从以下三种机制来了解kafka中的日志管理策略
数据分段机制
通过以下参数控制数据分段策略
数据刷新机制
通过以下参数控制数据刷新策略
数据清理机制
Kafka作为一个数据中间件,并不建议对数据进行永久保存,而是以数据过期机制来对历史数据进行清理,保证消息中间件最基本的特色。
以下基于kafka3.6.0源码,描述kafka日志段的清理机制
清理策略说明
清理机制由log.cleanup.policy参数配置,这是一个服务端参数。我们还可以为每个topic配置对应的cleanup.policy参数。
目前清理策略有两种——delete和compact。
delete清理机制
如果cleanup.policy为delete,则LogManager会对过期的日志段进行删除。
delete机制对应的模型如下图所示:
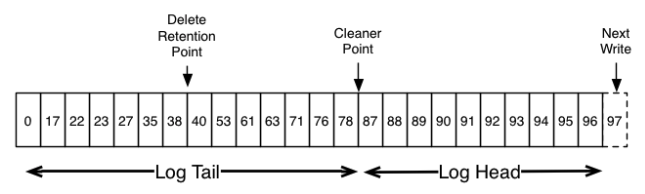
清理机制由LogManager来实现,在KafkaServer启动时启动对应的清理线程。
KafkaServer.startup
创建LogManager实例
LogManager.startup // 启动日志管理
LogManager.startupWithConfigOverrides
KafkaScheduler.schedule("kafka-log-retention", LogManager.cleanupLogs()) // 延迟时间固定为30秒,调度周期由log.retention.check.interval.ms决定,默认为5分钟
KafkaScheduler.schedule("kafka-log-flusher", LogManager.flushDirtyLogs()) // 延迟时间固定为30秒,调度周期由log.flush.scheduler.interval.ms决定,默认为Long.MAX_VALUE
KafkaScheduler.schedule("kafka-recovery-point-checkpoint", LogManager.checkpointLogRecoveryOffsets()) // 延迟时间固定为30秒,
KafkaScheduler.schedule("kafka-log-start-offset-checkpoint", LogManager.checkpointLogStartOffsets()) // 延迟时间固定为30秒,
KafkaScheduler.schedule("kafka-delete-logs", LogManager.deleteLogs()) // 延迟时间固定为30秒,仅调度一次。当有新的log需要被删除,会被再次动态调度
如果log.cleaner.enable配置为true(默认值为true)
创建LogCleaner实例
LogCleaner.startup // 启动LogCleaner实例
创建清理线程CleanerThread,线程数由log.cleaner.threads配置决定,默认值为1,线程名称为kafka-log-cleaner-thread-${threadId}
CleanerThread.startup // 启动每个CleanerThread线程
在任务执行过程中,如果有发现没有需要被清理的log,则调用CountDownLatch.await,线程进入等待,等待时间为由cleaner.backoff.ms参数决定,默认值为15秒。等待完成后,继续往下执行。
LogCleanerManager.maintainUncleanablePartitions // 执行清理具体的清理工作由LogManager.cleanupLogs函数来完成。
LogManager.cleanupLogs
从当前内存中的“分区-日志目录”映射中过滤出cleanup.policy为delete的分区
deletableLogs = currentLogs.filter { !log.config.compact }
遍历deletableLogs,执行删除操作
UnifiedLog.deleteOldSegments
如果如果分区的cleanup.policy为delete
UnifiedLog.deleteLogStartOffsetBreachedSegments()
// 删除baseOffset小于或等于logStartOffset的日志段
// 如果当前日志段为active LogSegment,则不清理。
UnifiedLog.deleteRetentionSizeBreachedSegments()
// 根据保留大小进行清理,与retention.bytes有关
// 当前segment之后的其他所有segments的总大小要不小于retention.bytes,才能删除当前segment;否则不删除
UnifiedLog.deleteRetentionMsBreachedSegments()
// 根据保留时间进行清理,与retention.ms有关
// broker的当前时间戳减去segment的largestTimestamp,如果值大于retention.ms,则删除此segment。
// segment的largestTimestamp的取值为timeindex文件最后一条记录的时间戳(TimestampOffset.timestamp属性)。
如果如果分区的cleanup.policy为delete
UnifiedLog.deleteLogStartOffsetBreachedSegments()
// 删除baseOffset小于logStartOffset的日志段
// 如果当前日志段为active LogSegment,则不清理。这里涉及到对应retention.ms和retention.bytes参数的比较。
segment.largestTimestamp可通过以下命令查看,取值为最后一条记录的timestamp
kafka-run-class.sh kafka.tools.DumpLogSegments --files XXXXXX.timeindex --print-data-logcompact压缩机制
compact会将同一个key的消息进行聚合,仅保留最后一条数据,其他数据全部无效,会被清理。
compact机制对应的模型如下图所示:
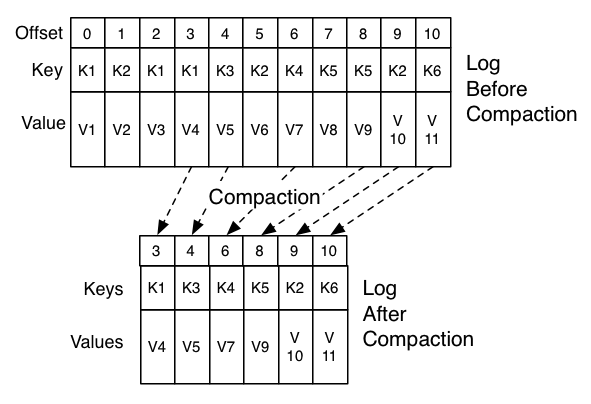
仅保留同一个key值对应的最大offset的value值。
kafka集群内置__consumer_offsets的清理策略是compact。
清理策略相关参数
相关参数可分为以下三类。
数据保留相关参数
有四个参数:
(1)log.retention.ms:保留时间毫秒数,默认为空,设置为-1表示永久保留。
(2)log.retention.minutes:保留时间分钟数,默认为空。
(3)log.retention.hours:保留时间小时数,默认168小时。
(4)log.retention.bytes:保留大小,默认值为-1,表示永久保存。
数据清理机制参数
有三个参数
(1)log.cleaner.enable:是否开启清理机制。
(2)log.retention.check.interval.ms:保留机制检查时间间隔,毫秒计,默认值为300000,表示5分钟检查一次。
(3)log.cleanup.policy:清理策略,有两个枚举值[compact, delete],默认值为delete,可以配置两个。特别要注意的是__consumer_offsets的清理策略为compact。
数据清理过程参数
清理过程参数有11个
(1)log.cleaner.threads:清理线程数,默认为1。
(2)log.cleaner.io.max.bytes.per.second
(3)log.cleaner.dedupe.buffer.size
(4)log.cleaner.io.buffer.size
(5)log.cleaner.io.buffer.load.factor
(6)log.cleaner.backoff.ms
(7)log.cleaner.min.cleanable.ratio
(8)log.cleaner.delete.retention.ms
(9)log.cleaner.min.compaction.lag.ms
(10)log.cleaner.max.compaction.lag.ms
清理机制相关的重大bug
KAFKA-9087
参考对应ISSUE:https://issues.apache.org/jira/browse/KAFKA-9087
社区bugfix PR为:https://github.com/apache/kafka/pull/13075/files
分区重分布处理过程的bug,执行重分布后,分区进入LogCleaningPaused状态,在执行cleanupLogs方法时,这些状态的分区会被过滤,不会被清理。然后重分布继续执行,并出现报错,报错信息如下:
[ReplicaAlterLogDirsThread-4]: Unexpected error occurred while processing data for partition test_topic-0 at offset 12345
java.lang.IllegalStateException: Offset mismatch for the future replica test_topic-0: fetched offset = 12345, log end offset = 0.此时,该分区的重分布因异常停止,而且分区一直处于LogCleaningPaused状态,如果继续长时间写入数据,则会导致磁盘空间膨胀,直到磁盘使用率为100%。