云原生 OLAP 数据库系统主要面向大规模数据分析型场景, 这类场景以分析型负载为主, 同时也支持以事务型日志的方式批量更新数据. 与传统的 MPP (massively parallel processor) 型数据仓库架构相比, 云原生 OLAP 数据库系统通过采用存储-分离架构不仅提高了系统的弹性, 还基于云平台的异构计算节点和统一云存储 实现了系统的高可用。
目前的云原生 OLAP 数据库架构包含两大类:
(1)计算-存储分离的2层架构
(2)计算-内存-存储分离的3层架构
1.云原生 OLAP 计算-存储分离的两层架构
架构图如下所示:
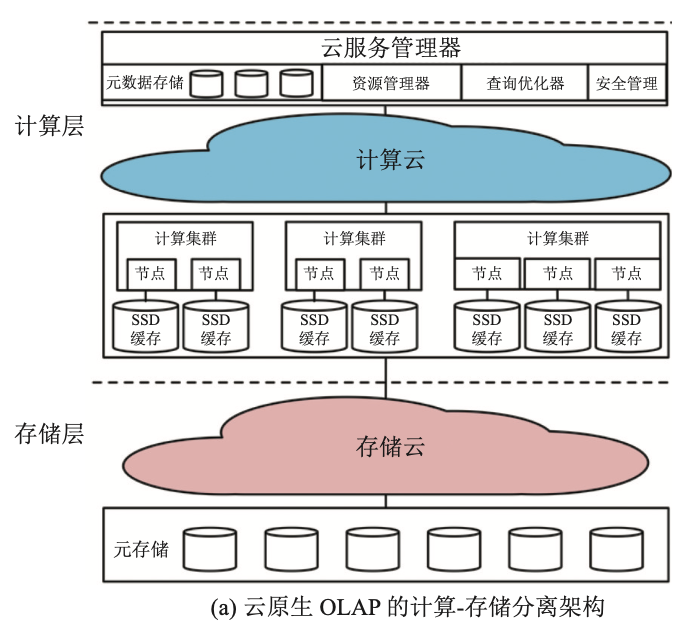
1.1.设计动机
从设计的目的来看, 此架构具备如下 3 个特点:
(1)高度弹性服务:即通过计算层与存储层的 完全解耦, 实现了计算节点与存储节点的独立扩缩容机制, 使得用户可根据自身的计算与存储需求弹性地使用数 据库服务, 从而极大地节约成本。
(2)高可用服务:系统可以基于云提供商的云存储服务实现高可用. 一方面, 云存 储实现了跨区域的多数据副本部署, 当某区域的副本节点出现故障, 服务提供商还可以利用其他节点的数据副本提供服务. 另一方面, 计算节点的本地存储仅用于缓存作用, 当有计算节点发生故障或者有新的节点发生故障时, 系统无需进行数据重分配操作, 只需对相应节点进行新的缓存调用即可。
(3)异构计算服务:系统可在计算层启动 多个计算集群, 每个集群可实例化多个不同配置的计算节点, 用于执行用户的不同的计算任务, 且计算集群之间可 做到隔离执行, 以保证对多个租户同时提供高质量服务.
1.2.查询执行流程
查询处理分为以下 4 个步骤:
(1)查询优化. 云服务管理器接受查询请求后, 查询优化器结合元数据存储的统计信息进行查询重写与优化, 并生成并行查询计划。
(2)基于缓存的查询处理. 查询子计划被发送到计算集群的各个计算节点, 如果缓存命中, 则直接将查询在本地处理后返回结果. 反之, 则向 存储云请求数据。
(3)基于下推的查询处理. 存储云收到请求后, 则访问对应的列式文件, 并通过下推计算到存储 文件, 最后返回过滤后的结果。
(4)结果合并与返回. 计算集群合并各个计算节点的中间结果 (存在 shuffle 过程), 最后合并结果, 并由云服务管理器返回给用户.
1.3.优势与局限
相比于传统的 MPP 型数据仓库, 这类架构能够提供更高的可用性, 更好的弹性, 以及更低的成本。
其主要面临的挑战为如何减少计算层与网络层之间的网络传输. 一方面, 即使计算层与网络层之间有高速网络, 但相比于本地缓存的带宽速度还是有数量级的差距。另一方面, 云服务的计费与扫描的数据量和传输的数据量都有关, 所以需要尽量减少数据的网络传输.
1.4.典型系统
基于云原生 OLAP 计算存储分离架构的系统主要以 Redshift和 Snowflake为代表。
二者都采用了类似的架构, 主要区别在于对计算层与存储层分别做了不同的优化。
Snowflake 在计算层增加了统一的元数据 管理, 使得查询能够被统一调度与优化. 其计算集群高度隔离, 每一个集群服务于一个租户, 且可采用不同配置的 计算实例. 其在云存储之上建立了本地存储集群, 并通过懒加载的方式进行按需在线动态扩容. 其查询处理基于列式的向量化执行, 支持面向云存储的计算下推。
Redshift 由最初的 MPP 型数据仓库转化为云原生数据库, 其基于 AWS (Amazon Web service) 生态在计算层与存储层之间增加了加速层, 包含了针对半结构化数据查询加 速的 Specturm 集群, 结合 FPGA 进行计算下推的 AQUA (advanced query accelerator) 集群, 以及面向编译代码缓存 的 CaaS (compilation as a service) 服务. 其同时增加了本地统一存储服务 RMS (redshift managed storage), 可支持 16 PB 级别的本地 SSD 缓存. 其查询处理基于 C++的代码生成, 并通过同地式连接进行分布式查询优化.
2.云原生 OLAP 计算-内存-存储分离的 3 层架构
架构图如下所示:
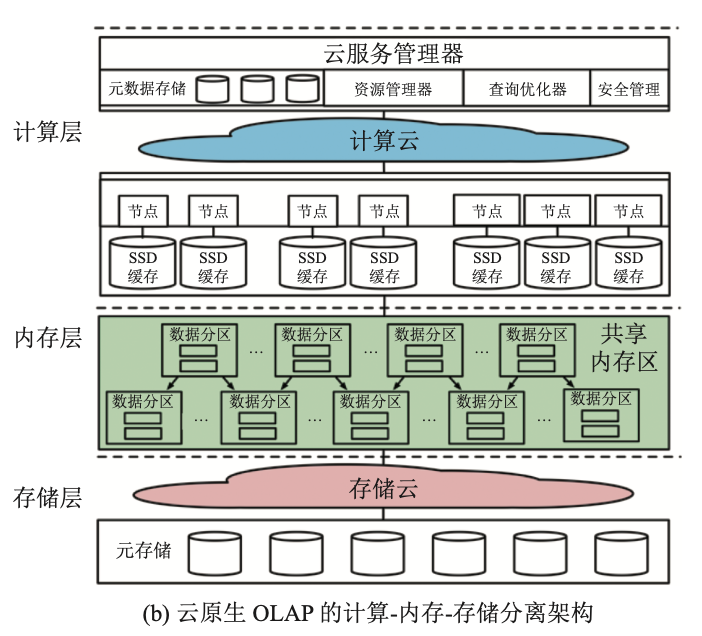
计算层、内存层、 存储层之间同样采用高速网络进行连接, 采用这类架构的主要代表系统为谷歌的 BigQuery。
增加了一层分布式共享内存层, 用于处理复杂查询的 数据洗牌 (shuffle) 操作, 避免中间结果写入磁盘造成 I/O 代价. 最底层的存储云同样提供高可用与弹性的数据存 储服务。
2.1.设计动机
这类架构在计算节点到存储节点之间添加了共享内存层, 用于多个计 算节点之间进行数据合并操作, 例如不同数据表之间的连接与聚集运算等. 通过这种共享内存节点的方式进行合并运算, 能够有效降低计算节点之间进行合并操作的数据传输量与磁盘 I/O, 提高查询的执行效率。
另外, 通过统一的集群调度, 其能获得更高的资源利用率. 由于内存层可以进一步独立调度, 其系统弹性也很高。
2.2.查询执行流程
查询处理分为以下 4 个步骤:
(1)查询优化. 云服务管理器接受查询请求后, 查询优化器结合元数据存储的统计信息进行查询重写与优化, 并生成并行查询计划。
(2)基于缓存的查询处理. 查询子计划被发送到计算集群的各个计算节点, 如果缓存命中, 则直接将查询在本地处理后发送给共享内存层. 反之, 则向存储云请求数据。
(3)基于内存的数据洗牌操作. 计算节点从存储云加载到数据后, 则访问对应的列式文件, 并通过下推计算到存储文件, 最后将过滤后的结果发送给共享内存层. 共享内存层通过多阶段的数据洗牌操作后 将相同键值的数据发送给同一节点。
(4)结果合并与返回. 计算集群合并各个计算节点的中间结果 (不存在 shuffle 过程), 最后合并结果将由云服务管理器返回给用户.
2.3.优势与局限
相比于传统的 MPP 型数据仓库, 这类架构同样能够提供更高的系统吞吐量, 更好的弹性, 以 及更高的资源利用率。
其主要面临的挑战为如何提升系统吞吐的同时能够降低查询执行的费用. 一方面, 分配的共享内存空间过大会造成服务的费用激增. 另一方面, 分配的共享内存空间太小会造成数据溢出, 中间结果会被写入到本地磁盘中, 造成大量磁盘 I/O 代价和网络传输代价.
2.4.典型系统
主要以 BigQuery为代表. 其源自于 Google 的交互式查询系统 Dremel, 通过将其改造为云原生系统后增加了共享内存层, 以加速复杂查询.
其云存储实现 在 Google 的分布式文件系统 Colossus 上, 实现了数据的高可用存储.
文件的格式采用了自研的列存格式 Capacitor, 支持查询在压缩数据上进行直接执行.
针对分布式查询处理, 其采用异步的生产者-消费者执行模式, 生产者不断 生成新的数据分区并分发给不同的节点进行数据处理, 其中 shuffle 过程通过在共享内存层进行加速, 消费者异步地读取不同的节点的输出结果, 将它们合并后在本地执行聚集操作. 如果数据超过内存层的容量, 则进行溢出操作.
3.不同架构 OLAP 系统特性对比
分别从分析处理的吞吐能力、数据读取的效率、资源的隔离性、弹性扩容能力以及部署的成本角度进行分析云原生 OLAP 数据库系统不同架构设计的特性。
OLAP 计算-存储分离架构类似于 OLTP 的计算-存储分离架构的系统。但是不同之处在于, OLAP 系统面向大规模数据分析, 其存储云节点按照数据分片进行管理, 不需要分析日志数据保证了数据分析过程的高吞吐率。此外, 上层计算云节点不区分主节点和备节点进行统一的管理, 计算集群中的工作节点独立地处理各个数据分片的分析任务, 且计算集群之间具有良好的隔离性. 系统支持计算和存储的单独扩展, 具有较强的弹性资源调度能力和相对低的服务成本。
OLAP计算-内存-存储分离架构, 需要计算云服务、内存云服务以及存储云服务的支持, 类似于 OLTP 系统的计算-缓存-存储分离结构. 不同之处在于, 内存云服务不是用于缓存底层存储层数据, 而是用于不同计算节点间进行数据合并操作, 通过共享内存降低数据合并时大量的节点间网络通信, 进一步提高了数据分析的吞吐能力. 但是, 节点间的共享内存降低了不同计算任务间的隔离性. 额外的内存云服务的引入要求具备大规模内存的服务器设备, 相较于第一类系统架构提高了服务成本. 但系统支持在计算、内存和存储资源上的单独扩展, 因此具备更强的资源弹性调度能力.
4.云原生 OLAP 数据库关键技术
云原生 OLAP 数据库关键技术主要包含云存储管理技术、查询处理技术、无服务器感知计算 (serverless computing) 技术、数据保护技术、机器学习技术 5 个方面。如下图所示:
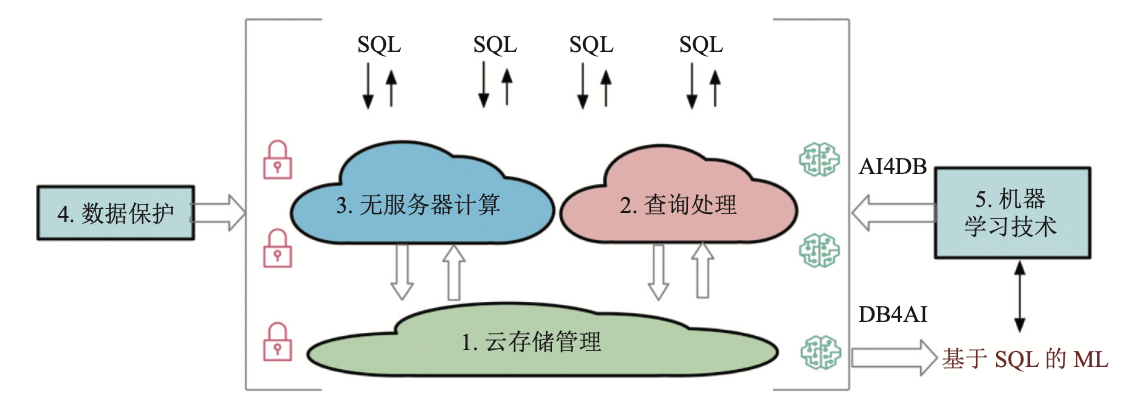
云存储管理作为云数据库的底座, 支撑着上层的云服务。
无服务器感知计算与查询处理模块接受来自上层多租户的 SQL 请求, 并通过与云存储交互以提 供数据的查询服务。
数据保护模块对整体云服务进行端到端的保护。
机器学习技术一方面对云数据库服务进行优化, 另一方面基于弹性的云数据库服务进行自动化机器学习管理。
4.1.存储管理技术
云原生 OLAP 数据库系统的存储管理包含
(1)元数据管理:元数据管理对云原生数据库系统的存储管理与查询优化都非常重要, 由于云原生 OLAP 数据库基本 都不支持索引操作, 因此元数据可用于支持数据剪枝, 数据克隆, 以及数据的多版本控制 (multiversion concurrency control, MVCC) 与查询访问, 其主要的优点是可以优化查询, 但目前的主要的问题是其更新代价较高。
(2)关系表数据组织:云存储服务可为计算层提供高可用、弹性的存储服务, 但云原生数据库也可对本地集群的缓存数据进行管 理, 这主要涉及数据的组织与划分技术。
(3)半结构化数据管理:由于云平台上的用户也拥有许多半结构化的数据, 因此, 如何在云平台上对半结构化数据进行管理也是一个很重要的问题。
三者对比如下表所示:
4.1.1.元数据管理
元数据常被称为数据字典或“数据的数据”, 其主要存储数据的统计信息与版本信息. 针对云原生 OLAP 数据库, 此模块位于系统计算层的云服务管理器内, 可支持存储管理与查询优化, 其具体实现一般采用分布式的键值存储, 以保证高扩展性与高可用性, 如 Snowflake 采用了分布式的键值数据库实现其元数据存储.
元数据管理的 3 项关键技术:
(1)基于元数据的剪枝
(2)零克隆技术
(3)时间旅行操作
4.1.2.关系表数据组织
针对云原生 OLAP 数据库, 关系表将被水平式地划分为多个子文件, 每个子文件类似于传统关系数据库的数据块或页面的概念, 但划分的文件一般不支持修改, 只能通过复制一份新文件的方式将更新操作附加在新文件中. 每个文件内部主要采用列式存储或混合行/列存储的格式, 文件头包含一些元数据以及每一列的存储偏移. 因此, 如果查询只访问文件中的部分列, 通过读取文件头的信息可以读取到相应列的位置, 而无需全表扫描. 文件组织好 后可以通过云服务直接保存在云存储中 (如 AWS S3 对象存储云服务).
虽然云存储提供商能保证数据的跨域部署与高可用, 云原生 OLAP 数据库在本地集群也可将热数据分区后置放在不同的计算节点以加速查询的分布式执行. 划分数据的方法一般通过指定关系表的划分键, 然后根据划分键的哈希值产生对应的元组集合, 并将它们分配到不同的计算节点中. 这种方式使得相同哈希值的元组集合都只在本地做连接操作, 而无需节点之间进行数据传输。
4.1.3.半结构化数据管理
传统关系数据库面向的主要业务场景为银行事务系统与企业 ERP (enterprise resource planning) 系统, 这些场景的数据模式比较固定。
云原生 OLAP 数据库也面向许多互联网应用, 所以需要管理大量的半结构化文档数据 如 HTML 网页, XML 与 JSON 文档, 它们的数据模式很灵活, 常常有嵌套结构, 且不采用统一标准化的数据模式.
目前云原生数据库主要有两种方法管理半结构化数据: 一是根据文档模式提前转换文档为列存数据。二是采用变长字段存储文档数据, 在查询数据时采用自动类型推断。
4.2.查询处理技术
云原生 OLAP 数据库系统面向分析性负载采取计算与存储分离的架构, 以实现计算节点与存储节点的细粒度弹性伸缩. 但由于计算层与存储层的分离, 中间的网络传输成为了瓶颈, 因此如何减少从存储层到计算层的数据传输量是云原生 OLAP 数据库要解决的一个重要问题。
目前的数据库主要采取算子下推技术结合本地缓存减少网络传输量。
4.2.1.基于计算下推的查询处理
将计算下推到存储层, 以减少数据的网络传输量。
4.2.2.基于 Shuffle 内存层的查询处理
基于 Shuffle 内存层进行查询处理. 其从存储层读取列式数据, 将简单 的谓词做下推计算后, 结合 Shuffle 内存层进行查询并发处理.
具体来说, 其将本地节点下推后的数据划分后分发到不同的工作节点进行三阶段 (map-shuffle-reduce) 的计算. 其中, 中间的 Shuffle 过程在统一内存层进行, 这避免 了数据的重分发以及中间结果的磁盘写入, 因此其吞吐量很高.
然而, 针对中间结果集很大的查询, 该方法会产生较高的代价, 因此需要限定内存层的大小, 如果结果集超过内存大小, 需要将数据溢出到磁盘.
4.2.3.结合本地缓存与计算下推的查询处理
结合本地缓存与云存储的混合计算下推。对于查询计划生成, 一般采取两个经验法则:
(1)本地缓存下推比云存储下推更高效
(2)云存储下推比计算节点加载数据后计算更高效
4.3.无服务器感知技术
无服务器感知计算 (serverless computing) 被认为是下一代云计算的主要形式。其主要目标为从第 1 代云计算的简化基础设施与系统管理变换到新一代云计算的简化用户编程。针对数据库管理系统的无服务器感知计算, DBA只需要编写查询而无需关心数据库的资源配置, 云提供商即可按需为提交的查询调度资源.
目前主要有两种方式:
(1)基于数据库实例进行弹性调度资源
(2)基于 Lambda 函数的弹性计算
两种方式对比如下表所示:
4.3.1.基于数据库实例的无服务器感知计算
基于数据库实例提供无服务器化的查询引擎计算服务, 并按照整个实例的启动和暂停进行整体的调度, 即实例启动运行时按照计算量计费, 实例暂停时进行资源回收, 不对用户进行收费。
这类方法的主要难点在于数据库系统的启动和停止具备较长的延时, 因此, 如何降低系统启 停产生的额外延时是这一研究方法的关键。
目前最先进的方法是基于时间序列的建模方法。其基于历史工作负载的时间序列建模, 然后动态调整数据库系统运转状态. 其在用户的工作负载到来前提前启动云数据 库服务, 使得用户的等待时延大幅降低. 当短时间无工作负载的情境下该技术也不会停止系统运行, 因为用户可能 还会随时登入执行负载. 当长时间没有用户请求, 才会暂停实例. 这类技术主要的问题是系统的资源调度机制对用 户不透明, 用户可能会被强制超额使用服务, 因此需要公平的审计机制来保证其合理性.
4.3.2.基于函数服务的无服务器感知计算
函数即服务 (function as a service, FaaS) 是近年来云数据服务领域发展的另一个关键技术。其通过云服务的框架, 来支持用户的敏捷开发.
其核心特点为无服务器感知计算: 即将一些常见的计算功能包装成由云服务平台统一调度的函数模组, 用户直接基于这些函数模组进行程序设计, 因此可以实现毫秒级别的程序启动, 并实现高 速弹性调度的能力 (可同时启动上百的并发函数).
目前大型云厂商都提供了相应的基于 Lambda 函数的无服务计 算, 如 AWS Lambda、Azure Functions、Google Cloud Functions. 但针对数据库的查询计算, 基于 Lambda 函数的 无服务器感知计算有两大难点.
(1)每个函数是有生命周期的 (约 5 min), 因此需要有一定的机制来保存每个函 数计算后的结果状态, 以达到成功执行查询计划的目的.
(2)当并发执行多个函数会出现某些函数由于资源匮乏 而滞后, 从而导致整个查询计划执行缓慢, 即木桶效应.
对于第 1 个难点, 可通过云存储来保存中间状态。对于第 2 个难点, 目前主要通过启动并发复制任务的方式来解决。
4.4.数据保护技术
目前云数据库的数据保护技术主要包含两大类:
(1)基于密钥管理算法的数据保护
(2)基于可信计算环境 Enclave 的数据保护
两者主要对比如下表所示:
4.4.1.基于密钥管理算法的数据保护技术
基于密钥管理算法的数据保护技术采用加密算法和密钥管理策略以保护数据.
例如, Snowflake采用 AES 256 位的对称加密算法结合层次模型的密钥管理, 其提出了基于层次结构的密钥管理架构, 即自顶向下从根密钥、 账户密钥、表密钥、文件密钥 4 个层次对密钥进行管理, 其还通过密钥的轮转机制定期对密钥进行更换.
这类技术易于实现, 并基于公有云平台 (如 AWS) 提供安全保护; 数据在导入、传输、存储、导出的时间点都处于加密 状态, 但在查询处理时需要解密后再进行处理, 未来可研究在密文上进行查询的算法.
4.4.2.基于 Enclave 的数据保护技术
基于 Enclave 的数据保护技术基于硬件技术进行数据保护, 且用户数据仅在硬件区域内被解密处理, 数据具有更高的安全性.
例如, 微软的 Azure SQL 基于可信计算环境 Enclave 进行数据保护. 其假设数据库系统与云服 务提供商均为不可信环境, 仅客户端与 Enclave 区域为可信环境. 针对查询处理, 用户通过自身的密钥通过验证服务后, 向加密数据库提交查询, 然后数据以密文的方式被传输到 Enclave 后才进行解密后的查询处理.
这类技术当 前的主要挑战为查询的效率与扩展性问题, 这主要是受限于 Enclave 的内存大小与查询处理能力.
4.5.机器学习技术
结合云原生数据库技术与机器学习技术 (artificial intelligence, AI) 是当前云上数据管理的一个重要发展趋势. 一方面, 机器学习技术可以被用于优化许多云原生数据库的关键任务, 包括负载管理、数据划分键选择、索引选 择、参数调优等. 另一方面, 机器学习技术可以基于云原生数据库为用户提供智能化的机器学习服务, 比如, 数据库前端可基于 SQL 进行模型建立与推断, 后端基于可扩展的弹性计算与存储进行自动化机器学习管理.
4.5.1.基于机器学习的云原生数据库技术
基于机器学习的云原生数据库技术采用高级的机器学习技术优化云数据库的服务. 例如, Redshift 的自动化负载管理工具 AutoWLM 通过训练 XGBoost 模型预测查询的内存消耗量与执行时间, 从而能够自动地为用户的负 载提前调整并发度.
4.5.2.基于云原生数据库的机器学习技术
面向云原生数据库进行机器学习主要有 3 个优势.
(1)它提供了基于 SQL 的机器学习途径, 使得用户可以更方便快捷地进行机器学习. 例如, Redshift 支持用户通过“Create Model”的 SQL 语法建立模型, 并通过指定目标 列进行训练后用于后续预测任务.
(2)基于云原生数据库进行机器学习可以做到“数据不动模型动”的优化, 使得训练好的模型可以在本地进行推断, 减少了数据传输的开销.
(3)最后, 基于云原生数据库的机器学习可以利用云原生 数据库的弹性计算和存储能力进行更好的模型自动化管理. 例如, 自动化机器学习系统 Sagemaker依托 Redshift 可启动多个不同的实例, 并开启 250 个不同的任务, 针对不同的数据样本进行模型选择与自动调参.
面向云原生数 据库的机器学习技术主要的挑战是模型的训练成本高, 相对于本地进行机器学习, 用户要额外负担在云上的数据存储、模型训练以及模型推断的成本. 因此, 未来需要解决如何结合用户的预算提供服务的问题.