1.Spark内部通信架构
Spark通信架构如下图所示:
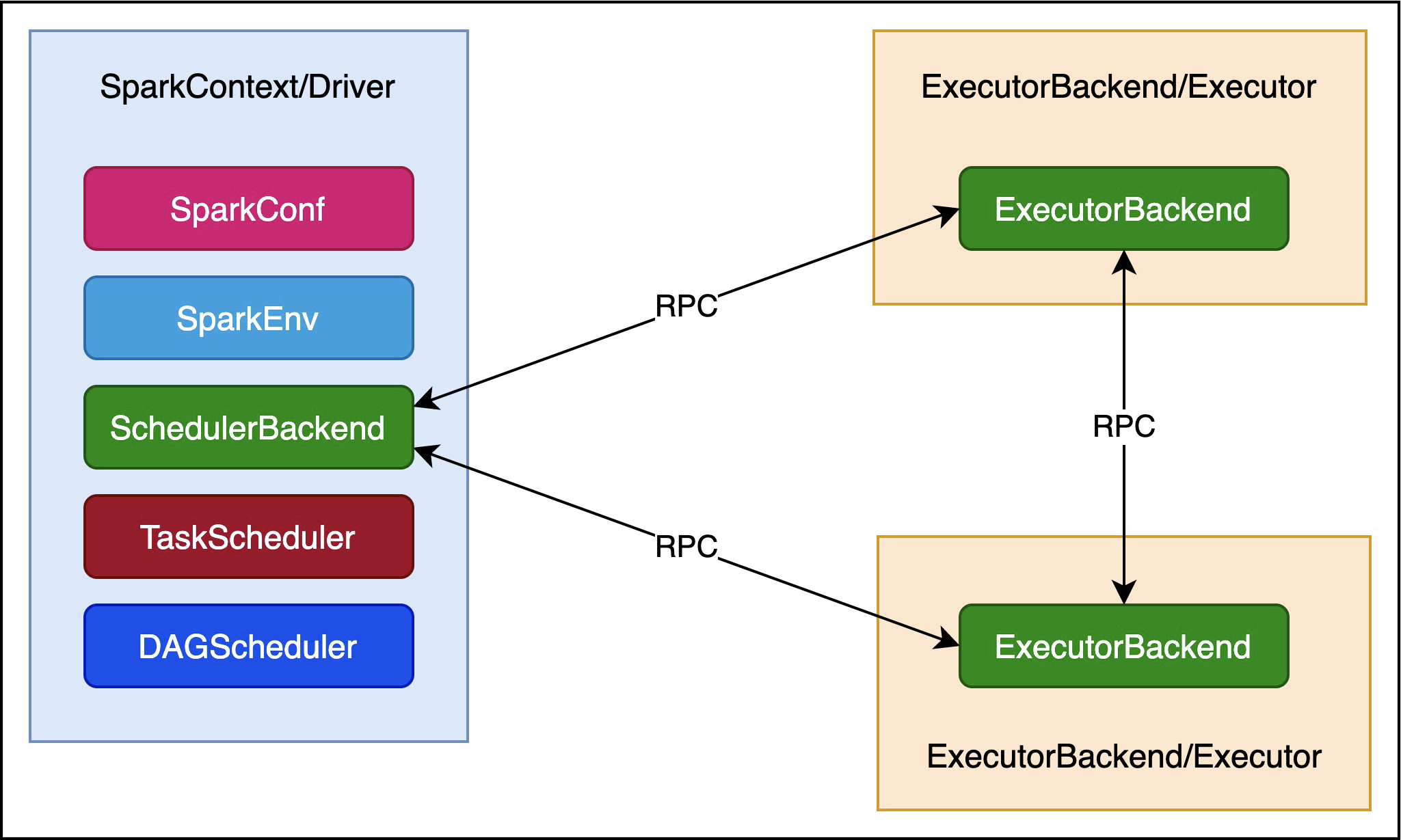
Driver与Executor之间,以及Executor之间,都是通过RPC协议通信的。
2.Spark通信架构演进
Spark通信架构的发展主要经历了以下四个过程:
(1)Spark早期版本使用Akka作为内部通信组件。
(2)Spark1.3中引入了Netty通信框架,主要是为了解决Shuffle的大数据传输问题。
(3)Spark1.6中Akka和Netty可以配置使用,Netty已经完全实现了Akka在Spark中的功能。
(4)Spark2系列中,Spark彻底抛弃Akka,使用Netty。
效率上:BIO<NIO<AIO。
遗憾的是,Netty在linux上无法使用AIO。
Spark基于Netty新的RPC框架借鉴了Akka中的设计,它是基于Actor模型的。
2.1.Actor模型
如下图所示:
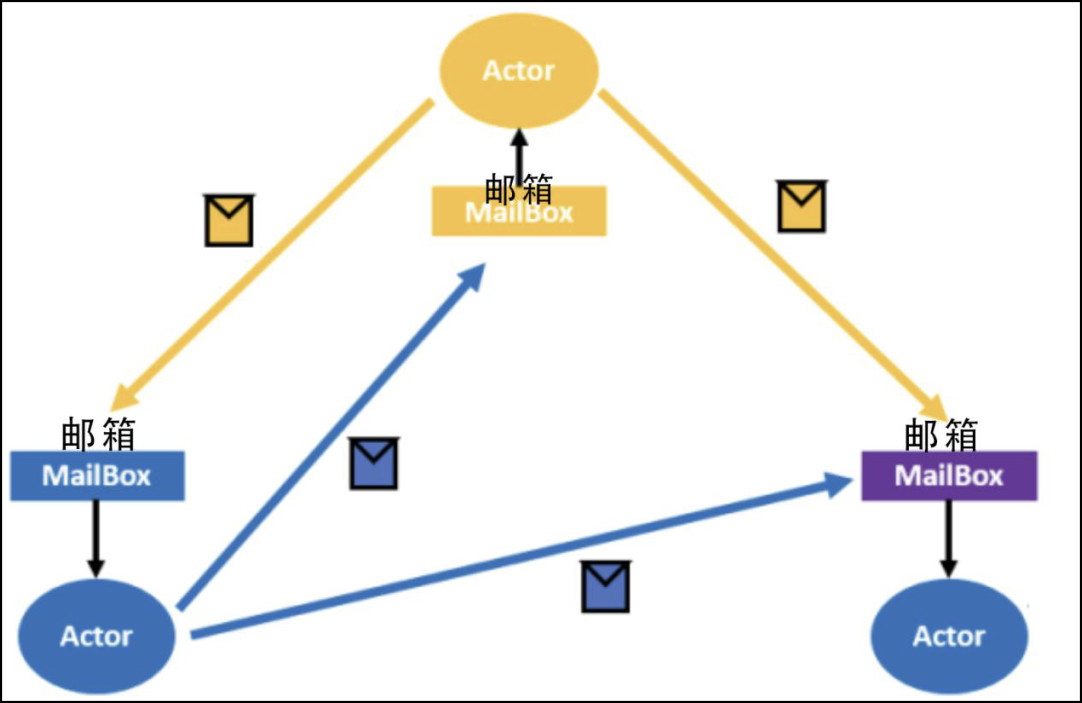
Actor模型类似面向对象编程(OO)中的对象,每个Actor模型实例封装了自己相关的状态,并且和其他Actor处于物理隔离状态。举一个游戏玩家的例子,每个玩家在Actor模型系统中是Player这个Actor的一个实例,每个player都有自己的属性,比如ID、昵称、攻击力等。
Actor模型内部是以单线程的模式来执行的,类似于redis,所以Actor模型完全可以实现分布式锁及类似的应用。
每个Actor模型都有一个专用的MailBox来接收消息,这也是Actor模型实现异步的基础。当一个Actor模型实例向另外一个Actor模型发消息的时候,并非直接调用Actor的方法,而是把消息传递到对应的MailBox里,就好像邮递员,并不是把邮件直接送到收信人手里,而是放进每家的邮箱,这样邮递员就可以快速地进行下一项工作。所以在Actor模型系统里,Actor模型发送一条消息是非常快的。
这样设计的主要优势就是解耦了Actor,数万个Actor并发的运行,每个actor都以自己的步调运行,且发送消息、接收消息都不会被阻塞。
3.Executor中通信终端启动过程
Executor的启动过程中,首先就是通信终端的启动,过程如下:
CoarseGrainedExecutorBackend#main
CoarseGrainedExecutorBackend.run()
SparkEnv.createExecutorEnv()
SparkEnv.create()
RpcEnv.create()
new NettyRpcEnvFactory()
NettyRpcEnvFactory.create()
new NettyRpcEnv()
Utils.startServiceOnPort()
NettyRpcEnv.startServer()最后,会启动一个TransportServer对象,用于接收请求。
4.Spark内部通信过程
Spark内部通信组件消息流转如下图所示:
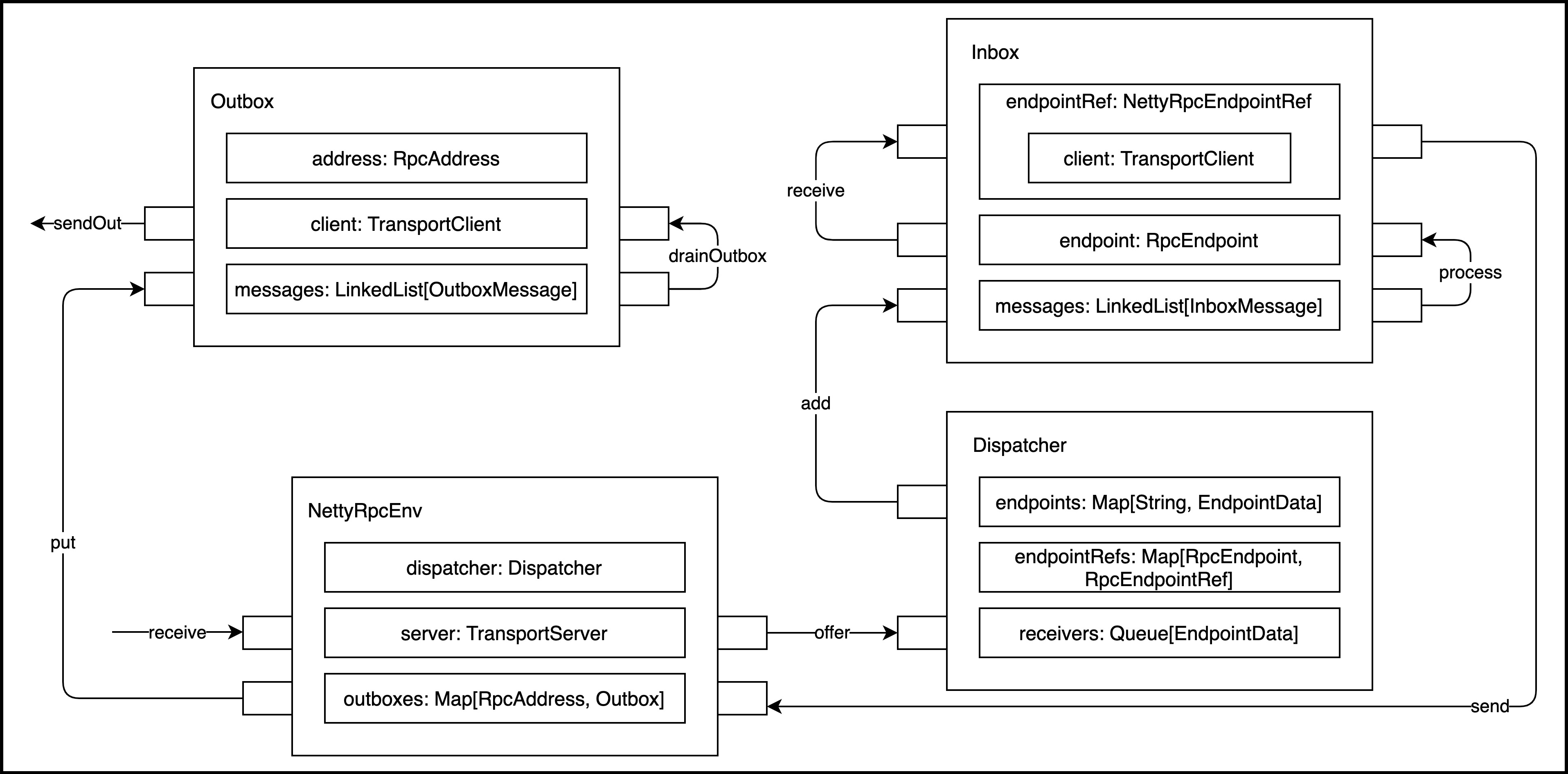
共包含10个组件。整个过程从NettyRpcEnv的receive方法接收消息开始,到Outbox的sendOut方法发送消息而结束。
4.1.RpcEndpoint
RPC端点,Spark针对每个节点(Client/Master/Worker)都称之为一个Rpc端点,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消息和不同的业务处理,如果需要发送(询问)则调用Dispatcher。所有的端点都存在生命周期:constructor、onStart、receive*、onStop。
RpcEndpoint的默认实现有以下几种:
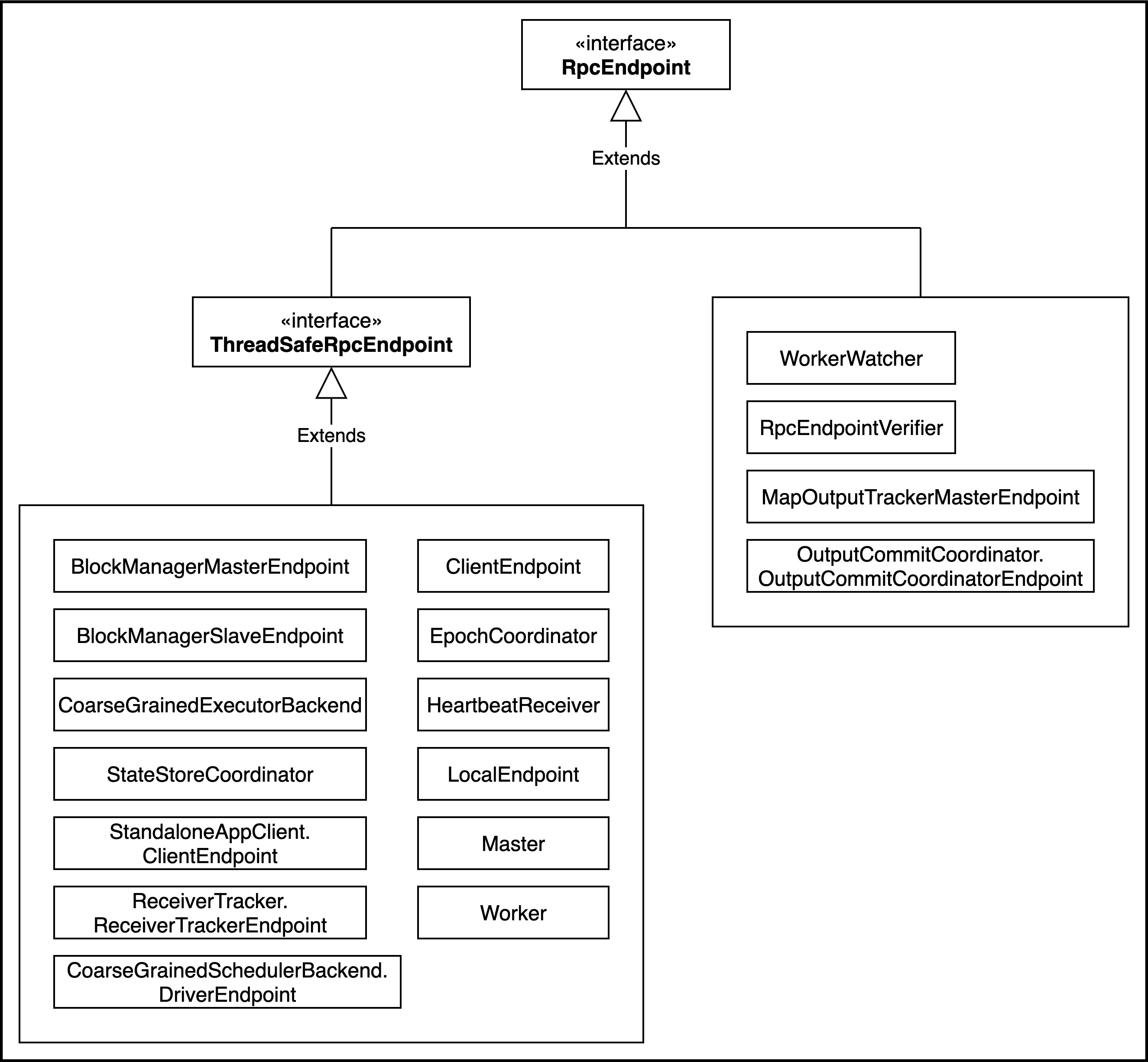
所有RpcEndpoint的处理由org.apache.spark.rpc.netty.Inbox,有此类接收请求。
4.2.RpcEnv
RPC上下文环境,每个RPC端点运行时依赖的上下文环境称为RpcEnv。当前spark版本中使用NettyRpcEnv。目前RpcEnv的作用有以下三点:
(1)整个通信的核心,为通信构建环境,启动server。
(2)建立RpcEndpoint,所有RpcEndpoint(提供某类服务)都需要注册到RpcEnv。
(3)消息路由,也就是整个RpcEndpoint的通信都交给RpcEnv。屏蔽了rpc调用与本地调用,让上层专注endpiont的设计,通信细节全部封装到RpcEnv。
NettyRpcEnv在driver和executor上都会创建。
4.3.Dispatcher
消息分发器,针对于RPC端点需要发送消息或者从远程RPC接收到的消息,分发至对应的指令收件箱/发件箱。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱。
Dispatcher就是根据不同的endpoint name进行消息分发,交给对应的endpoint进行处理。
4.4.Inbox
指令消息收件箱,一个本地RpcEndpoint对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部ReceiverQueue中,另外Dispatcher创建时会启动一个单独线程进行轮询ReceiverQueue,进行收件箱消息消费。
4.5.RpcEndpointRef
RpcEndpointRef是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该引用发送消息。
Inbox收到的第一条消息是Inbox在初始化时添加的,如下代码所示:
// OnStart should be the first message to process
inbox.synchronized {
messages.add(OnStart)
}而Inbox中的消息是如何处理的呢?
4.5.1.Inbox消息处理逻辑
处理过程如下:
org.apache.spark.rpc.netty.Dispatcher初始化
val endpoints: ConcurrentMap[String, MessageLoop] // 用于保存各种注册进来的Endpoint
Dispatcher.registerRpcEndpoint() // 注册Endpoint
根据endpoint的类型,创建不同类型的MessageLoop对象,并放入endpoints对象中
org.apache.spark.rpc.netty.MessageLoop初始化过程
创建一个Runnable对象,记为receiveLoopRunnable,用于对
receiveLoop()
从列表中取出Inbox对象,记为inbox
如果inbox不是MessageLoop.PoisonPill,则进行以下处理
调用Inbox.process方法,对inbox中的消息进行处理
创建一个线程池对象,记为threadpool
线程数由spark.rpc.netty.dispatcher.numThreads参数以及当前endpoint所处的角色决定,记为numThreads
将receiveLoopRunnable推送到threadpool,推送numThreads次。
pool.execute(receiveLoopRunnable)Inbox.process方法就是不停地取出inbox链表中的InboxMessage对象,根据InboxMessage对象的类型分类进行处理,类型主要有:RpcMessage、OneWayMessage、OnStart、OnStop、RemoteProcessConnected、RemoteProcessDisconnected、RemoteProcessConnectionError。
4.6.OutBox
指令消息发件箱,对于当前RpcEndpoint来说,一个目标RpcEndpoint对应一个发件箱,如果向多个目标RpcEndpoint发送信息,则有多个OutBox。当消息放入Outbox后,紧接着通过TransportClient将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行。
4.7.RpcAddress
表示远程的RpcEndpointRef的地址,Host + Port。
4.8.RpcEndpointAddress
表示一个Endpoint的地址,有两种表现形式:
(1)由RpcAddress和name组成,常见格式为“spark://${name}@${rpcAddress.host}:${rpcAddress.port}”。
(2)直接由name组成,常见于客户端服务,常见格式为“spark-client://${name}”
4.9.TransportClient
Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer。
4.10.TransportServer
Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱。