1.Livy概述
Livy是Cloudera开发的通过REST来连接、管理Spark的解决方案。它提供了一种经过restful接口进行交互式spark任务的机制,通过它能够进一步开发交互式的应用。
一般来说,提交Spark任务有两种方式:
(1)通过spark-shell编写交互式的代码。
(2)通过spark-submit提交编写好的jar包到集群上运行,执行批处理任务。
为了简化spark任务的提交方式,Livy把交互式和批处理都搬到了web上,通过restful api来提交。其中,livy sessions接口处理交互式请求,livy batches接口处理批处理请求。这两种方式与原生的spark类似,其中交互式会话他们的主要不同点是:spark-shell会在当前节点上启动REPL来接收用户的输入,而Livy交互式会话则是在远端的Spark集群中启动REPL,所有的代码、数据都需要通过网络来传输。
1.1.Livy基本架构
基本架构如下图所示:
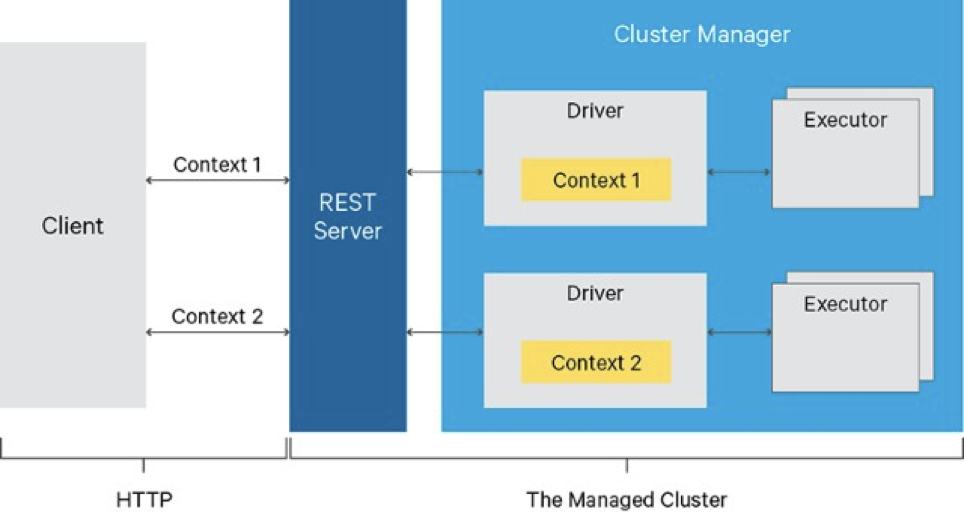
由Rest Server提供Restful api进行spark任务操作。
1.2.Livy的优点
Livy主要有以下优点:
(1)由多个客户端长时间运行可用于多个Spark作业的Spark上下文。
(2)跨多个作业和客户端共享缓存的RDD或数据帧
(3)可以同时管理多个Spark上下文,并且Spark上下文运行在群集上(YARN / K8s)而不是Livy服务器,以实现良好的容错性和并发性.
(4)作业可以作为预编译的jar,代码片段或通过java / scala客户端API提交
(5)通过安全的认证通信确保安全
(6)Livy可以在WEB/Mobile中提交(不需要Spark客户端)可编程的、容错的、多租户的Spark作业,因此,多个用户可以并发的、可靠的与Spark集群进行交互
(7)Livy可以使用Scala或者Python语言,因此客户端可以通过远程与Spark集群进行通讯,此外,批处理作业可以在Scala、java、python中完成
1.3.Livy的缺点
Livy主要有以下缺点:
(1)无法支持高可用。
(2)不支持多租户。
2.Livy核心流程
Livy中有以下核心流程。
2.1.Livy session创建流程
Livy Session创建流程如下图所示:
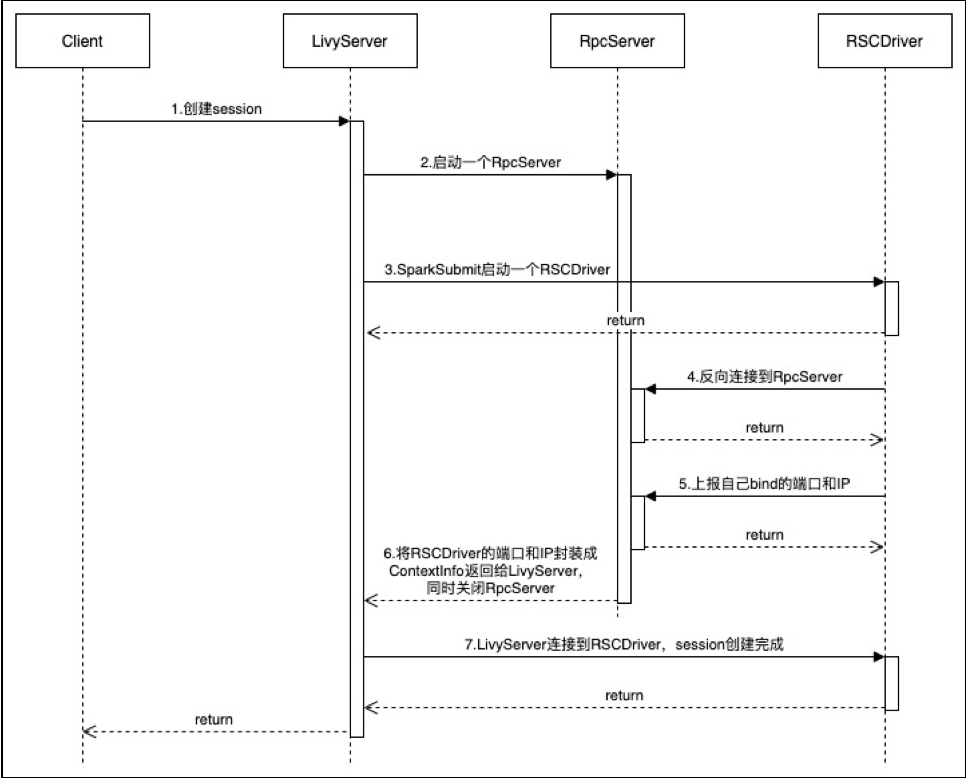
可以分为以下7个步骤:
(1)客户端创建session,LivyServer收到请求后启动一个RpcServer。RpcServer会顺序选择一个从10000~10010之间的可用端口启动监听,假设此时是10000。
(2)LivyServer随后通过SparkSubmit提交Application。Application在远端,最终会启动RSCDrvier。
(3)RSCDrvier首先也从10000~10010之间顺序选择一个可用的端口,启动RpcServer。假设此时端口为10001。如果启动成功,一般打出以下关键的日志。
INFO driver.RSCDriver: Starting RPC server……
INFO ppc.RpcServer: Connected to the port 1001(4)RSCDrvier完成bind后,反向连接到LivyServer端的RpcServer。如果连接成功,也会打印出关键的日志,日志如下所示:
INFO driver.RSCDriver: Connecting to: vm3198:10000(5)RSCDrvier主要向LivyServer所在的RpcServer上报自己bind的端口和ip。这一步其实就是最关键的步骤。
(6)RpcServer收到请求后将RSCDrvier的端口和ip封装成ContextInfo返回给LivyServer。同时关闭RpcServer。也就是到这一步为止,RpcServer生命就结束了。
(7)LivyServer通过RSCDrvier的端口和ip连接到RSCDriver,从而完成tcp连接。至此session建立完成。
至于LivyServer与RSCDriver之间的关系,可以通过下面这张图来说明。
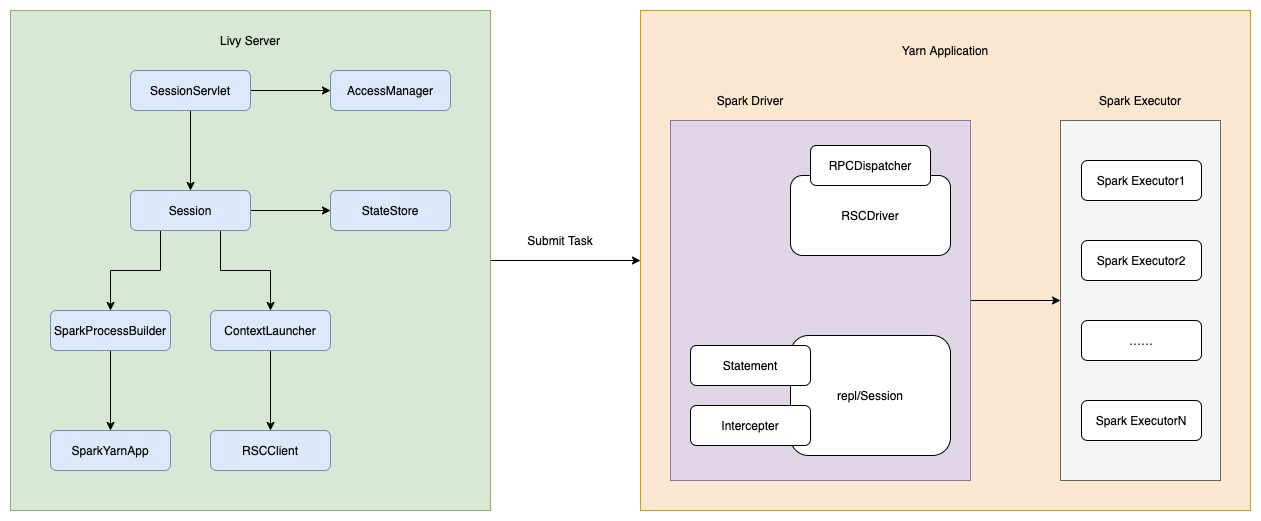
RSCDriver与LivyServer一般不在同一个服务器上。
2.2.Livy任务提交流程
Livy任务提交过程如下所示:
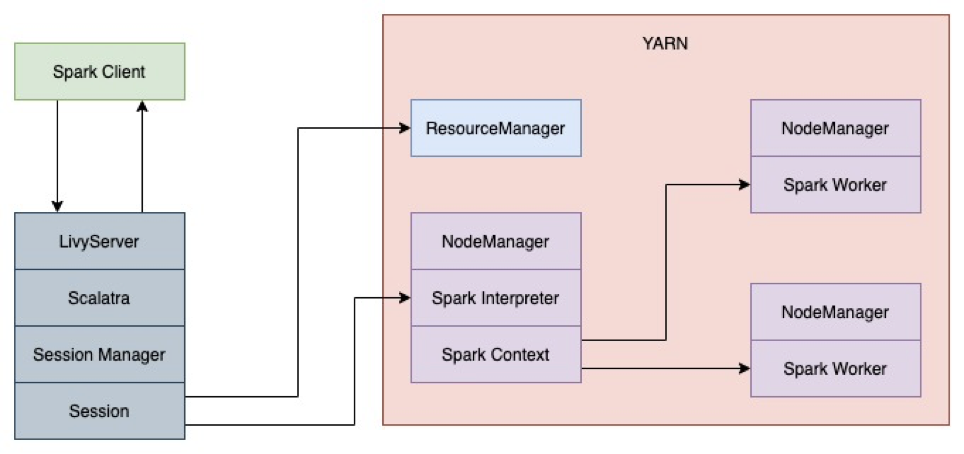
第一步:启动LivyServer,启动过程会相应地启动BatchSessionManager和InteractiveSessionManager。初始化WebServer,通过ServletContextListener启动InteractiveSessionServlet和BatchSessionServlet。
第二步:SparkClient调用sessions接口提交任务,后台会调用SessionServlet的createSession接口,出啊功能就爱你session并注册到sessionManager,InteractiveSession和BatchSession会创建SparkYarnApp,SparkYarnApp负责启动Spark作业,并维护YarnClient,获取作业信息、状态或kill作业。
BatchSession是以jar包的方式提交作业,运行结束后session就结束了。
InteractiveSession会启动ReplDriver,ReplDriver继承自RSCDriver,初始化期间会通过RPC连接到LivyServer,并启动RpcServer;其次会初始化Interpreter(支持PythonInterpreter,SparkInterpreter,SparkRInterpreter)。接收来自livy-server的信息(代码),然后通过Interpreter执行,livy-server通过RPC请求作业结果。
3.Livy提供的接口
Livy中,我们有三种方式给Livy提交任务:
(1)使用Programmatic API,通过程序接口提交作业。作业需要继承自org.apache.livy.Job接口,通过LivyClient提交。
(2)使用RestAPI的sessions接口提交代码段方式运行。
(3)使用RestAPI的batches接口提交jar包方式运行。
3.1.使用Programmatic API
作业需继承自org.apache.livy.Job接口。添加以下依赖:
<dependency>
<groupId>org.apache.livy</groupId>
<artifactId>livy-client-http</artifactId>
<version>0.7.0-incubating</version>
</dependency>具体可参考https://livy.incubator.apache.org/docs/latest/programmatic-api.html。
3.2.使用RestAPI的session接口
主要是针对交互式任务的执行。包含以下10个接口:
(1)GET /sessions
Returns all the active interactive sessions.
(2)POST /sessions
Creates a new interactive Scala, Python, or R shell in the cluster.
(3)GET /sessions/{sessionId}
Returns the session information.
(4)GET /sessions/{sessionId}/state
Returns the state of session
(5)DELETE /sessions/{sessionId}
Kills the Session job.
(6)GET /sessions/{sessionId}/log
Gets the log lines from this session.
(7)GET /sessions/{sessionId}/statements
Returns all the statements in a session.
(8)POST /sessions/{sessionId}/statements
Runs a statement in a session.
(9)GET /sessions/{sessionId}/statements/{statementId}
Returns a specified statement in a session.
(10)POST /sessions/{sessionId}/statements/{statementId}/cancel
Cancel the specified statement in this session.
3.3.使用RestAPI的batch接口
主要是提交批量任务(离线任务),包含以下6个接口:
(1)GET /batches
Returns all the active batch sessions.
(2)POST /batches
提交批量任务
(3)GET /batches/{batchId}
Returns the batch session information.
(4)GET /batches/{batchId}/state
Returns the state of batch session
(5)DELETE /batches/{batchId}
Kills the Batch job.
(6)GET /batches/{batchId}/log
Gets the log lines from this batch.