1.Spark Catalog概述
Spark Catalog时Spark SQL中的一个元数据管理组件,它提供了一个集中化的存储和查询表、视图和函数的工具。通过Spark Catalog的扩展能力,我们可以与多种不同的数据源进行集成。
注:本文根据spark-3.5.1源码输出。
2.Catalog的作用
我们可以通过Spark SQL来对各种数据元进行CRUD操作,最典型的比如Hive数据元,sql语句是以表的方式对数据进行管理的,表本身的定义是如何进行管理的呢?这里就不得不提到元数据的概念,也就是对表本身的描述,而不是数据本身。而Catalog正是Spark 2.0之后提供访问元数据的类。如下代码所示:
package org.apache.spark.sql.catalog
/**
* Catalog interface for Spark. To access this, use `SparkSession.catalog`.
*
* @since 2.0.0
*/
@Stable
abstract class Catalog {
// 包含各种不同类型资源方法的访问定义
// catalog相关方法:currentCatalog、setCurrentCatalog、listCatalogs
// 数据库相关方法:currentDatabase、setCurrentDatabase、listDatabases、getDatabase、databaseExists
// 表相关方法:listTables、getTable、tableExists、createExternalTable、createTable、recoverPartitions、refreshTable、refreshByPath
// 列相关方法: listColumns
// 函数相关方法:listFunctions、getFunction、functionExists
// 视图相关方法:dropTempView、dropGlobalTempView
// 缓存相关方法:isCached、cacheTable、uncacheTable、clearCache
}Catalog正是通过这些API来对Catalog、Database、Table、View、Cache、Column、Function进行操作。
Catalog是一个抽象类,具体实现为org.apache.spark.sql.internal.CatalogImpl。这两个类都是在spark-sql源码模块中。
Catalog在Spark SQL的整个执行执行过程中的角色如下图所示:
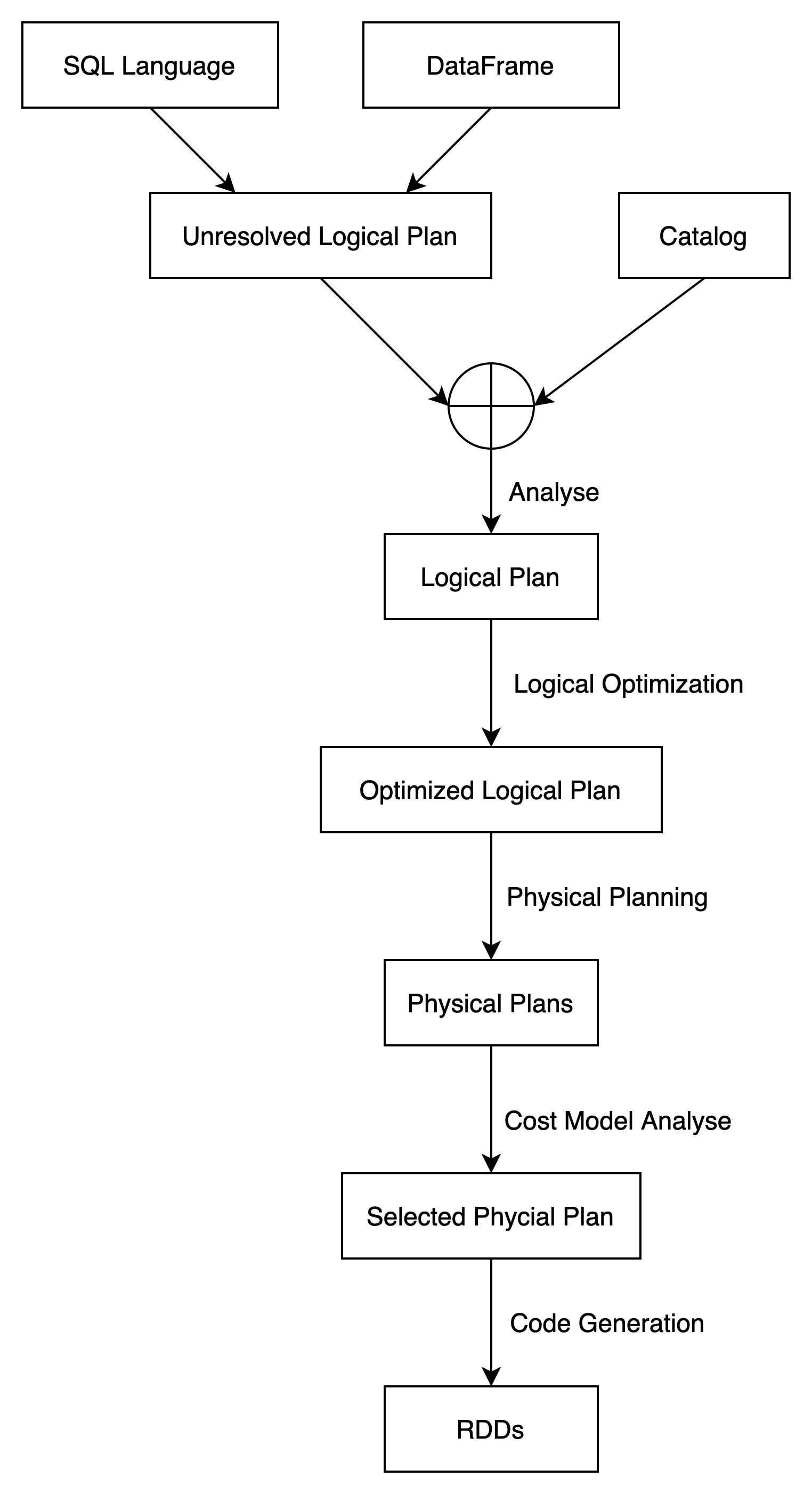
Spark SQL在生成逻辑计划时,需要Catalog的参与。
3.CatalogPlugin
Spark3.0推出了Catalog Plugin特性,可参考文档说明——https://spark.apache.org/releases/spark-release-3-0-0.html
Spark3.0之后,我们可以轻松地对内置的Catalog进行自定义扩展。
3.1.CatalogPlugin产生的背景
DataSourceV2是Spark 2.X推出的API,主要用于和外部数据存储进行集成,比如数据的读写。但这里缺少了关键的一环,即对表元数据的操作。
SparkSQL 和 DataFrame 操作都支持 CTAS (Create Table AS Select) 用来创建一个表并向该表写入数据,注意这里是一个操作。缺少创建目标表的 API,CTAS 的实际行为将完全取决于 DataSourceV2 的实现。比如写表失败,表可能被保存也可能被删除。并且在某些 SaveMode 下,我们无法区分 CTAS 和普通的写操作,那么很有可能在 Append 模式下写表的时候会因为表被删除而失败。最后一点,Spark 没有一种机制用来设置由 CTAS 创建的表,比如分区。
除此之外,数据工程师也希望类似 CTAS 的 high-level 操作在数据源上面进行操作的时候能保持行为一致。 SPIP to Standardize SQL Logical Plans 介绍了一些 high-level 的操作,并且总结了这些操作的期望行为,并期望 Spark 在内部实现上设计一种机制进行保证。这也要求 Catalog API 能对那些数据源进行创建、修改以及删除等操作。
举个例子,为了实现 CTAS,Spark 会创建、写入或者删除表(写入失败时)。这样的话,当元数据管理不可用或者 driver 自己失败的时候,CTAS 可能会删除表不成功。
除此之外,还有一个暴露 catalog API 的需求。我们使用 DataFrame 编写 Spark 程序的时候可以使用 SQL 引擎,但是并没有类似创建、修改以及删除这种 catalog 的 API 提供。在 Spark 代码中,Catalog 接口提供了一些操作,但是并不够全面和强大,比如不支持 multi catalog。
以上就是 Catalog Plugin 产生的背景。
3.2.CatalogPlugin实现链路
CatalogPlugin的类视图如下所示:
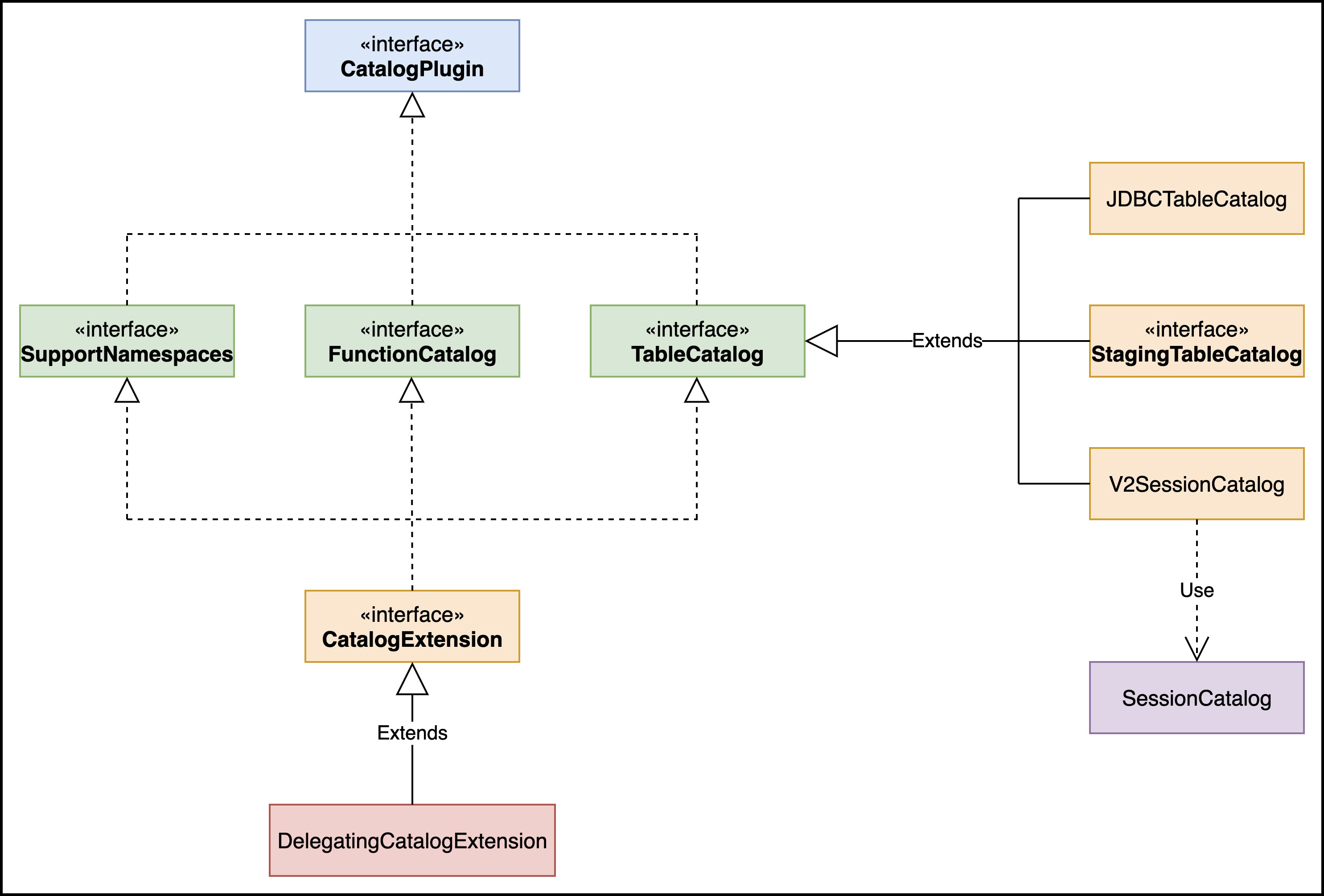
TableCatalog 定义了 Catalog 和表进行交互的方法,其实就是前面说的增删改。
V2SessionCatalog使用了SessionCatalog进行具体的操作实现。
SessionCatalog类视图如下所示:
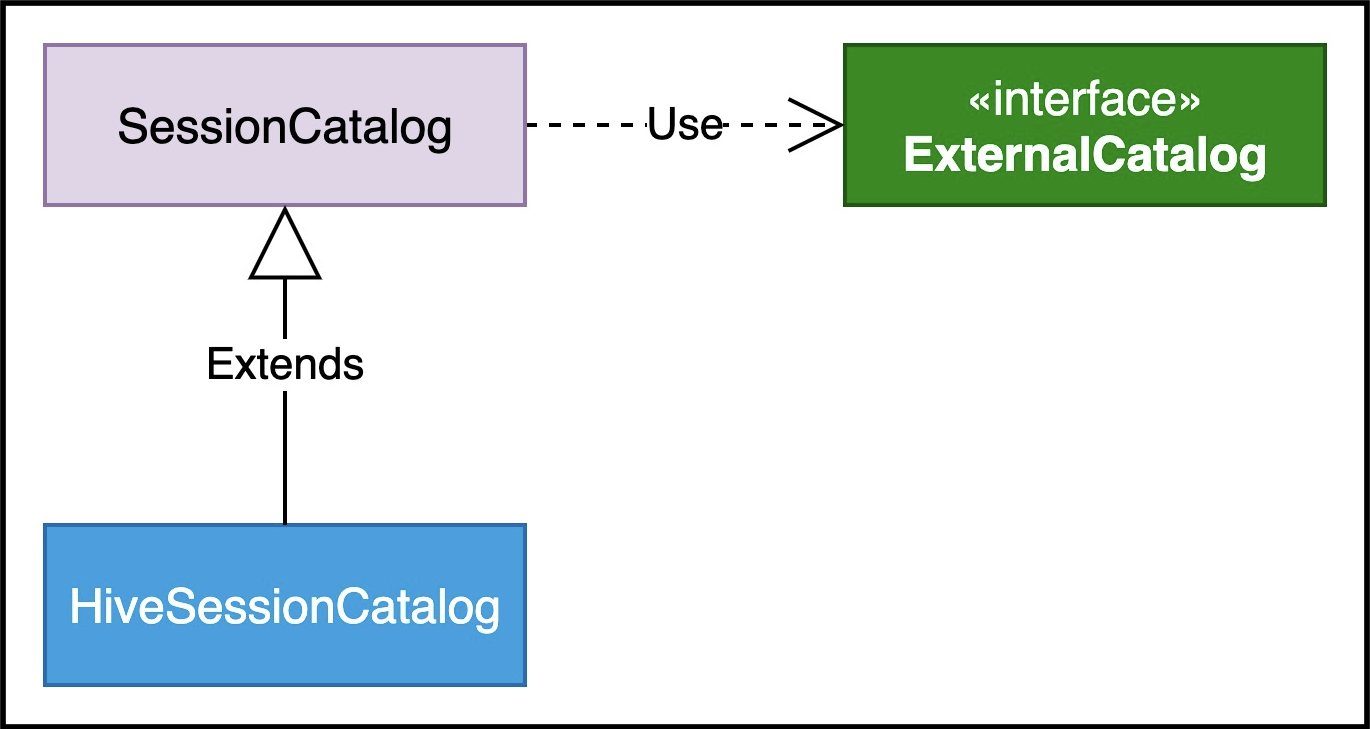
SessionCatalog使用了ExternalCatalog作为操作DataSourceV2的具体实现类。
ExternalCatalog类视图如下所示:
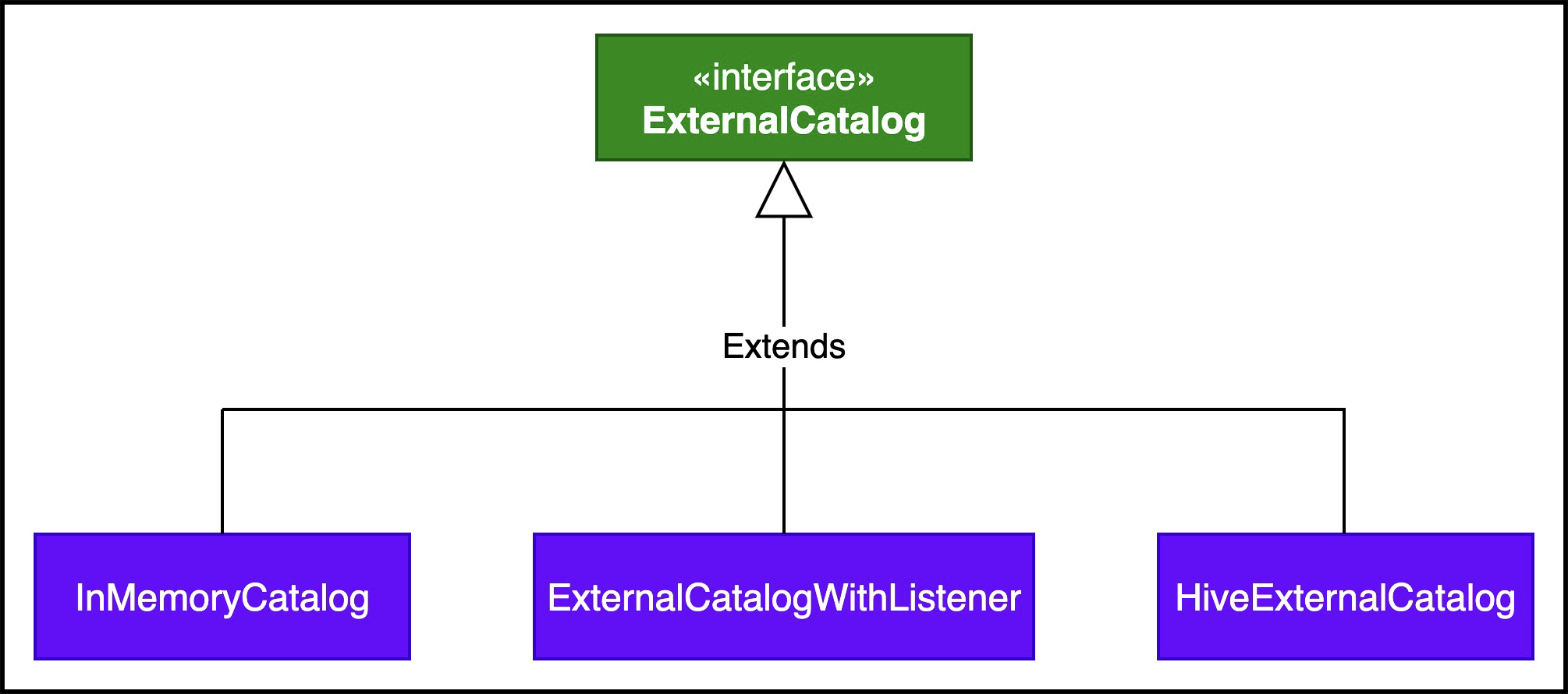
Spark中,CatalogManager可以同时管理内部连接多个catalog,通过spark.sql.catalog.${name}进行注册多个catalog,Spark默认的catalog由spark.sql.catalog.spark_catalog参数指定。