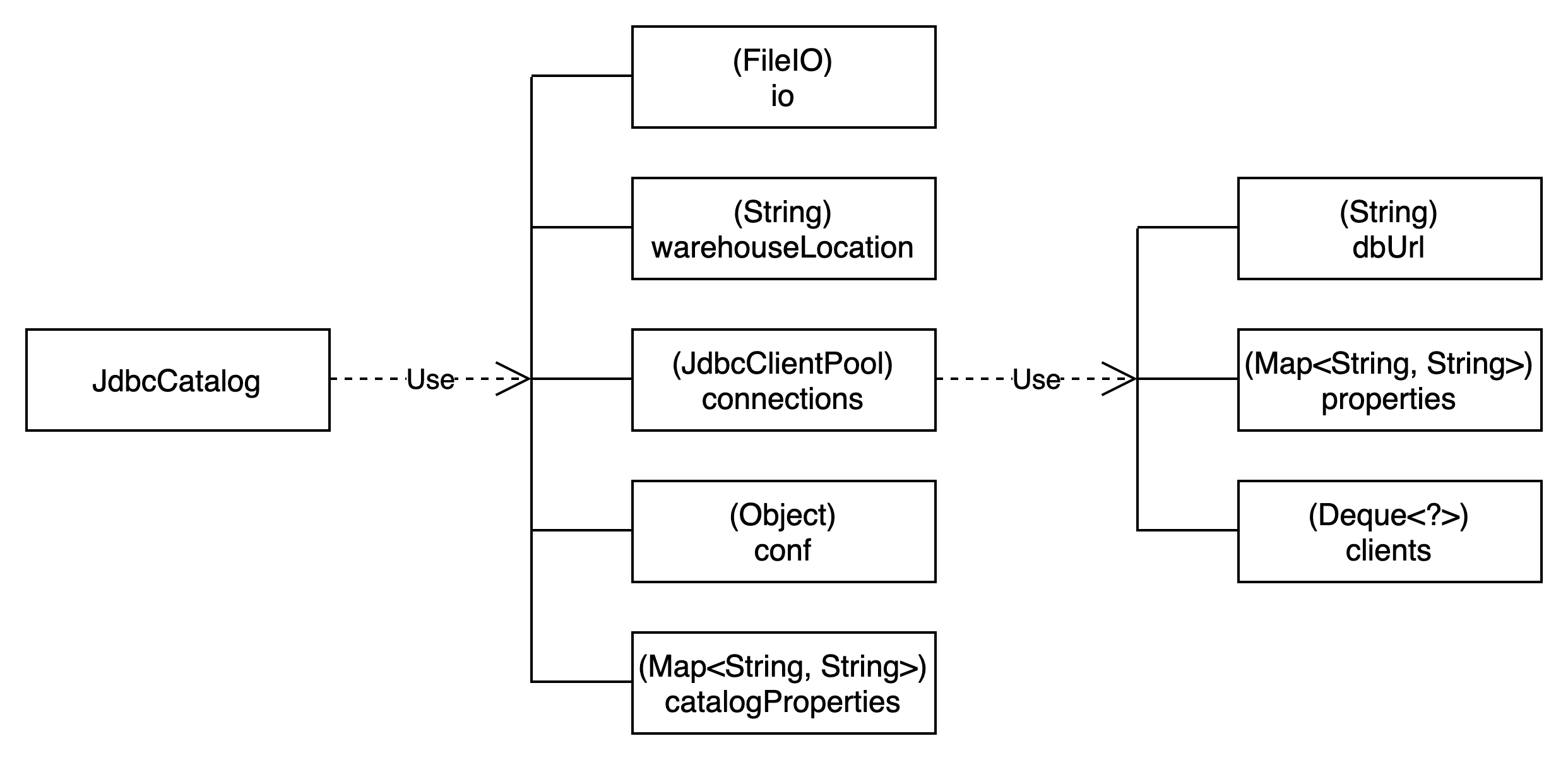
JdbcCatalog在catalog中的配置使用“jdbc.”为前缀。
JdbcCatalog通过jdbc connection从数据库中查询元数据信息,最终通过FileIO读取metadata文件信息。
RESTCatalog
通过REST服务来管理元数据。
RESTCatalog优缺点
优点如下:
(1)比较轻量,依赖更少,简化部署和管理,因为仅仅能发送标准 HTTP 请求即可。
(2)比较灵活,可以放在任意能处理 HTTP 请求的服务上,并且后端存储可以任意选择。
(3)不依赖云厂商。
缺点如下:
(1)必须运行一个服务处理 Rest请求。
(2)不是所有的引擎和工具支持,当前支持 Spark、Flink、Trino、Pylceberg 和 SnowFlake
RESTCatalog源码解析
RESTCatalog的类结构如下图所示:
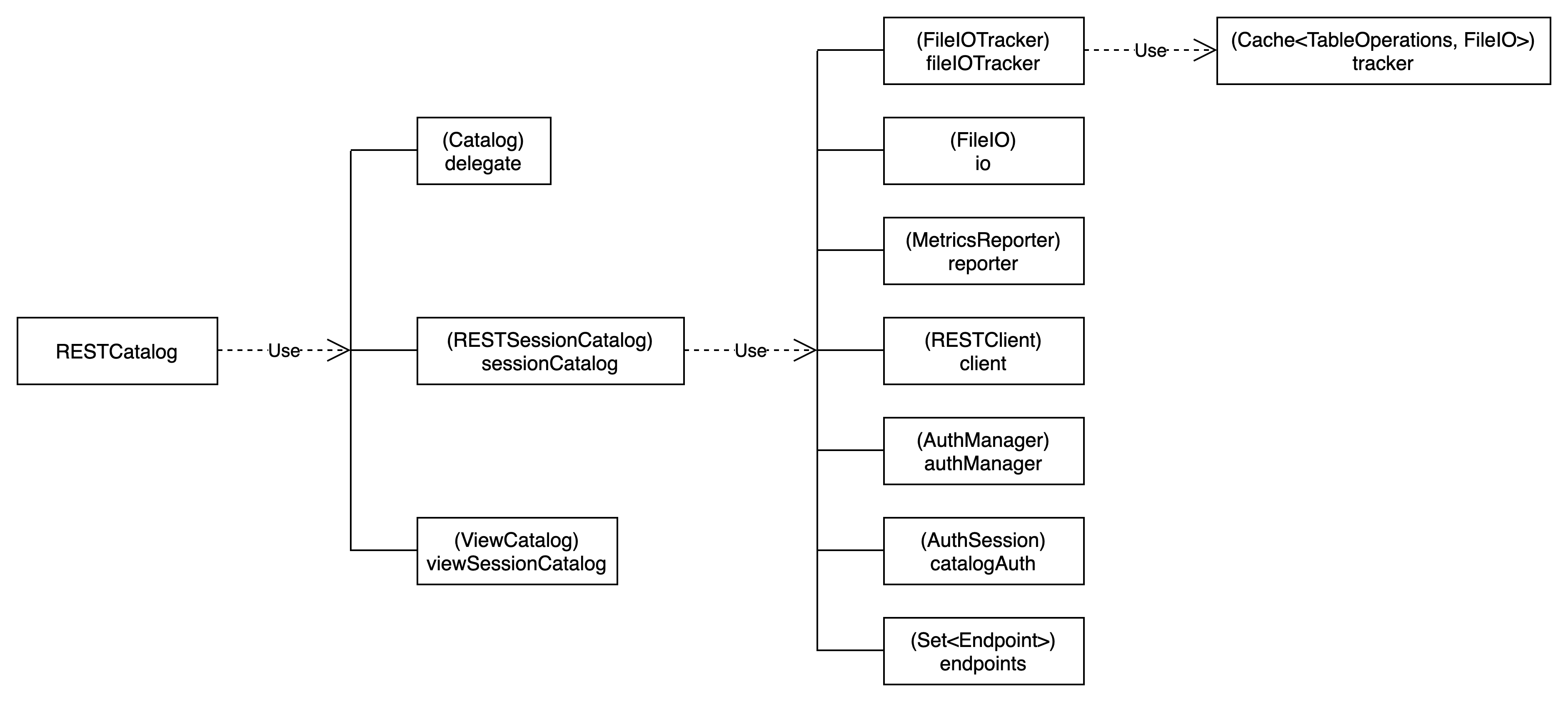
RESTCatalog的实现使用了代理机制,具体接口的调用完全通过RESTSessionCatalog来实现。
最终通过RESTClient来实现接口的调用
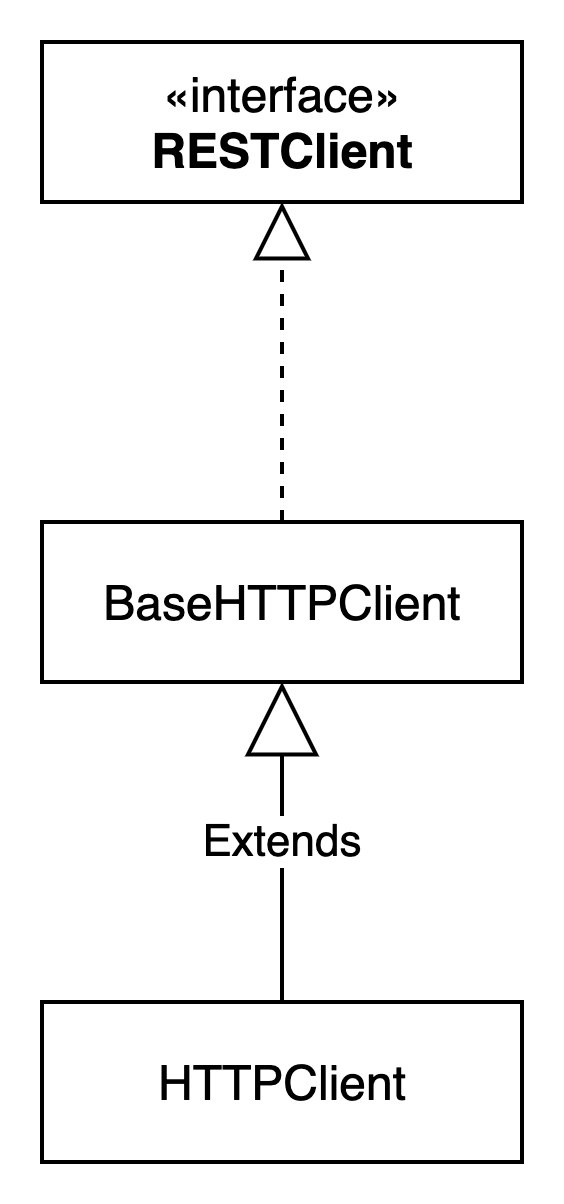
RESTClient最终通过httpclient5来实现接口通信。
RESTCatalog初始化过程
一般通过CatalogUtil#loadCatalog方法来加载一个catalog,过程如下:
org.apache.iceberg.CatalogUtil#loadCatalog
// 根据catalog的实现类配置初始化构造器
ctor = DynConstructors.builder(Catalog.class).impl(impl).buildChecked();
// 实例化Catalog
catalog = ctor.newInstance();
// 判断是否进行hadoop相关配置
configureHadoopConf(catalog, hadoopConf);
// catalog初始化函数调用
catalog.initialize(catalogName, properties);
return catalog加载过程首先需要进行具体Catalog的实例化,RESTCatalog的实例化过程如下:
org.apache.iceberg.rest.RESTCatalog#RESTCatalog()
// 创建SessionContext
context = SessionCatalog.SessionContext.createEmpty()
// 从catalog配置中提取HTTPClient所需的配置,包括uri和前缀为“header.”的配置
clientBuilder = HTTPClient.builder(config).uri(config.get(CatalogProperties.URI)).withHeaders(RESTUtil.configHeaders(config)).build());
// 创建RESTSessionCatalog
this.sessionCatalog = new RESTSessionCatalog(clientBuilder, null);
this.delegate = sessionCatalog.asCatalog(context);
this.nsDelegate = (SupportsNamespaces) delegate;
this.context = context;
this.viewSessionCatalog = sessionCatalog.asViewCatalog(context);加载过程最后需要对具体的Catalog实例进行初始化,也就是调用initialize函数,RESTCatalog#initialize执行过程如下:
org.apache.iceberg.rest.RESTCatalog#initialize
// 初始化RESTSessionCatalog
sessionCatalog.initialize(name, unresolved);
// 从props中提取环境变量
props = EnvironmentUtil.resolveAll(unresolved);
// 加载AuthManager
this.authManager = AuthManagers.loadAuthManager(name, props);
// 初始化AuthSession
AuthSession initSession = authManager.initSession(initClient, props)RESTCatalog认证
RESTSessionCatalog中涉及到接口的认证是通过AuthManager来实现的,AuthManager定义了初始化会话和连接的方法,支持不同的认证方式。
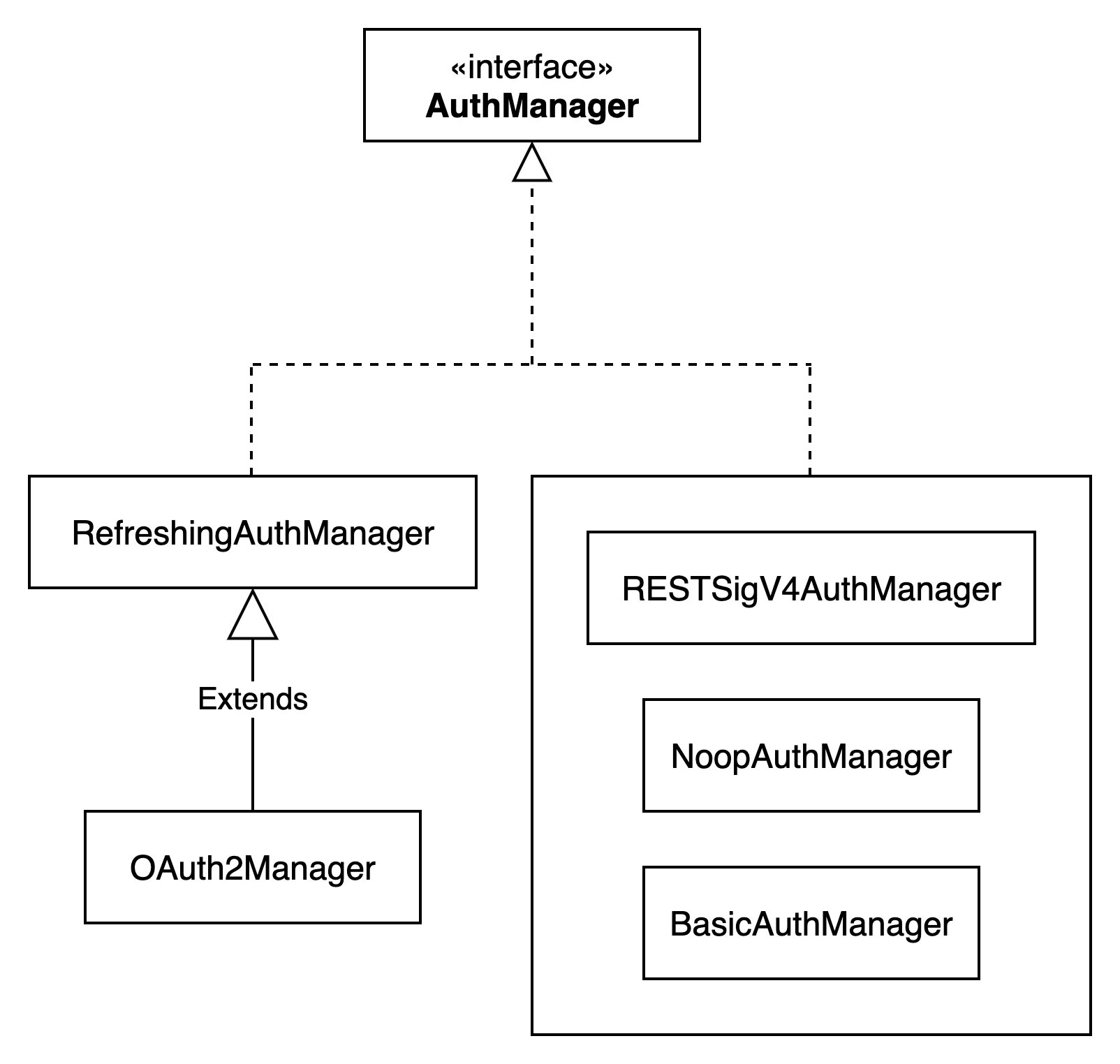
目前支持四种不同的认证方式,可以在catalog的配置中添加rest.auth.type属性,可配置值为none、basic、oauth2、sigv4。
FileIO元数据文件操作
RESTCatalog请求到元数据信息后,需要读取具体的metadata文件,这里通过FileIO来实现。
FileIO类结构图如下所示:
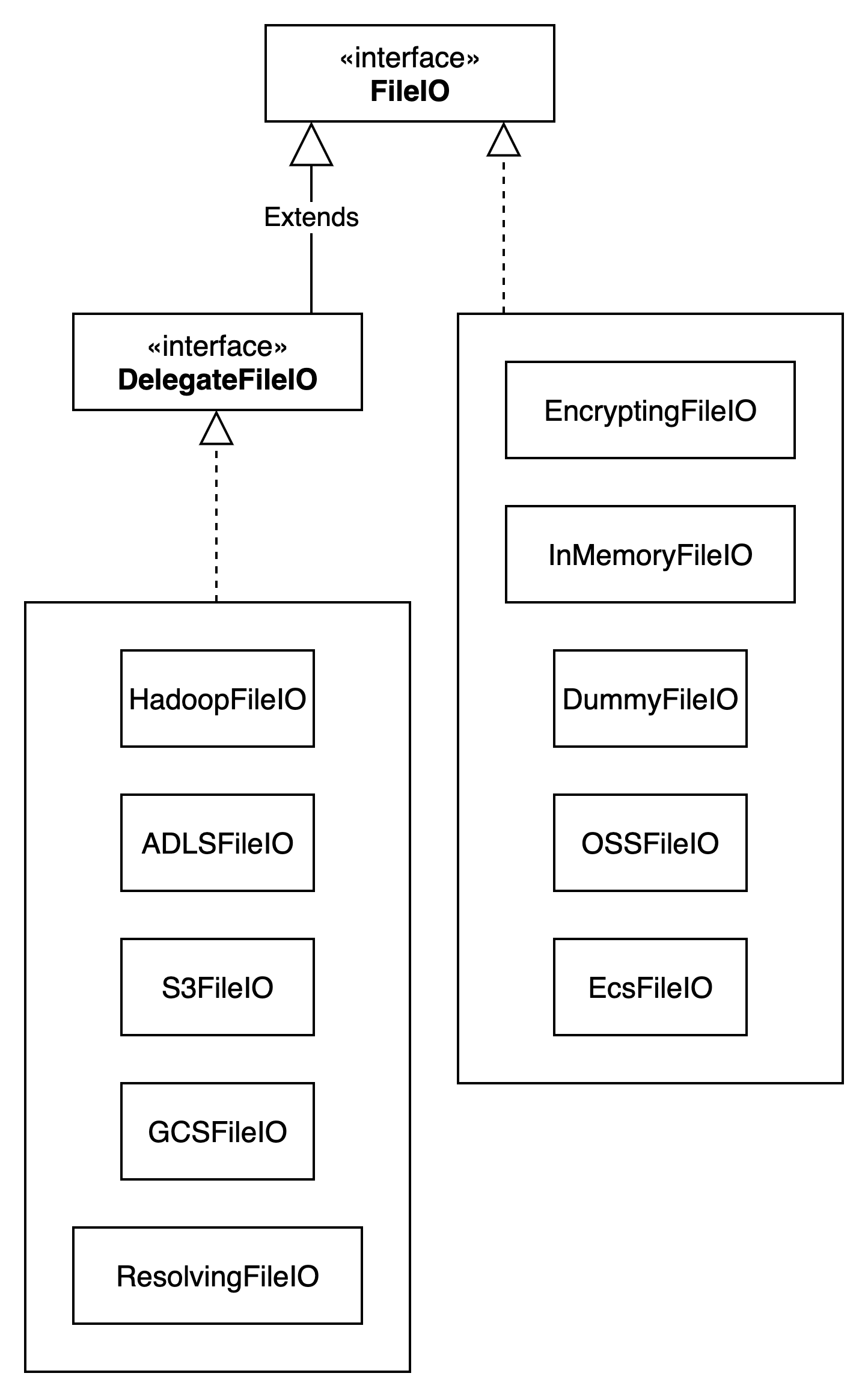
对于不同的文件系统,通过不同的FileIO来实现,目前支持十多种不同的FileIO。
GlueCatalog
GlueCatalog
AWS GlueCatalog使用表 metadata_location 作为表的路径。
GlueCatalog优缺点
优点如下:
(1)AWS Glue 是管理的服务,不需要像 Hive Metastore 的额外开销。
(2)和其他 AWS 服务紧密集成。
缺点如下:
(1)不支持多表事务。
(2)和 AWS生态绑定。
NessieCatalog
通过Nessie服务来管理元数据。
NessieCatalog优缺点
优点如下:
(1)使数据湖像 git 一样,意味着数据和相关的元数据可以版本化,像源代码一样管理。
(2)支持多表事务和多语句事务。
(3)不依赖云厂商。
缺点如下:
(1)不是所有的引擎和工具支持,当前支持 Spark、Flink、Dremio、Presto、Trino 和 Pylceberg
(2)额外启动和维护一个 Nessie 服务