ORC文件格式是一种Hadoop生态圈中的列式存储格式,最初产生于Hive-0.11版本,用于降低hadoop数据存储空间和加速hive查询速度。
1.ORC文件结构
ORC文件结构如下图所示:
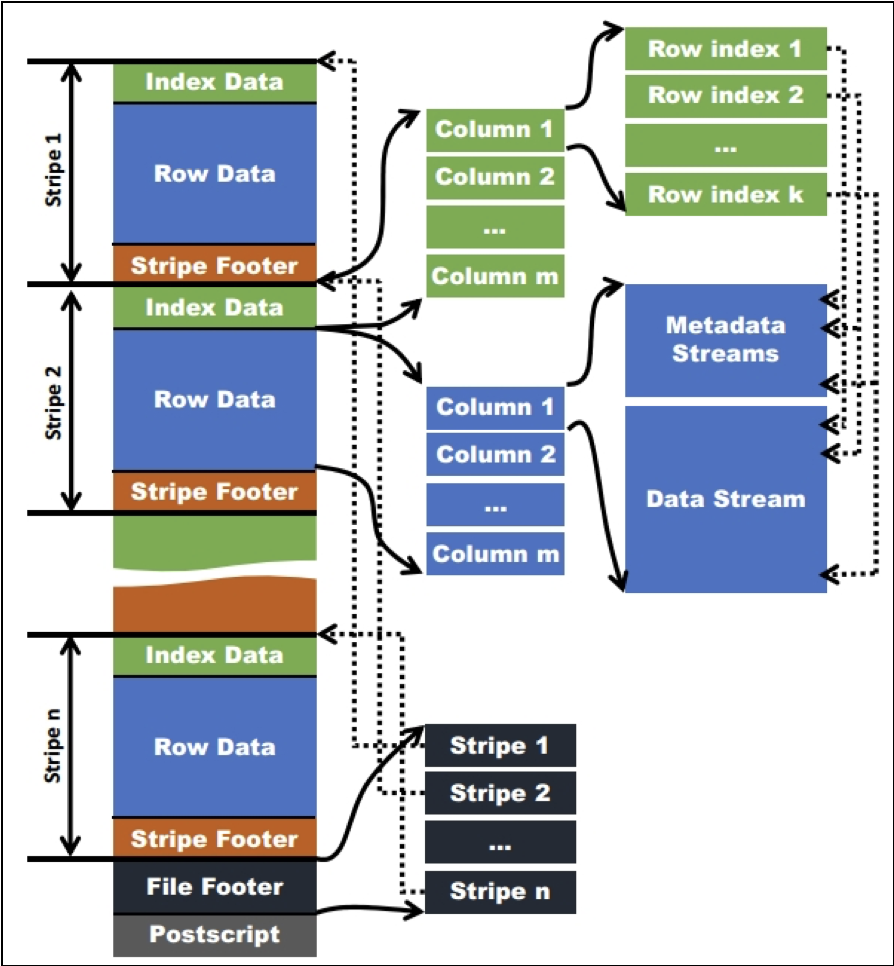
在ORC格式的Hive表中,表数据会被横向切分为多个stripes,然后在每个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。
每个stripe的默认大小为256MB,相对于RCFile的每个4MB的stripe而言,更大的stripe使ORC的数据读取更加高效。
2.ORC数据存储方法
对于基本类型的字段,每个字段就对应一个子字段。对于复杂数据类型,ORC会将复杂数据类型解析成多个子字段。下表列举了复杂字段的解析:
当字段类型都被解析后,会由这些字段类型组成一个字段树,只有树的叶子结点才会保存表数据,这些叶子结点中的数据形成一个数据流,如ORC文件结构图中的“Data Stream”。
为了使ORC文件的reader更加高效地读取数据,字段的metadata会保存在Meta Stream中。在字段树中,每一个非叶子结点记录的就是字段的的metadata,比如对一个array来说,会记录它的长度。
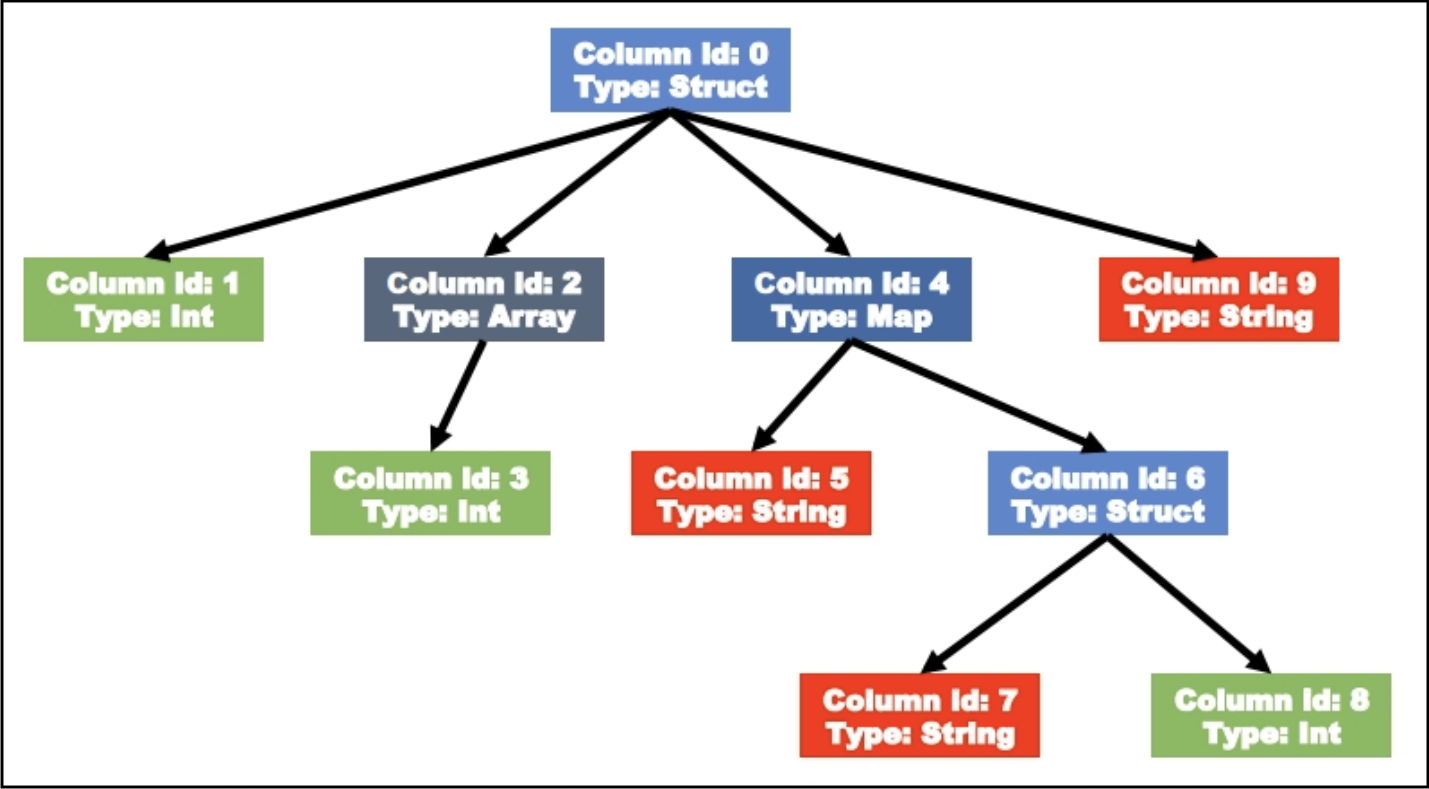
例如,按以下语句创建一张表:
CREATE TABLE tb1(col1 Int,
col2 Array<Int>,
col4 Map<String, Struct<col7:String, col8:Int>>,
col9 String)则生成的字段树如下所示:
在Hive-0.13中,ORC文件格式只支持读取指定字段,还不支持制度去特殊字段类型中的指定部分。
使用ORC文件格式时,用户可以使用HDFS的每一个block存储ORC文件的一个stripe。对于一个ORC文件来说,stripe的大小一般需要设置得比HDFS的block小。如果stripe比HDFS的block大,一个stripe就会分别在HDFS的多个block上,当读取这种数据时就会发生远程读取数据的行为。如果设置stripe的只保存在一个block上的话,如果当前block上的剩余空间不足以存储下一个stripe,ORC的writer接下来会将数据打散保存在block剩余的空间上,直到这个block存满为止。这样,下一个stripe又会从下一个block开始存储。
3.ORC使用的索引
ORC文件中添加索引是为了更高效地从HDFS读取数据。ORC文件中使用的是稀疏索引(sparse indexes)。主要有两种用途的索引:
3.1.数据统计(Data Statistics)索引
ORC reader用这个索引来跳过读取不必要的数据,在ORC writer生成ORC文件时会创建这个索引文件。
Data Statistics有三种level:
(1)file level statistics:在ORC文件末尾会记录文件级别的统计信息,会记录整个文件中columns的统计信息。这些信息主要用于查询的优化,也可以为一些简单的聚合查询输出结果,比如max、min、sum等。
(2)stripe level statistics:ORC文件会保存每个字段stripe级别的统计信息,ORC reader使用这些统计信息确定对于一个查询语句来说,需要读入哪些stripe中的记录。比如说某个stripe的字段max(a)=10,min(a)=3,那么当where条件为a >10或者a <3时,那么这个stripe中的所有记录在查询语句执行时不会被读入。
(3)index group level statistics:为了进一步避免读入不必要的数据,在逻辑上讲一个column的index以一个给定的值(默认为10000,可由参数配置)分割为多个index组。以10000条记录为一个组,对数据进行统计。Hive查询引擎会将where条件中的约束传递给ORC reader,这些reader根据组级别的统计信息,过滤掉不必要的数据。如果该值设置得太小,就会保存更多的统计信息,用户需要根据自己数据的特点权衡一个合理的值。
3.2.位置指针(Position Pointers)索引
当读取一个ORC文件时,ORC reader需要有两个位置信息才能准确的进行数据读取操作。
一个是metadata streams和data streams中每个group的开始位置:由于每个stripe中有多个group,ORC reader需要知道每个group的metadata streams和data streams的开始位置。图1中右边的虚线代表的就是这种pointer。
另一个是stripes的开始位置:由于一个ORC文件可以包含多个stripes,并且一个HDFS block也能包含多个stripes。为了快速定位指定stripe的位置,需要知道每个stripe的开始位置。这些信息会保存在ORC file的File Footer中。如ORC文件结构图中间位置的虚线所示。
4.内存管理
当ORC writer写数据时,会将整个stripe保存在内存中。由于stripe的默认值一般比较大,当有多个ORC writer同时写数据时,可能会导致内存不足。为了现在这种并发写时的内存消耗,ORC文件中引入了一个内存管理器。在一个Map或者Reduce任务中内存管理器会设置一个阈值,这个阈值会限制writer使用的总内存大小。当有新的writer需要写出数据时,会向内存管理器注册其大小(一般也就是stripe的大小),当内存管理器接收到的总注册大小超过阈值时,内存管理器会将stripe的实际大小按该writer注册的内存大小与总注册内存大小的比例进行缩小。当有writer关闭时,内存管理器会将其注册的内存从总注册内存中注销。
5.ORC与RCFile的对比
ORC是在RCFile的基础上进行了一定的改进,与RCFile相比,具有以下优势:
ORC中的特定的序列化与反序列化操作可以使ORC file writer根据数据类型进行写出。
提供了多种RCFile中没有的indexes,这些indexes可以使ORC的reader很快地读到需要的数据,并且跳过无用数据,这使得ORC文件中的数据可以很快地得到访问。
由于ORC file writer可以根据数据类型进行写出,所以ORC可以支持复杂的数据结构,比如map等。
除了上面三个理论上的优势外,ORC的具体实现上还有一些其他的优势,比如ORC的stripe默认大小更大,为ORC writer提供了一个memory manager来管理内存使用情况。