LSM概述
LSM Tree全称Log Structured-Merge Tree,译为日志结构的合并树。
LSM是一种文件组织,作为主要的文件组织策略在许多产品中使用,比如HBase、LevelDB、Cassandra、SQLite、甚至MongoDB 3.0都在收购的Wired Tiger后附带了可选的LSM引擎。
LSM树的有趣之处在于它脱离了统治该领域几十年的二叉树风格的文件组织。
LSM-tree(Log-structured merge-tree),因其独特的数据组织方式(Log-structured)和需要在后台不断合并(Merge)的维护方式而得名。又因为顺序写(Sequentially Write)的模式,而取代B+ Tree(更新时会产生慢出2个数量级的随机写),被广泛应用于写密集型(Write-intensive)的数据库。
LSM发展历程
1996年,LSM-tree的论文正式发表。2006年,Google的Bigtable问世,催生了HBase、Cassandra等NoSQL开源项目,也让LSM-tree真正大规模地进入工业界的视线。
当前LSM相关应用如下图所示:

2011年,Google工程师Sanjay Ghemawat和Jeff Dean开源了LevelDB。2013年,Facebook在LevelDB的基础上开发了RocksDB。自此,LSM-tree成为存储引擎(Storage Engine)中不可忽视的一种数据结构,在新硬件、新数据负载不断出现的今天,仍在不断地被研究和扩展。
LSM特点
LSM-tree 是专门为 key-value 存储系统设计的,key-value 类型的存储系统最主要的就两个功能:
(1)put(k,v):写入一个(k,v)
(2)get(k):给定一个 k 查找 v
LSM-tree最大的特点就是写入速度快,主要利用了磁盘的顺序写,淘汰掉了需要随机写入的B树。
LSM组成
LSM组成结构如下图所示:
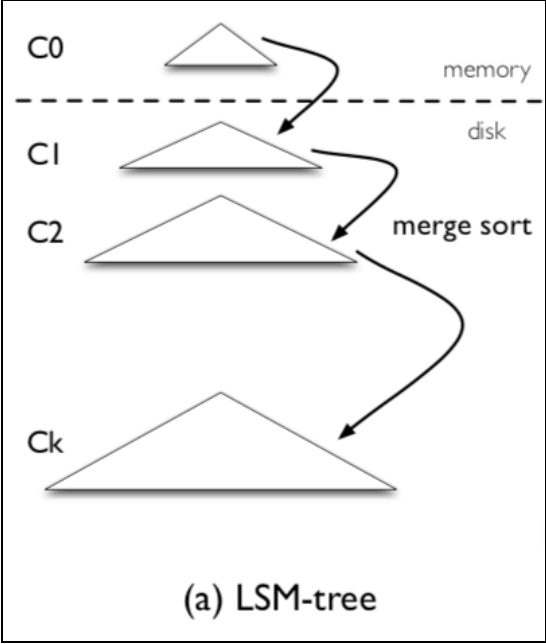
LSM树是一个多层结构,就像一棵树一样,上小下大。
首先是内存的 C0 层,保存了所有最近写入的 (k,v),这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。
剩下的 C1 到 Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构,是磁盘中只添加(append-only)的 B-Tree
LSM写入流程
一个 put(k,v) 操作来了,首先追加到写前日志(Write Ahead Log,也就是真正写入之前记录的日志)中,接下来加到 C0 层。当 C0 层的数据达到一定大小,就把 C0 层 和 C1 层合并,类似归并排序,这个过程就是Compaction(合并)。合并出来的新的 new-C1 会顺序写磁盘,替换掉原来的 old-C1。当 C1 层达到一定大小,会继续和下层合并。合并之后所有旧文件都可以删掉,留下新的。
注意数据的写入可能重复,新版本需要覆盖老版本。什么叫新版本,我先写(a=1),再写(a=233),233 就是新版本了。假如 a 老版本已经到 Ck 层了,这时候 C0 层来了个新版本,这个时候不会去管底下的文件有没有老版本,老版本的清理是在合并的时候做的。
写入过程基本只用到了内存结构,Compaction 可以后台异步完成,不阻塞写入。
LSM查询流程
在写入流程中可以看到,最新的数据在 C0 层,最老的数据在 Ck 层,所以查询也是先查 C0 层,如果没有要查的 k,再查 C1,逐层查。
一次查询可能需要多次单点查询,稍微慢一些。
LSM存在的问题——读写放大
读写放大(read and write amplification)是 LSM-tree 的主要问题,这么定义的:
读写放大 = 磁盘上实际读写的数据量 / 用户需要的数据量
注意是和磁盘交互的数据量才算,这份数据在内存里计算了多少次是不关心的。比如用户本来要写 1KB 数据,结果你在内存里计算了1个小时,最后往磁盘写了 10KB 的数据,写放大就是 10,读也类似。
写放大
我们以 RocksDB 的 Level Style Compaction 机制为例,这种合并机制每次拿上一层的所有文件和下一层合并,下一层大小是上一层的 r 倍。这样单次合并的写放大就是 r 倍,这里是 r 倍还是 r+1 倍跟具体实现有关,我们举个例子。
假如现在有三层,文件大小分别是:9,90,900,r=10。又写了个 1,这时候就会不断合并,1+9=10,10+90=100,100+900=1000。总共写了 10+100+1000。按理来说写放大应该为 1110/1,但是各种论文里不是这么说的,论文里说的是等号右边的比上加号左边的和,也就是10/1 + 100/10 + 1000/100 = 30 = r * level。个人感觉写放大是一个过程,用一个数字衡量不太准确,而且这也只是最坏情况。
读放大
为了查询一个 1KB 的数据。最坏需要读 L0 层的 8 个文件,再读 L1 到 L6 的每一个文件,一共 14 个文件。而每一个文件内部需要读 16KB 的索引,4KB的布隆过滤器,4KB的数据块(看不懂不重要,只要知道从一个SSTable里查一个key,需要读这么多东西就可以了)。一共 24*14/1=336倍。key-value 越小读放大越大。
LSM适用场景
因为LSM写入快,查询慢,所以 LSM-tree 主要针对的场景是写密集、少量查询的场景。
LSM-tree 被用在各种键值数据库中,如 LevelDB,RocksDB,还有分布式行式存储数据库 Cassandra 也用了 LSM-tree 的存储架构。