Kafka MirrorMaker2是kafka-2.4.0版本的新特性,用于集群间kafka消息的同步。
MM2如何控制topic和group
通过过滤器进行控制
topic过滤器接口为org.apache.kafka.connect.mirror.TopicFilter ,通过参数topic.filter.class进行控制,默认值为org.apache.kafka.connect.mirror.DefaultTopicFilter
topic过滤器相关配置如下
(1)topics:方向配置,需加方向前缀,默认值.*
(2)topics.exclude:方向配置,需加方向前缀,默认值.*[\\-\\.]internal, .*\\.replica, __.*
(3)topics.blacklist:方向配置,需加方向前缀
(4)topic.filter.class:全局配置
group过滤器接口为org.apache.kafka.connect.mirror.GroupFilter,通过参数group.filter.class进行控制,默认值为org.apache.kafka.connect.mirror.DefaultGroupFilter
group过滤器相关配置如下:
(1)groups:方向配置,需加方向前缀,默认值.*
(2)groups.exclude:方向配置,需加方向前缀,默认值console-consumer-.*, connect-.*, __.*
(3)groups.blacklist:方向配置,需加方向前缀
(4)group.filter.class:全局配置
目标端同步topic的名称
目标端topic的名称由replication.policy.class配置的类决定,默认值为org.apache.kafka.connect.mirror.DefaultReplicationPolicy,直接使用”{源集群名}.{源topic名}”作为目标端新建topic的名称

separator由参数replication.policy.separator决定,默认值为“.”
如果要保持源端和目标端集群名称一致,则需要自定义一个ReplicationPolicy实现类。
在Kafka3.1.0版本新增了这样的特性https://issues.apache.org/jira/browse/KAFKA-10777
配置如下:
replication.policy.class=org.apache.kafka.connect.mirror.IdentityReplicationPolicy
即可实现源端和目标端topic名称保持一致。
Topic和Group不匹配的场景
同一个MirrorMaker2任务中,如果配置的group和topic不匹配,即此group消费者并不消费这个topic,那么group是否会同步?
答案是:不会
演示场景
(1)源端创建两个topic:aaa001和eee001,并生产数据
(2)消费源端数据,源端消费组group20250513001中的消费者只消费eee001

(3)目标端无eee001这个topic
(4)启动MirrorMaker2任务,配置如下
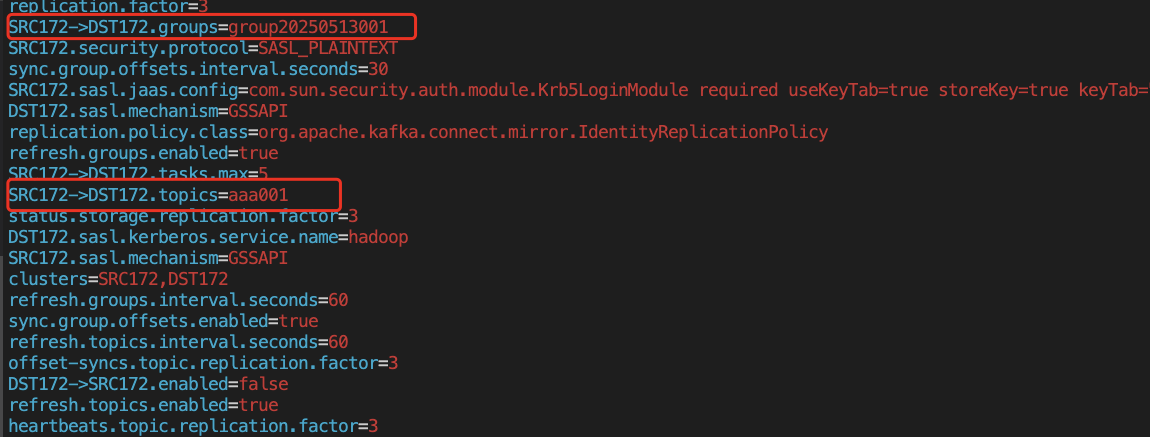
(5)同步10分钟后,目标端无此group信息
Error: Consumer group 'group20250513001' does not exist.
(6)重新配置MirrorMaker2,并启动,添加eee001这个topic的同步,配置如下:
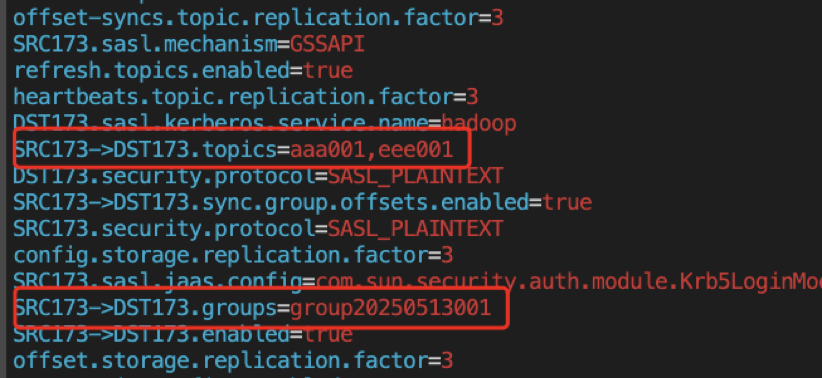
(7)1分钟后,目标端可以看到group20250513001这个group信息

结论:如果需要同步的group消费的topic不存在于目标端,则此group不会被同步。
group是增量还是全量同步的
Group信息保存在__consumer_offsets这个topic中
(1)源端创建topic,名称为ccc001,并生产消息。
(2)源端消费消息,消费组为cg001,详细信息如下图所示:

共5个分区,消费10条数据,0条消息未被消费。
(3)目标端不存在ccc001这个topic和cg001这个group
(4)启动MirrorMaker2同步任务,同步ccc001这个topic和cg001这个group。
(5)1分钟后,目标端ccc001这个topic的状态

(6)2分钟后,目标端cg001这个group的状态

共5个分区,消费10条数据,0条消息未被消费。
此时可看成是全量同步。
(7)往目标端ccc001这个topic生产数据
生产6条消息。
(8)目标端cg001这个group的状态

剩余6条消息未被消费。
(9)往源端ccc001这个topic生产数据
共生产7条数据。
(10)源端cg001这个group的状态

总消息量为10+7=17,有7条消息未被消费。
(11)目标端cg001这个group的状态

总消息量为10+6+7=23,有13条消息未被消费,正好是目标端生产的数据量(6条)加源端生产的数据量(7条)之和。
(12)源端通过cg001这个消费组继续消费ccc001这个topic的数据
共消费了7条数据。
(13)源端cg001这个group的状态

总共有17条消息,0条未被消费
(14)目标端cg001这个group的状态

总共23条数据,6条未被消费。
(15)目标端通过cg001这个消费组继续消费ccc001这个topic的数据

消费了6条数据。
(16)目标端cg001这个group的状态

总共23条数据,0条未被消费。
到这里,基本可以得出结论:group的同步,如果目标端存在此group,则按照增量的方式进行同步;如果目标端不存在此group,则按照全量的方式进行同步。
如果目标端存在生产和消费,则源端的offset和目标端的offset值可能是不相等的。
迁移前后topic的分区消息顺序是否保持一致
MirrorMaker2底层是消费源集群的topic数据并写入到目标集群。源集群的topic各分区消息的offset是否和目标集群对应分区消息的offset匹配。
(1)源集群创建eee001这个topic,5个分区,并往这个topic生产数据。
(2)目标端没有eee001这个topic。
(3)创建MirrorMaker2同步任务,同步eee001这个topic。
(4)5分钟后,停止MirrorMaker2同步任务。
(5-1)消费源端eee001的0号分区

0号分区共2条数据:e3和e8
(5-2)消费目标端eee001的0号分区
0号分区共2条数据:e3和e8
与源端保持一致。
(6-1)消费源端eee001的1号分区
1号分区共2条数据:e4和e9
(6-2)消费目标端eee001的1号分区
1号分区共2条数据:e4和e9
与源端保持一致
(7-1)消费源端eee001的2号分区
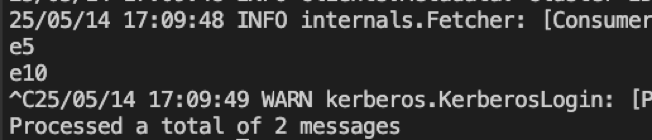
2号分区共2条数据:e5和e10
(7-2)消费目标端eee001的2号分区
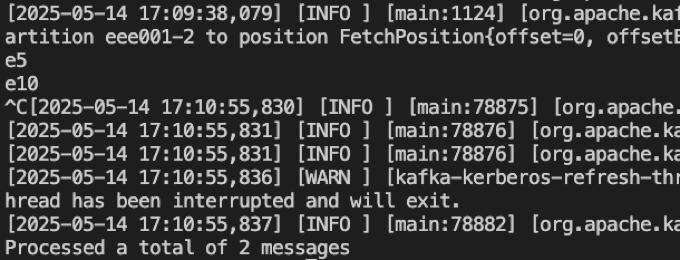
2号分区共2条数据:e5和e10
与源端保持一致
(8-1)消费源端eee001的3号分区

3号分区共2条数据:e1和e6
(8-2)消费目标端eee001的3号分区
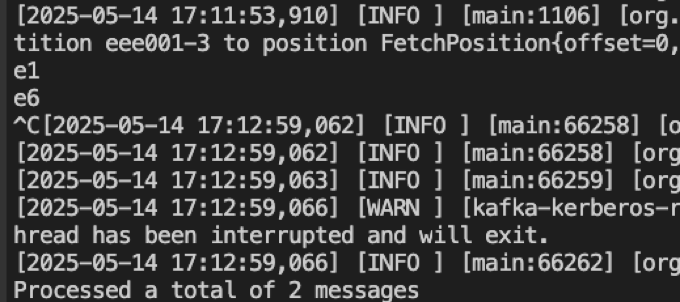
3号分区共2条数据:e1和e6
与源端保持一致
(9-1)消费源端eee001的4号分区

4号分区共2条数据:e2和e7
(9-2)消费目标端eee001的4号分区
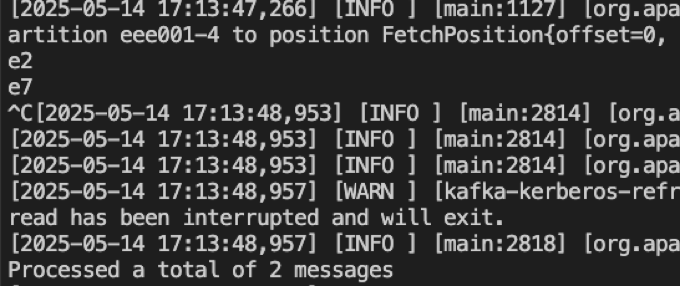
4号分区共2条数据:e2和e7
与源端保持一致
(10)源端eee001的开始offset都是0
(11)目标端eee001的开始offset也都是0
结论:默认情况下,迁移前后分区消息顺序以及消息所在分区保持一致。
分区数据起始offset是否保持一致
比如源端有部分消息已过期,则对应segment的开始offset不为0。同步后,目标端分区的segment起始offset是否是从0开始,还是与源端保持一致。
(1)源端存在bbb001这个topic,起始offset如下所示:
0--->00000000000000000006.log
1--->00000000000000000009.log
2--->00000000000000000006.log
3--->00000000000000000007.log
4--->00000000000000000007.log
共5个分区,log文件大小都是0,表示数据都已过期。
(2)目标端不存在bbb001这个topic
(3)往源端bbb001这个topic生产消息
(4)启动MirrorMaker2任务,配置同步bbb001这个topic
(5)5分钟后,查看目标端对应分区的起始offset信息
0--->00000000000000000000.log
1--->00000000000000000000.log
2--->00000000000000000000.log
3--->00000000000000000000.log
4--->00000000000000000000.log
目标端segment的起始offset与源端不一致。
结论:MirrorMaker2消费源端的数据,并向目标端进行生产数据,这种模式下,目标端的offset与源端offset不一致。
目标端存在同名group
如果目标端和源端都存在同一个group,那么offset信息如何同步?
(1)往源端bbb001这个topic生产消息
共生产了10条消息
(2)源端消费消息,group为cb001,topic为bbb001
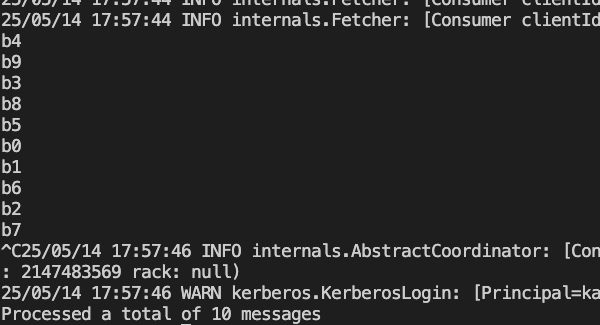
共消费了10条消息
(3)源端cb001 group状态

每个分区对应未被消费的消息数为0
(4)目标端消费消息,group为cb001,topic为bbb001和eee001,消费完成后group状态
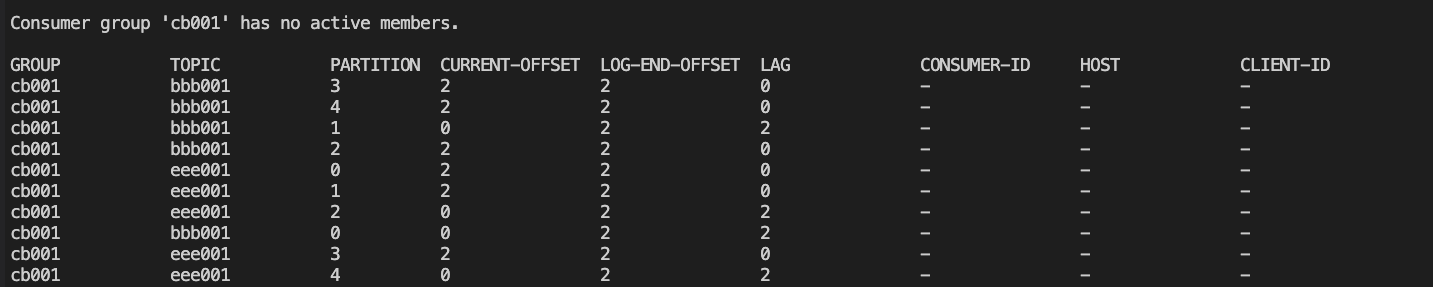
bbb001-0号分区和bbb001-1号分区未被消费的数据量为2
eee001-2号分区和eee001-4号分区未被消费的数据量为2
(5)创建MirrorMaker2同步任务,同步bbb001这个topic和cb001这个group。
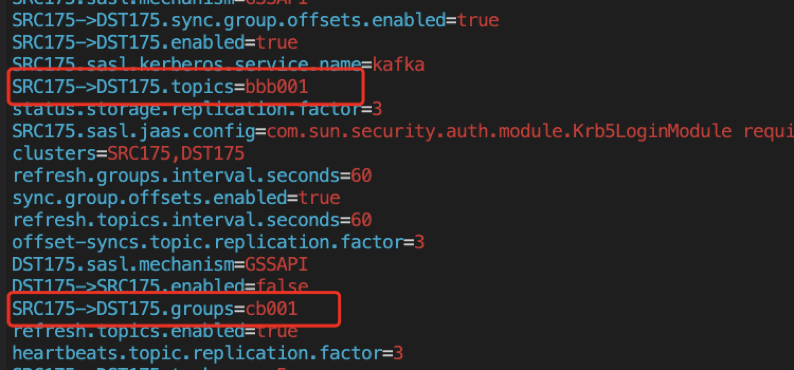
(6)目标端cb001 group状态为

bbb001这个topic每个分区的最新offset都从2调整到了4,因为重新起了一个MirrorMaker2,对应于不同的clusters名称,数据会重新从源端同步到目标端(即第1步中生产的消息)。
因为是第一次同步,所以直接把源端对于bbb001的消费组信息覆盖式同步到目标端,所以bbb001-0号分区和bbb001-1号分区未被消费的数据量变成了0