Flink内部机制也就是Flink的内核,是Flink中极其重要的内容。
1.Flink状态管理
Flink中的状态分为以下三种:算子状态(Operator State)、键控状态(Keyed State)、状态后端(State Backends)。
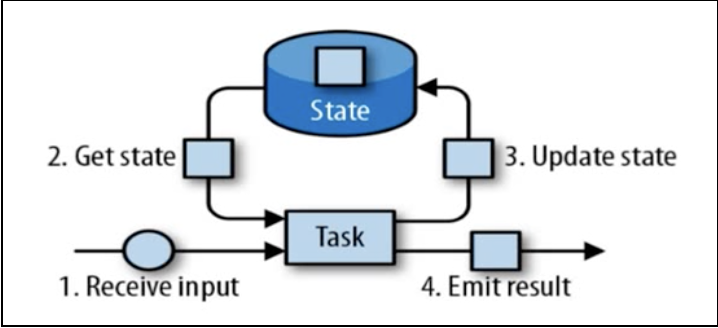
Flink中的状态有一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态。可以认为状态就是一个本地变量,可以被任务的业务逻辑访问。Flink会进行状态管理,包括状态一致性、故障处理、以及高效存储和访问。
1.1.算子状态
算子状态的作用范围限定为算子任务。算子状态有三种数据结构:
列表状态:List state,讲状态表示为一组数据的列表。
联合列表状态:Union list state,将状态表示为数据的列表,它与常规列表状态的区别在于——在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
广播状态:Broadcast state,如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
1.2.键控状态
键控状态根据输入数据流中定义的键来维护和访问。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。键控状态有以下四种数据结构:
值状态:Value state,将状态表示为单个的值。
列表状态:List state,将状态表示为一组数据的列表。
映射状态:Map state,将状态表示为一组Key-Value对。
聚合状态:Reducing state&Aggregating state,将状态表示为一个用于聚合操作的列表。
与算子状态不通的是,键控状态只能在rich function中使用。
1.3.状态后端(State Backends)
每传入一条数据,有状态的算子任务都会读取和更新状态。
由于有效的状态访问对于处理数据的延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速地状态访问。
状态的存储、访问及维护,是由一个可插入的组件决定,这个组件就叫做状态后端。状态后端主要负责两件事:本地状态管理,以及将检查点(checkpoint)状态写入远程存储。
2.ProcessFunction
这是flink中最底层的api。我们之前学的转换算子无法访问事件的时间戳和watermark信息。而ProcessFunction可以访问数据的所有属性,并对数据进行处理。
3.Flink容错机制
Flink故障恢复的核心就是应用状态的一致性检查点。
3.1.一致性检查点(checkpoints)
有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
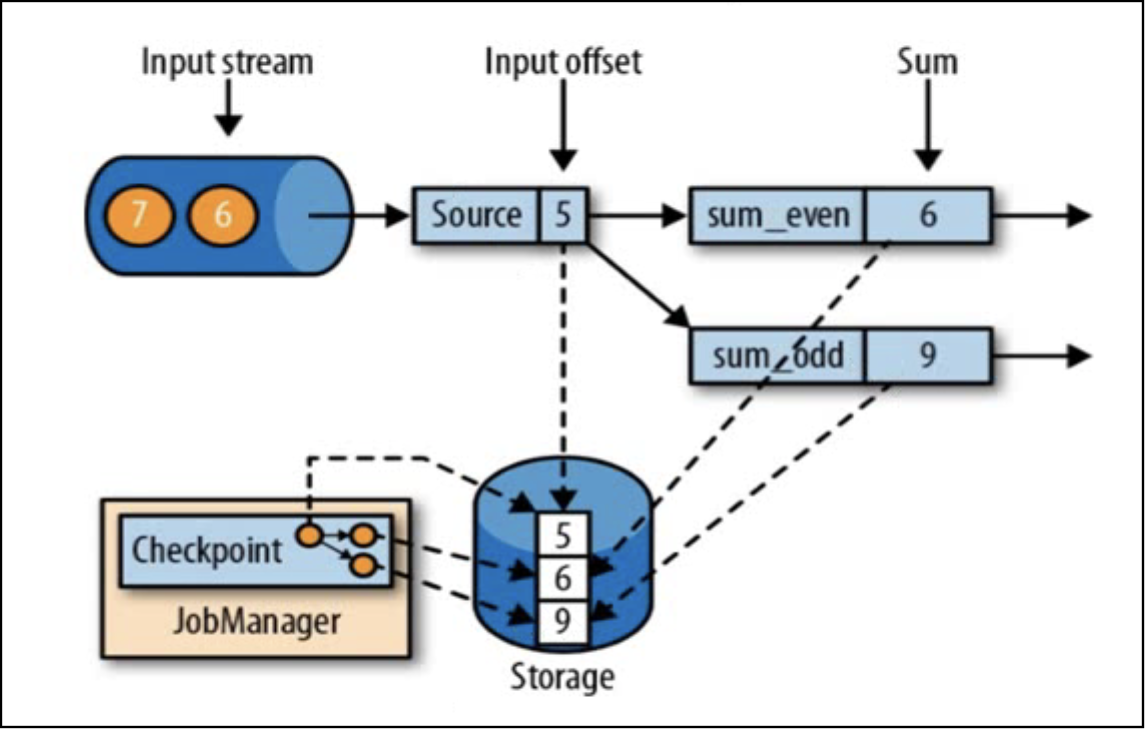
checkpoint保存的不是数据,而是当前任务正在处理数据所处的状态,例如kafka的offset。
3.2.检查点的实现算法
有以下两种思路。
一是暂停应用,保存状态到检查点,再重新恢复应用。这种方法简单粗暴,这会影响系统的实时处理的延迟特性。
二是基于Chandy-Lamport算法的分布式快照,将检查点的保存和数据处理分离开,不暂停整个应用。
检查点分界线——Checkpoint Barrier,是一种特殊的数据形式,用来把一条流上的数据按照不同的检查点分开。分界线之前到来的数据导致的状态变更,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有变更,都会被包含在之后的检查点中。
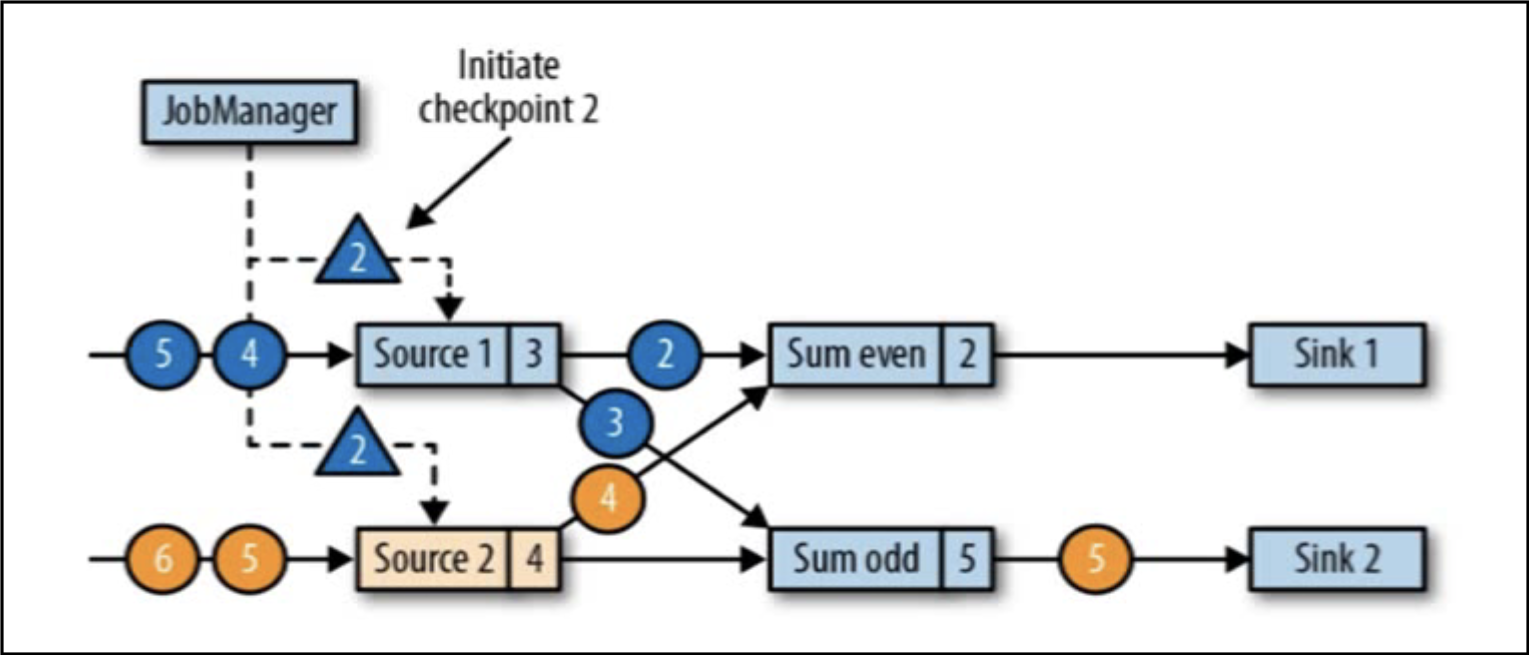
如上所示的检查点机制分为以下几步:
(1)JobManager会向每个source任务发送一条带有新检查点ID的消息,通过这种方式来启动checkpoint。
(2)数据源将source的状态写入检查点,并发出一个checkpoint barrier。
(3)状态后段在状态存入检查点后,会返回通知给source任务,source任务就会向JobManager确认检查点完成。
(4)barrier向下游传递,后续任务会等待所有输入分区的barrier到达,对于barrier已经到达的分区,继续到达的数据会被缓存,而barrier尚未到达的分区,数据会被正常处理。
(5)当收到所有输入分区的barrier时,任务就将起状态保存到状态后段的检查点中,然后将barrier继续向下游转发。
(6)Sink任务向JobManager确认状态保存到checkpoint完毕,检查点就真正完成了。
3.3.保存点(Savepoints)
Flink提供了可以自定义的镜像保存功能,这就是savepoints。
原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点。
Flink不会自动创建savepoints,需要用户明确触发创建操作。
Savepoints是一个强大的功能,除了故障恢复外,还可用于:有计划的手动备份、更新应用程序、版本前一、暂停和重启应用等等。
3.4.Checkpoint使用案例
checkpoint的设置案例如下所示:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//检查点配置
//开启checkpoint,每隔30秒进行一次checkpoint
env.enableCheckpointing(30000L);
//检查点高级配置
//设置checkpoint的模式,EXACTLY_ONCE表示确保每条记录只处理一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint的超时是时间,如果超过60秒,则此次checkpoint超时,即失败
env.getCheckpointConfig().setCheckpointTimeout(60000L);
//设置checkpoint的并行度,表示同一时间最多有多少个checkpoint在进行。
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//设置前一次checkpoint完成的时间与下一次checkpoint开始的最小时间间隔为2秒
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(2000L);
//更偏向于使用checkpoint来进行状态恢复,而不是savepoint
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
//设置可容忍checkpoint失败的最多次数,当失败次数超过此值时,任务失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
//重启策略配置
//固定延迟重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000L));
//失败率重启
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(10), Time.minutes(1)));4.状态一致性
对于有状态的流处理,每个算子都可以有自己的状态。从流处理器内部来说,状态一致性就是计算结果保证准确。一条数据不应该丢失,也不应该重复计算。在遇到故障时可以恢复状态,恢复以后的冲洗计算,结果应该也是完全正确的。
4.1.一致性分类
分为以下三类:
(1)AT-MOST-ONCE:最多一次,最多处理一次事件。当任务故障时,最简单的做法是什么都不做,即不恢复丢失的状态,也不重播丢失的数据。
(2)AT-LEAST-ONCE:至少一次。在大多数的真实场景中,我们希望不要丢失事件。所有的事件都至少处理一次,可能被处理多次。
(3)EXACTLY-ONCE:有且仅有一次。这是最严格的保证,也是最难实现的。保证事件不丢失,且针对每一条数据,内部状态仅更新一次。
4.2.端到端exactly-once的实现策略
端到端的状态一致性由流处理器实现,也就是在Flink流处理器内部保证的。而在真实应用中,流处理应用处理流处理器还包含了数据源和输出到持久化系统。端到端的一致性保证意味着结果的正确性贯穿了整个流处理应用的始终,每个组件都保证了它自己的一致性。端到端的一致性级别取决于所有组件中一致性最弱的组件。
对于exactly-once的实现策略,需要提供以下三个保证:
(1)内部保证:通过checkpoint实现。
(2)source端:可重设数据的读取位置。
(3)sink端:从故障恢复时,数据不会重复写入外部系统。实现方法有两种——幂等写入和事务写入。
4.3.幂等写入(Idempotent Write)
所谓幂等写入,是说一个操作,可以重复执行很多次,但只导致一次结果更改。来源于一个公式,如下图所示,对自然常数e的x次方求n阶导数,都是自身。
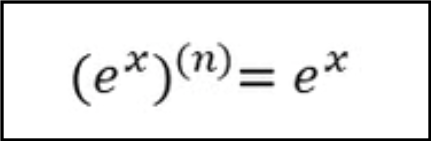
最常见的幂等写入的案例是对hashmap的写入,对同一个(key,value),无论写入多少次,结果都不会发生变化。
4.4.事务写入(Transactional Write)
应用程序中的一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤销。
事务写入的实现思想是:构建的事务对应着checkpoint,等到checkpoint真正完成的时候,才把所有对应的结果写入到sink系统中。
事务写入的实现方式有两种:预写日志和两阶段提交。
4.4.1.预写日志(Write-Ahead-Log,WAL)
预写日志就是把结果数据先当成状态保存,然后在收到checkpoint完成的通知时,一次性写入Sink系统。DataStream API中提供了一个模板类——GenericWriteAheadSink——来实现这种事务性sink。此方式简单易于实现,数据提前在状态后端做了缓存,无论什么sink系统,都能用这种方式一批搞定。
4.4.2.两阶段提交(Two-Phase-Commit,2PC)
两阶段提交中,对于每一个checkpoint,sink任务都会启动一个事务,并将接下来所有接收的数据添加到事务中;然后将这些数据写入到外部的Sink系统,但不提交它们,只是“预提交”;当它收到checkpoint完成的通知时,它才正式提交事务,实现结果的真正写入。
4.4.3.事务写入方式的比较
WAL方式中有数据的重放,还是会有写入多次的问题,无法做到exactly-once。2PC真正实现了exactly-once,它需要一个提供事务支持的外部Sink系统,Flink提供了TwoPhaseCommitSinkFunction接口。
4.5.不同source和sink的一致性保证
如下图所示:
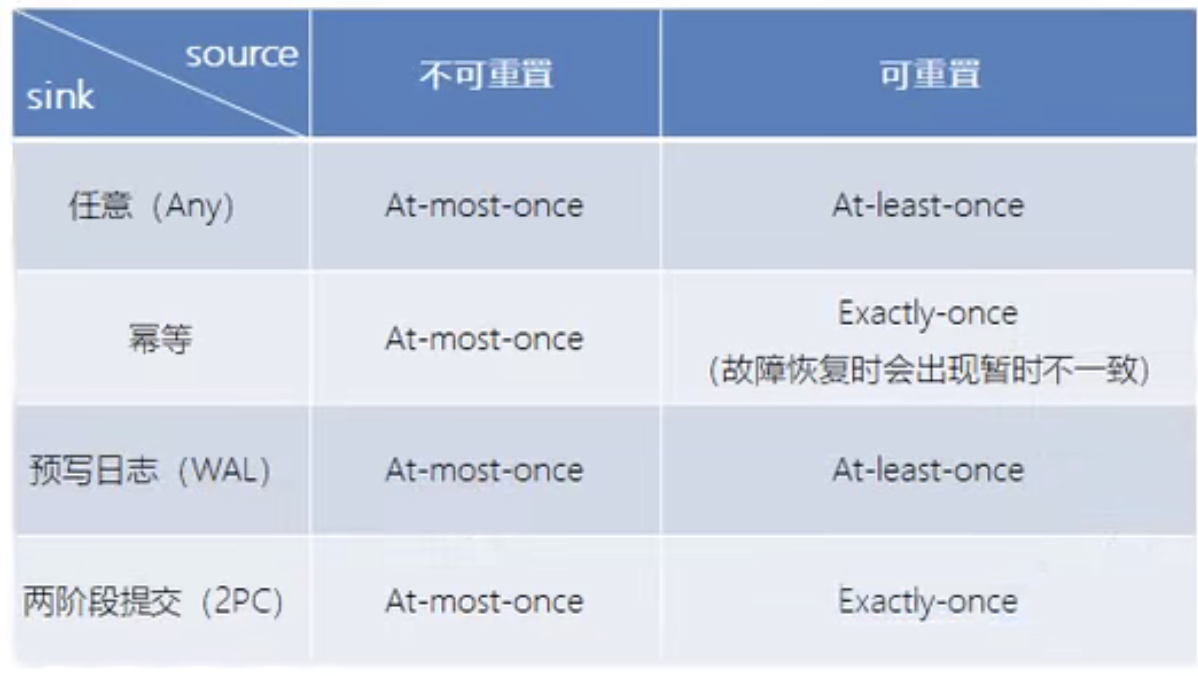
Flink+kafka是端到端状态一致性保证的最佳实践。
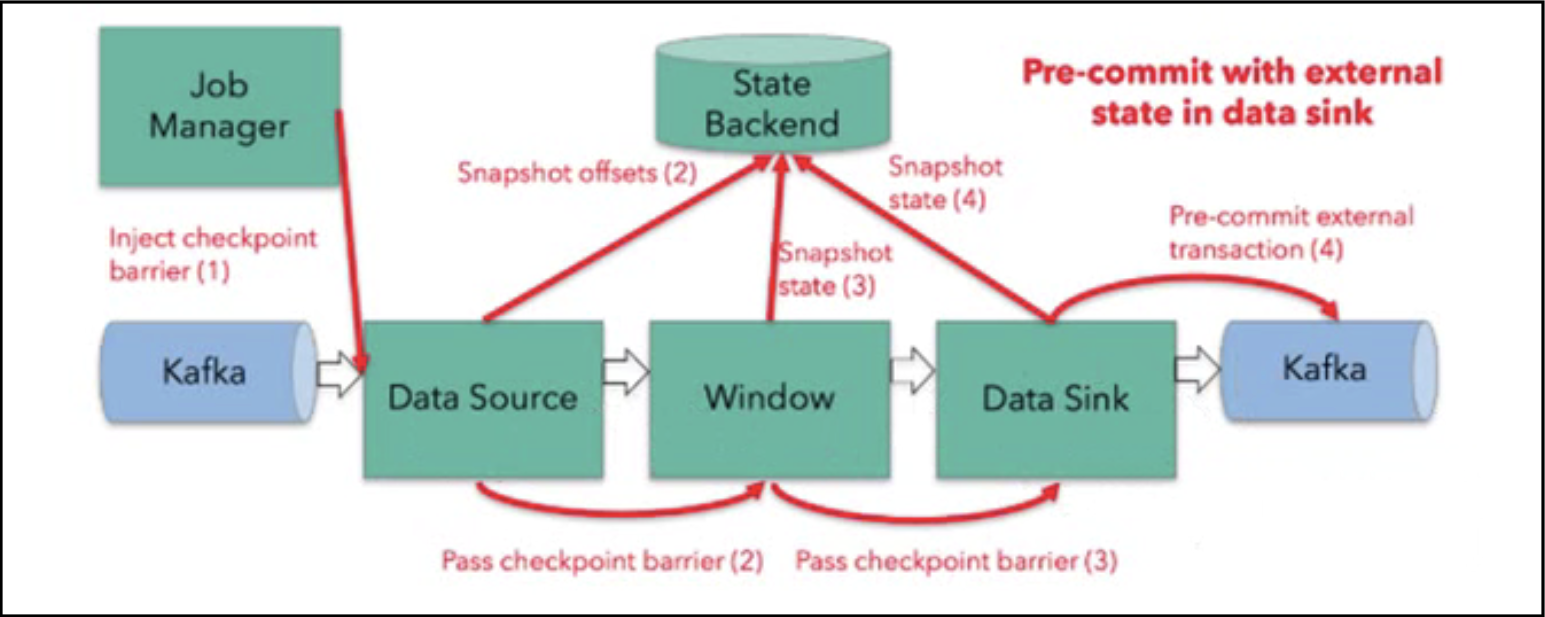
4.6.Exactly-Once两阶段提交
分为以下步骤:
(1)第一条数据来了后,开启一个kafka的事务(transaction),正常写入kafka分区日志但标记为未提交,这就是“预提交”。
(2)JobManager触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知JobManager。
(3)Sink连接器收到barrier,保存当前状态,存入checkpoint,通知JobManager,并开启下一阶段的事务,用于提交下个checkpoint的数据。
(4)JobManager收到所有任务的通知,发出确认信息,表示checkpoint完成。
(5)Sink任务收到JobManager的确认信息,正式提交这段时间的数据。
(6)外部kafka关闭事务,提交的数据可以正常消费。
过程如下图所示: