Kafka的topic由多个分区组成,一个分区可能有多个副本,这些副本有leader和follower角色,leader角色接收客户端和broker的读写请求,follower角色作为备份存在,需要从leader进行消息同步。
1.副本同步机制
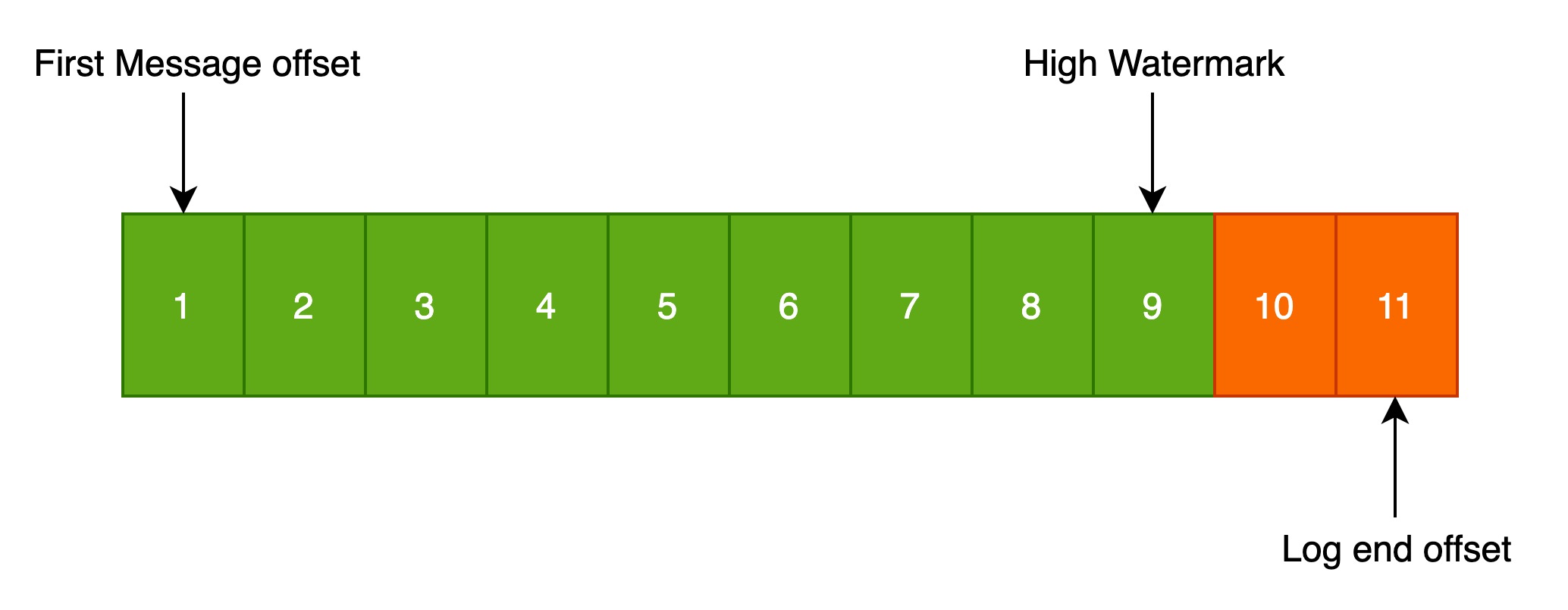
Kafka topic的每个分区有多个日志段,每个日志段对应一个日志文件,在这些日志段中有且仅有一个是可写的。这个可写的日志段承载了这个副本的写的压力,当客户端往这个分区分区生产消息时,生产的消息会被连续地追加到这个可写日志中,日志中的消息是有序的、不可变的。
可写日志文件的结构如下图所示:
kafka topic的每个分区有多个副本,kafka正是通过副本机制实现故障自动转移。当kafka集群中一个broker失效的情况下,副本之间会自动进行选举,重新选举出leader副本,仍然可以保证服务可用。
在kafka发生复制时,需要确保leader副本的新增日志有序地写到其他follower副本节点。在这些副本中,有且仅有一个leader角色,其他都是follower角色。leader所在节点处理对应分区的所有读写请求,同时,follower会被动定期地复制Leader上的数据。
kafka提供了数据复制算法,如果leader发生故障,一个新的leader会被选举出来,并接收客户端的请求。
leader维护了一个ISR(In-Sync Replica),作为当前有效同步副本的集合。有效同步副本延迟时间不能超过replica.lag.time.max.ms。
当producer发送一条消息到broker后,leader写入消息,并复制到所有follower。消息提交成功后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower落后太多或者失败,leader会将他从ISR中删除。
1.1.副本不同步的场景
在以下场景中,常会发生副本不同步,ISR集合缩小的情况。
(1)慢副本:在一定周期内,follower不能追赶上leader。常见的原因有IO瓶颈导致follower追加复制消息慢于从leader拉取的速度。
(2)副本卡住:一定周期内,follower停止从leader拉取请求。follower replica卡住可能是GC暂停或者follower失效或者死亡。
(3)新启动副本:当用户给topic增加副本因子时,新的follower不在ISR中,直到追赶上leader的日志。
2.ISR管理机制
默认情况下,kafka topic的副本数为1,即每个分区仅有一个副本且是leader角色。为了确保消息的可靠性,通常将副本数挑战为大于1的整数。
2.1.ISR与AR、OSR
一个分区的所有副本称为AR(Assigned Replicas)。ISR是AR的一个子集,由leader维护ISR列表,follower从leader同步数据有一些延迟,任意一个超过阈值都会把follower剔出ISR,存入OSR(Out-of-Sync Replicas)列表,新加入的follower也会先放到OSR中。
AR = ISR + OSR2.2.HW——高水位
HW全称High Watermark,俗称高水位,取一个分区对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置。
另外每个replica都有HW,leader和follower个字负责更新自己的HW的状态。
对于leader新写入的消息,consumer不能立即消费,leader会等待该消息写入ISR中的replicas都同步后,才更新HW,此消息才能被consumer消费,这样就保证了如果leader所在的broker不可用,该消息仍可从新选举的leader中获取。
对于集群内部的broker读取请求,并没有HW的限制。
2.3.LEO
LEO全称Log end offset,表示当前副本最新的一条消息。
2.4.副本同步过程演示
如下图所示:
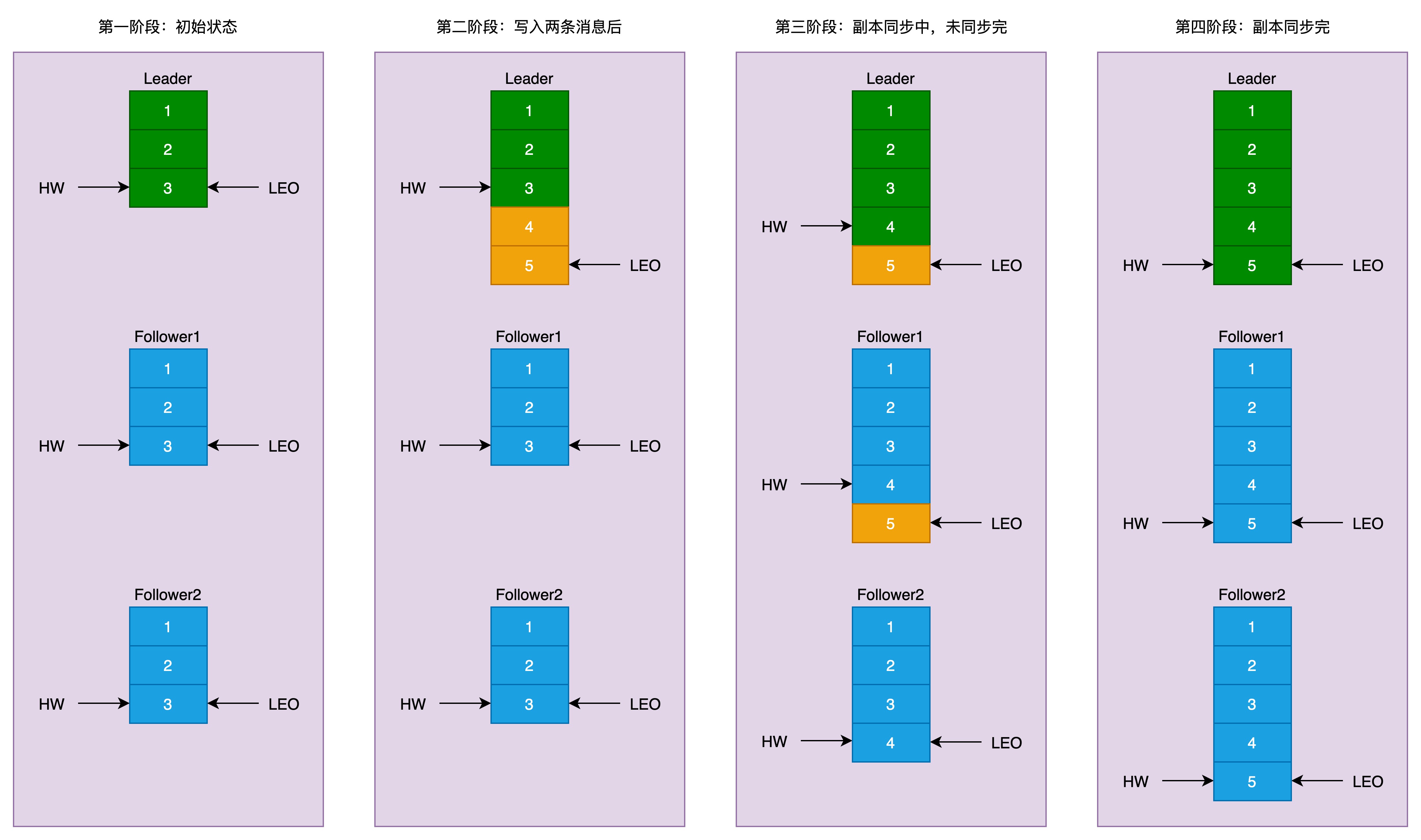
上图表示一个分区的副本演示,一个leader,两个follower。
3.副本同步源码解析
ISR信息作为元数据,保存在zookeeper的/brokers/topics/{topic}/partitions/{partitionId}/state节点上。这个zknode信息的维护有两个部分:
(1)KafkaController:集群中有一个Broker会被选举为Controller,主要负责分区管理和副本管理。在某些条件下,KafkaController中的LeaderSelector会选举新的leader、ISR和新的leader_epoch及controller_epoch写入zknode。同时发起LeaderAndIsrRequest通知所有的replicas。
(2)Leader Replica:Leader中有单独的线程定期检查ISR中follower是否脱离ISR,如果发现ISR变化,则会将新的ISR信息写入到zknode中。
3.1.zknode监听事件注册过程
当KafkaController重新选举或启动时,在/brokers/topics/{topic}/partitions/{partitionId}/state节点上注册监听器PartitionReassignmentIsrChangeListener
KafkaController的Reelect或Startup事件触发
ControllerEvent.process()
KafkaController.elect()
创建zknode(/controller),写入当前controller的信息
KafkaController.onControllerFailover()
KafkaController.maybeTriggerPartitionReassignment // 在手动启动分区充分时,也会调用此方法
KafkaController.initiateReassignReplicasForTopicPartition
KafkaController.watchIsrChangesForReassignedPartition
构建监听器PartitionReassignmentIsrChangeListener // 回调函数在PartitionReassignmentIsrChange中
获取监听的zknode,ZkUtils.getTopicPartitionLeaderAndIsrPath
返回zknode(/brokers/topics/{topic}/partitions/{partitionId}/state)
绑定Listener和ZkNode至于PartitionReassignmentIsrChangeListener的处理过程,可参考源码。
3.2.主动检查ISR的过程
KafkaServer启动时会启动定时器,定时主动检查ISR的变化。
KafkaServer.startup
KafkaServer.createReplicaManager
ReplicaManager.startup()
scheduler.schedule("isr-expiration", maybeShrinkIsr) // 周期为replica.lag.time.max.ms配置值的一半
scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges) // 周期2.5秒maybePropagateIsrChanges处理过程如下所示:
ReplicaManager.maybePropagateIsrChanges
ReplicationUtils.propagateIsrChanges
创建zknode(/isr_change_notification/isr_change_{})创建完新的zknode后,由其他监听器进行处理。
maybeShrinkIsr处理过程如下所示:
ReplicaManager.maybeShrinkIsr
//评估哪些replica需要被移出ISR,数据是缓存数据
Partition.getOutOfSyncReplicas // 获取不同步的Replica
对于非Leader Replica,如果当前时间与上次成功fetch的时间大于replica.lag.time.max.ms配置值,才会被移除
ReplicaManager.updateIsr
ReplicationUtils.updateLeaderAndIsr
ZkUtils.conditionalUpdatePersistentPath // 更新zk上的数据3.3.LeaderAndIsrRequest请求处理过程
当replicas接收到KafkaController发送的LeaderAndIsrRequest通知请求时,进行如下处理:
KafkaApis.handleLeaderAndIsrRequest
ReplicaManager.becomeLeaderOrFollower
ReplicaManager.makeLeaders // 如果是成为leader
ReplicaManager.makeFollowers // 如果是成为fellower
ReplicaFetcherManager.addFetcherForPartitions
检查fetcherThreadMap是否有对应的Fetcher,key值为leader所在节点的broker.id和生成的fetcherId决定
fetcherId的生成逻辑为:Utils.abs(31 * topic.hashCode() + partitionId) % numFetchers
numFetchers由num.replica.fetchers参数决定,默认值为1
如果fetcherThreadMap存在对应的Fetcher
如果broker.host和broker.port是相同的,则复用该Fetcher
如果broker.host和broker.port不一致,则当前停止当前Fetcher,并创建新的Fetcher
Fetcher.shutdown
AbstractFetcherManager.addAndStartFetcherThread
如果fetcherThreadMap不存在对应的Fetcher,则创建新的Fetcher
AbstractFetcherManager.addAndStartFetcherThread
创建ReplicaFetcherThread线程,线程名称带有“ReplicaFetcherThread-${fetcherId}-${sourceBroker.id}”
启动对应的ReplicaFetcherThread线程
将已创建的ReplicaFetcherThread线程记录到fetcherThreadMapReplicaFetcherThread线程中循环执行doWork(),doWork逻辑如下:
ReplicaFetcherThread.doWork()
创建FetchRequest请求对象
maxWait = replica.fetch.wait.max.ms
minBytes = replica.fetch.min.bytes
maxBytes = replica.fetch.response.max.bytes
fetchSize = replica.fetch.max.bytes
固定隔离级别IsolationLevel.READ_UNCOMMITTED
如果fetchRequest对象为空,则等待replica.fetch.backoff.ms时间,默认为1秒。
如果fetchRequest对象不为空,则执行以下逻辑
ReplicaFetcherThread.processFetchRequest
ReplicaFetcherThread.fetch
向Leader所在Broker发送FetchRequest请求3.4.FetchRequest请求处理过程
KafkaServer接收到FetchRequest请求后,进行如下处理:
KafkaApis.handleFetchRequest
ReplicaManager.fetchMessages
ReplicaManager.readFromLocalLog
从磁盘读取数据这里会用到FetchRequest调用方设置的maxWait、minBytes、maxBytes和隔离级别等参数。