在向量化之前,数据库一直用的是volcano模型来处理SQL。
1.Volcano模型
Volcano模型中,一条SQL会被解析成一颗树,这棵树每个节点就是一个operator,也可以说是一个函数,进行一次计算处理。
比如,对于如下一个SQL
SELECT ta.pro_name, tb.name
FROM table_a ta
JOIN table_b tb
ON ta.pro_id = tb.pro_id AND ta.user_id = tb.id
WHERE ta.pro_id = 11111;得到的Volcano模型树如下图所示:
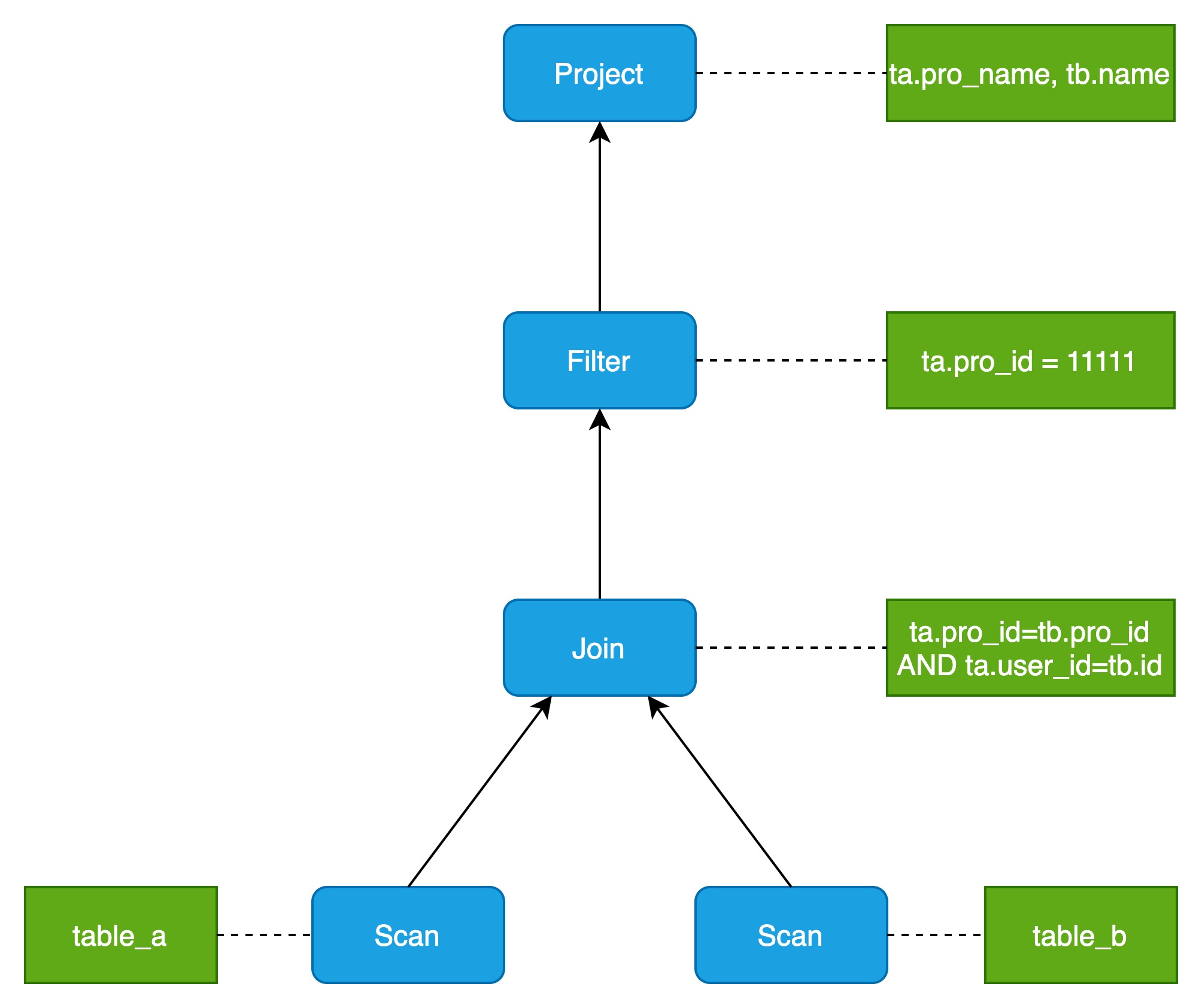
Volcano模型实现简单,只需要根据不同的计算提供一堆算子(operator)即可。不同的SQL可以看成是多个不同算子的组合,可以形成一个简单的递归调用结构,每行数据按照这个调用逻辑经过每个operator进行嵌套处理就得到最终结果。
1.1.Volcano模型优点
Volcano模型除了实现简单外,框架结构性也非常容易扩展。
1.2.Volcano模型缺点
Volcano模型的缺点是效率不高。表现在以下三个方面:
(1)每个operator拆分必须到最小粒度,导致嵌套调用过多过深
(2)嵌套都是虚函数无法内联
(3)这个处理逻辑整体对CPU流水线不友好,CPU希望你不停地给我数据我按一个固定的逻辑(流程)来处理,而不是在不同的算子中间跳来跳去。
2.向量化模型
向量化执行的思想就是不再像Volcano模型一样调用一个算子一次处理一行数据,而是一次处理一批数据来均摊开销。这个开销很明显会因为一次处理一个数据没用利用好cache_line以及局部性原理,导致CPU在切换算子的时候要stall在取数据上,表现出来的结果就是IPC很低,cache miss、branch prediction失败都会增加。
2.1.向量化加速的CPU原理
向量化加速体现在学习过CPU读取内存数据的过程,其实现原理体现在以下三点:
(1)内存访问比CPU计算慢两个数量级
(2)cpu按cache_line从内存取数据,取一个数据和取多个数据代价相同
(3)数据局部性原理
2.2.逐行遍历 vs 逐列遍历
一个大家耳熟能详的案例是对一个二维数组逐行遍历和逐列遍历的时间差异,循环次数一样,但是因为二维数组按行保存,所以逐行遍历对cache line 更友好,最终按行访问效率更高。
案例代码如下:
public class Main {
public static void main(String[] args) {
int row_size = 10240;
int col_size = 5120;
int[][] arr = new int[row_size][col_size];
for (int i = 0; i < row_size; i++) {
for (int j = 0; j < col_size; j++) {
arr[i][j] = i * col_size + j;
}
}
System.out.println("按行遍历");
long start = System.currentTimeMillis();
int sum = 0;
for (int i = 0; i < row_size; i++) {
for (int j = 0; j < col_size; j++) {
sum+=arr[i][j];
}
}
System.out.println(System.currentTimeMillis() - start);
sum = 0;
System.out.println("按列遍历");
for (int i = 0; i < col_size; i++) {
for (int j = 0; j < row_size; j++) {
sum+=arr[j][i];
}
}
System.out.println(System.currentTimeMillis() - start);
}
}根据不同的row_size和col_size,可以发现差异。
可以看到,随着数据量增大,逐行遍历与逐列遍历之间的性能差距越来越大。
2.3.向量化的实现——SIMD
对比向量化之前的版本,向量化之后的版本不再是每次只处理一条数据,而是每次能处理一批数据,而且这种向量化的计算模式在计算过程中也具有更好的数据局部性。
向量化–Vector、批量化(一次处理一批数据)。向量化核心是利用数据局部性原理,一次取一个和取一批的时延基本是同样的。volcanno模型每次都是取一个处理一个,跳转到别的算子;而向量化是取一批处理一批后再跳转。整个过程中最耗时是取数据(访问内存比CPU计算慢两个数量级)
为了支持这种批量处理数据的需求,CPU设计厂家又搞出了SIMD这种大杀器
2.3.1.SIMD定义
SIMD指令的作用是向量化执行(Vectorized Execution),中文通常翻译成向量化,但是这个词并不是很好,更好的翻译是数组化执行,表示一次指令操作数组中的多个数据,而不是一次处理一个数据;向量则代表有数值和方向,显然在这里的意义用数组更能准确的表达。
在操作SIMD指令时,一次性把多条数据从内存加载到宽寄存器中,通过一条并行指令同时完成多条数据的计算。例如一个操作32字节(256位)的指令,可以同时操作8个int类型,获得8倍的加速。同时利用SIMD减少循环次数,大大减少了循环跳转指令,也能获得加速。SIMD指令可以有0个参数、1个数组参数、2个数组参数。如果有一个数组参数,指令计算完数组中的每个元素后,分别把结果写入对应位置;如果是有两个参数,则两个参数对应的位置分别完成指定操作,写入到对应位置。
2.3.2.如何生成SIMD指令
有以下三种方式生成SIMD指令:
(1)编译器自动向量化:静态编译(代码满足一定的规范;编译选项 -O3 or -mavx2 -march=native -ftree-vectorize)
(2)即时编译(JIT)
(3)可以手写SIMD指令
2.4.向量化的代码要求
向量化的代码需买组以下要求:
(1)循环次数可计算
(2)简单计算,不包含函数调用、switch/if/return 等
(3)在循环在内层
(4)访问连续的内存空间(才可以通过simd指令从内存加载数据到寄存器)
(5)数据无依赖
(6)使用数组而不是指针
2.5.向量化的问题
向量化的前提是L3 cache够用,在L3不够用的时候,向量化的收益是负的,国内大部分文章都是为了PR而讲向量化。并发稍微高点,向量化立马就没足够的加速效果了。L2的一次miss就足够让向量化收益清零了,都轮不到 L3 Miss。
比如 avx512,向量化基本是用8倍的带宽,换取2-3倍的延迟,还要降频(指令复杂了)。所以 skylake 开始,intel砍了L3,加了L2。
大部分向量化引擎的收益是来自向量化后被迫做了列存(或者说列存做向量化更加简单,所以大家工程上会选择向量化),这天然带来了数据密度更高,不是向量化导致了性能好。
SIMD 的代码对流水线要求很高的,大部分SIMD都不是编译器生成的,需要开发者自己去做指令的调度,但是实际上大部分开发者并没有微架构的知识,所以很难开发。
SIMD 适合解决计算瓶颈的问题,而不是数据库的内存瓶颈。计算瓶颈和内存瓶颈是完全的2个概念,只是大部分时候,我们会把内存瓶颈和计算瓶颈合起来叫做 CPU 瓶颈,但是db 90%以上场景,确实是内存而不是计算瓶颈…尤其是AP领域对同一份数据多次重复运算的, 那才叫做计算瓶颈。
向量化的本质不是 SIMD,是内存密度。