存储系统的基本功能包括:增、删、读、改。读操作又可分为随机读取和顺序扫描。
哈希存储引擎是哈希表的持久化实现,支持增、删、改和随机读取操作,不支持顺序扫描操作。对应的存储系统为键值(Key-Value)存储系统。
Bitcask是一个基于哈希表结构的键值存储系统。下面我们就以Bitcask为例,了解哈希存储的原理。
1.Bitcask简介
Bitcask是一种“基于日志结构的哈希表”(A Log-Structured Hash Table for Fast Key/Value Data)。
Bitcask系统中,每个文件有一定的大小限制,当文件增加到相应大小时,就会产生一个新的文件,老的文件只读不写。
在任意时刻,只有一个文件是可写的,用于数据追加,称为活跃数据文件(active data file)。其他达到大小限制的文件,称为老数据文件(older data file)。
2.Bitcask存储数据结构
哈希存储数据结构可用下图来表示:
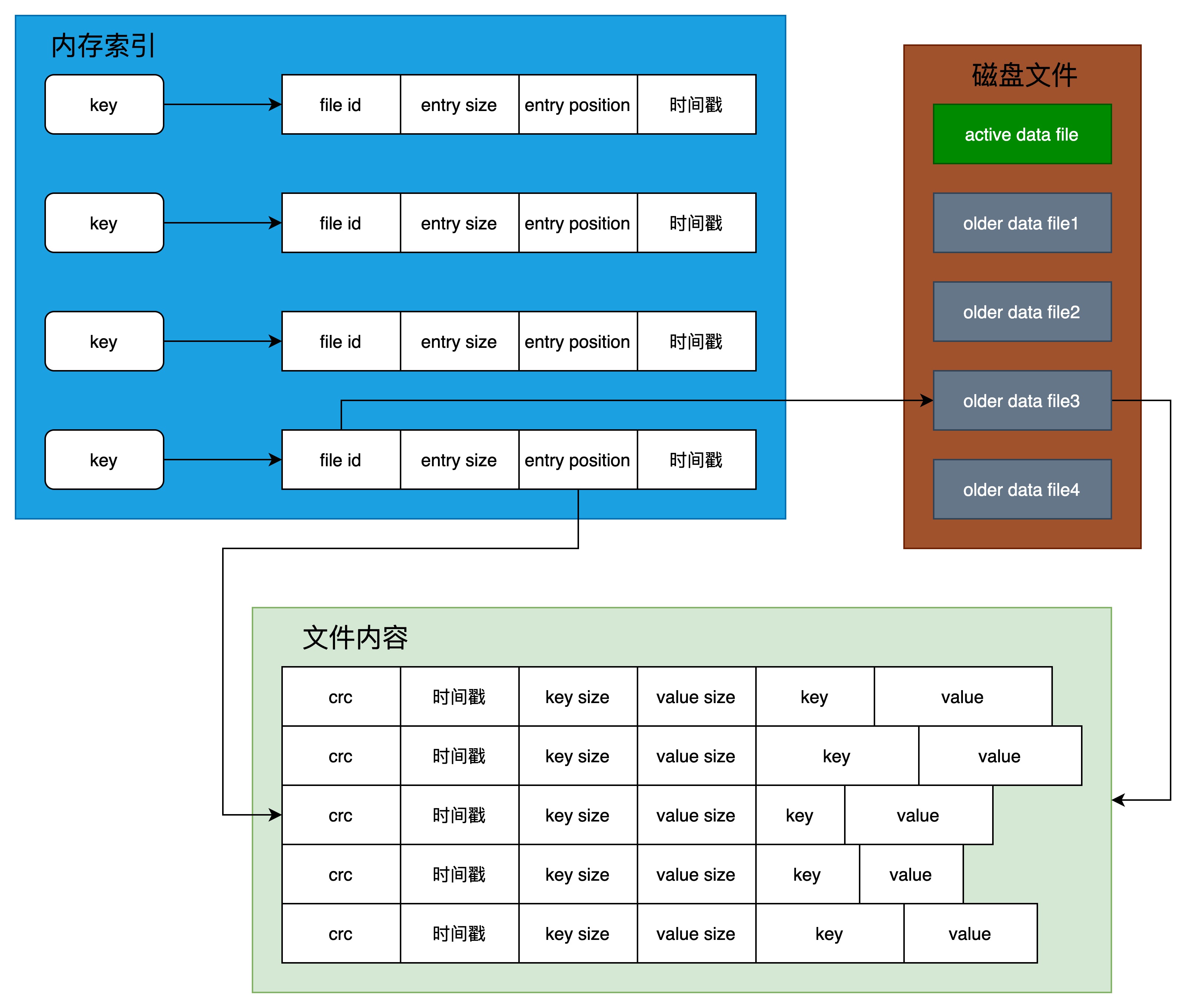
2.1.数据记录格式
Bitcask数据文件中的数据是一条一条写入的,每条记录称为一个entry,每个entry的结构如下图所示:

每条记录分为6个部分:
(1)crc校验值
(2)时间戳
(3)主键长度——key size
(4)值长度——value size
(5)主键——key
(6)值内容——value
数据删除操作并不会删除数据记录,而是新增一条记录,把value设置为一个特殊值作为标记。
2.2.索引格式
索引存储是以哈希表数据结构的形式存储在内存中,哈希表的作用是快速地通过key定位到value所在的位置。
哈希表中每条记录称为一个索引,即index,格式如下图所示:

每条索引由以下5部分组成:
(1)主键——key
(2)文件编号——file id,可通过文件编号定位到磁盘中的数据文件
(3)每条记录内容长度——entry size
(4)记录在数据文件中的位置——entry position,通过entry position和entry size可直接从数据文件中读取对应数据记录。
(5)时间戳
3.Bitcask操作流程
bitcask的整个流程非常简单,且非常高效,整体的IO次数是可控的。
3.1.写流程
接收到key和value之后,根据key和value,构建index的数据结构和entry的数据结构。将entry以append的方式写入文件,写入成功之后再更新内存中的index。
3.2.读流程
拿到key之后,根据key查找内存中的index,index中保存了file id、entry size、entry position等信息,据此可以定位到entry数据所在文件位置,可通过一次IO读取出整个entry数据,再根据定长的元数据信息,解析出value。
3.3.删除流程与修改流程
删除流程与修改流程一致,都是先构建entry写入文件再更新index,区别在于删除流程是通过墓碑值的方式构建entry,构建时不需要写入value数据,且需要删除索引。
本质上,bitcask只有读、写两种操作,而没有修改、删除的操作。
3.4.数据文件新增
当前文件大小超过设定大小时,需要将当前文件转为非活跃文件,同时文件id自增,生成一个新的文件,新数据写入新的文件,旧文件只提供读操作。
4.Bitcask运维操作
Bitcask中有两个重要的运维操作
4.1.垃圾数据的合并
Bitcask系统中的记录删除或者更新后,原来的记录就成为了垃圾数据。如果这些数据一直保存下去,文件就会无限膨胀。
为了解决这个问题,Bitcask需要定期执行合并(compaction)操作,实现垃圾数据的清理。
所谓合并操作,就是将所有older data file中的数据扫描一遍,并生成新的数据文件,这里的合并其实就是对同一个key的多个记录,只保留最新的记录,或者删除。
合并操作后,新生成的数据文件就不再有冗余数据了。
4.2.系统故障恢复
Bitcask系统中的哈希索引存储在内存中,如果没有其他机制保障,那么服务器断电重启后将重建哈希表,需要扫描一遍所有的数据文件。如果数据文件很大,那么这是一个非常耗时的过程。
Bitcask通过索引文件(hint file)来提高重建哈希表的速度。
索引文件就是将内存中的哈希索引表转储到磁盘而生成的结果文件。Bitcask对老数据进行合并时,会生成新的数据文件,同时也伴随着一个索引文件,这个索引文件记录每一条哈希索引的信息,跟内存中的哈希索引内容相同。
当系统故障恢复重建哈希表时,就不需要扫描所有的数据文件,只需要将索引文件加载到内存中即可,大大降低了恢复时间。
5.Bitcask适用场景
bitcask相对适合海量小文件的场景,基于此,bitcask的key和value都不适宜太大, 以免因为较大的数据块降低IOPS。
虽然bitcask的特性支持海量小文件,但是对于海量而言,需要打个引号。因为bitcask需要将全部的索引信息写入内存,故而实际的数据条目数受内存限制。假设以一个index占内存32B为例,每GB内存可以存放3355万条数据(1024*1024*1024/32),假设每条数据4KB,每GB内存所需存储也仅为128GB,更何况实际应用中,为了追求高吞吐量,每条数据并不一定能有4KB的大小,与现在动则数T、数十T的存储而言,其数据量瓶颈实际还是在内存上。