KafkaServer性能模型
Kafka是一个高性能的消息队列,下面从Kafka Server侧来解析Kafka高性能的原因。
Kafka服务端线程模型
这是最基本的高性能设计,通过池设计和高并发来实现。
Kafka线程模型如下图所示:
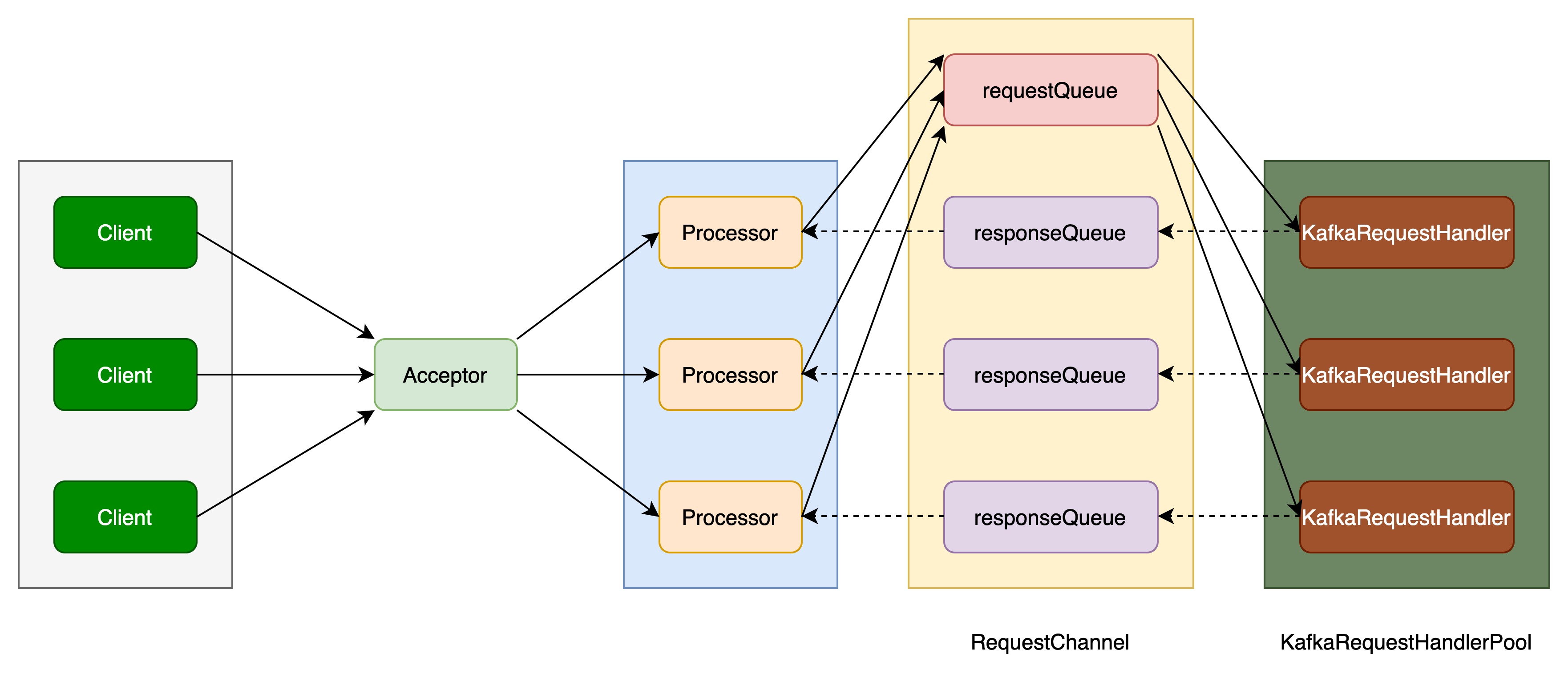
线程模型中包含四种角色:Acceptor、Processor、RequestChannel、RequestHandlerPool。
模型中各角色分工明确、多线程协作,使Kafka能够同时处理大量有效请求,保持高吞吐量。
Acceptor
Acceptor是请求接收器,用于接收来自客户端的请求,以及返回响应。
一个Listener对应一个Endpoint,一个Endpoint对应两个Acceptor,分别是controlPlaneAcceptor和dataPlaneAcceptor。
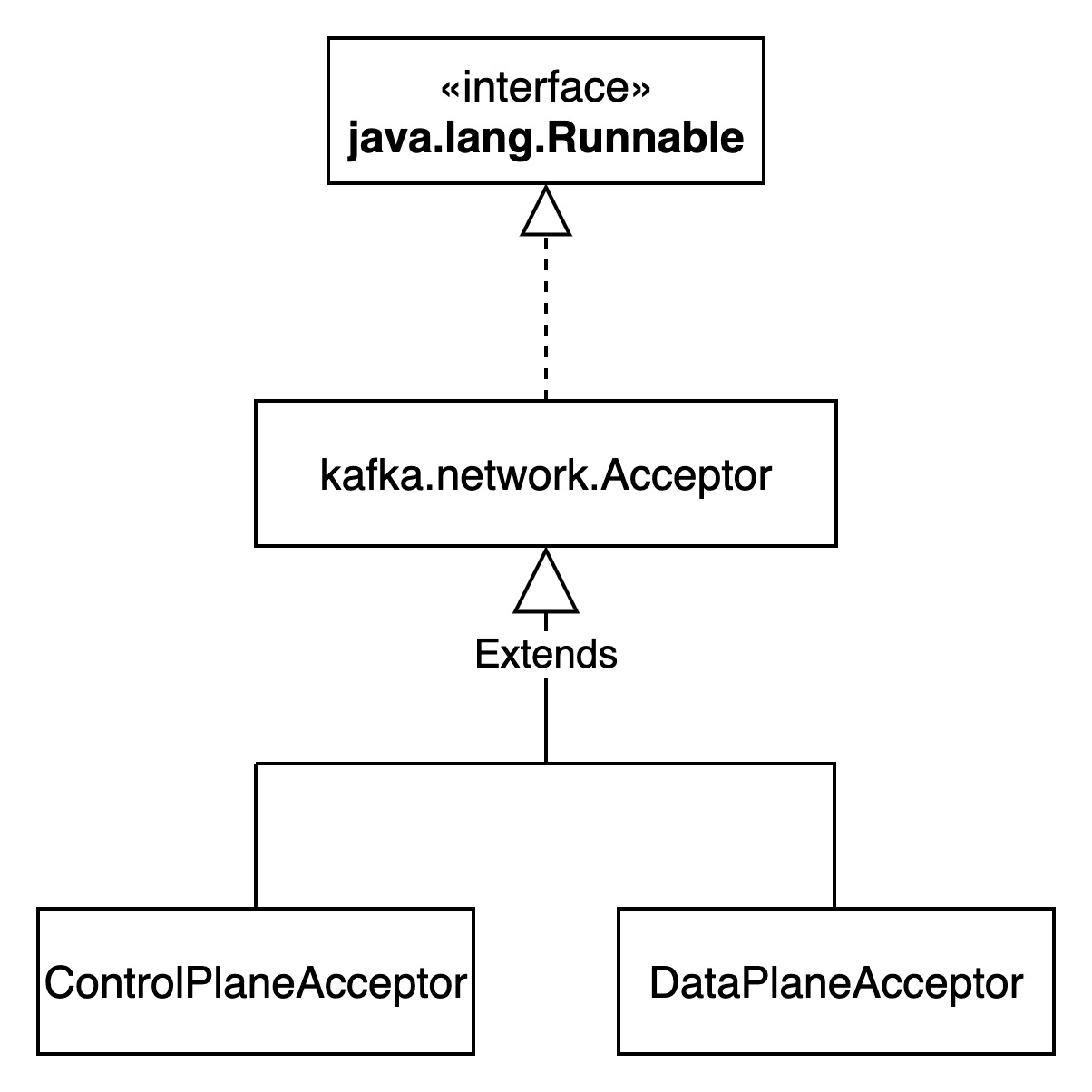
controlPlaneAcceptor和dataPlaneAcceptor是两套相似的处理系统,分别处理不同的请求。
Processor
Acceptor接收到客户端请求后,把请求交给Processor进行处理。可通过num.network.threads参数配置Processor个数,提升请求并发处理效率,默认为3。
Processor中包含一个responseQueue队列。
RequestChannel
RequestChannel中封装了一个requestQueue队列,队列大小由queued.max.requests配置决定。如果是control-plane,队列大小固定为20。
RequestChannel中封装了多个Processor,相当于多个responseQueue。
KafkaRequestHandlerPool
KafkaRequestHandlerPool是请求处理器池,处理器数量由num.io.threads决定,默认为8。如果是control-plane,池中处理器数量为1。
KafkaScheduler
KafkaScheduler是Kafka Server的后台定时调度器,用于执行LogManager、AlterPartitionManager和ReplicaManager提交的定时任务。
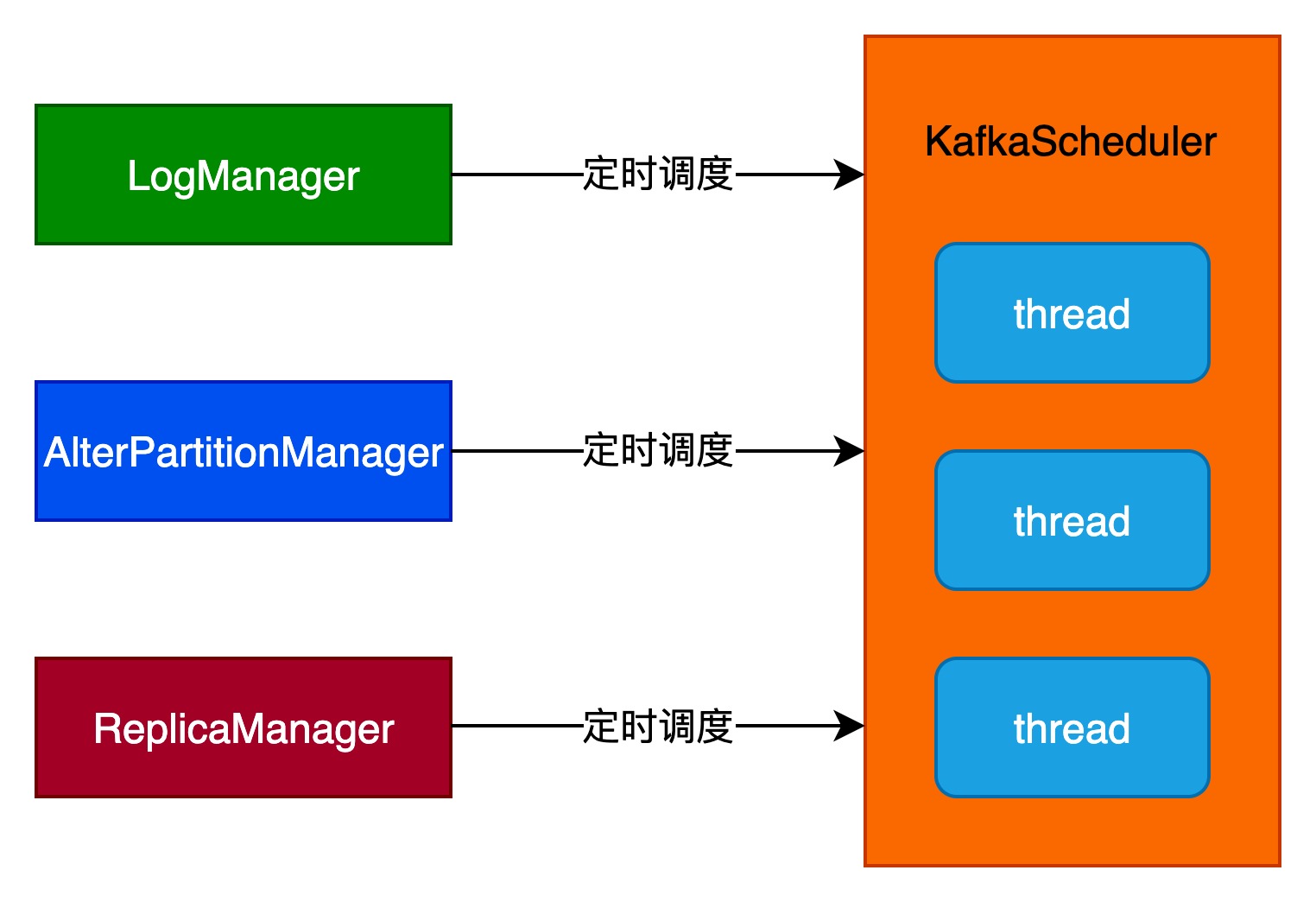
KafkaScheduler中核心线程数由background.threads参数决定,默认为1。
文件系统管理
kafka文件结构如下图所示:
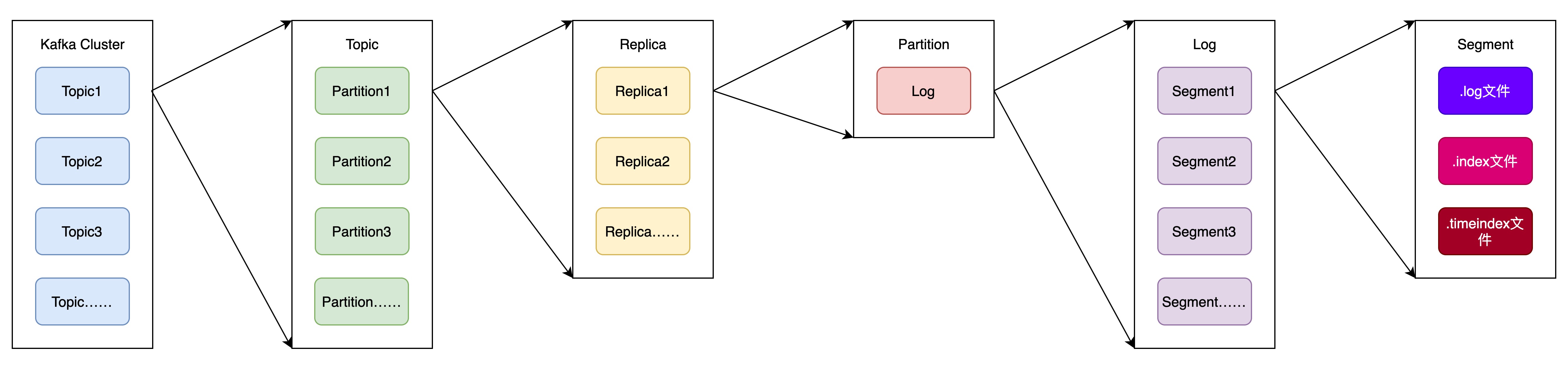
一个kafka集群中,可根据需要创建Topic,所以Topic数量时不固定的。
在创建Topic时,需指定该Topic的分区数,以及每个分区的副本数。
每个副本在磁盘中有一个日志目录来存储该副本的数据,副本日志根据消息的序号,可分为不同的Segment。Segment的数量由副本的数据量和Topic的保留时间决定。
每个Segment由三个文件组成。
Segment log文件
log文件名为“[baseOffset].log”,baseOffset是该Segment中第一条消息的offset,从0开始。这样的设计允许Kafka在恢复时从特定的offset开始重新读取消息。
写入新消息时,数据直接以追加(append)的方式添加到log文件的末尾。由于是追加写入,无论文件多大,写入的时间复杂度都是O(1)。
Segment index文件
index文件用于提供快速的消息查找。通过index文件,Kafka可以快速定位到消息在log文件中的位置,提高读取性能。
index文件的设计有助于加速消息的检索和定位。
index文件中每条记录都可以转换为一个OffsetIndex对象,OffsetIndex对象中具有两个属性:相对位移和对应消息在log文件中的物理位置。相对位移是个Integer,4字节;消息物理位置也是一个Integer,4字节。因此一个索引记录(OffsetIndex)占8字节。
Kafka索引文件采用了分段和稀疏索引的方式。这种设计使得通过二分查找快速定位到日志位点成为可能,而且返回的是低位点。与日志文件不同,由于索引文件相对较小,Kafka使用了mmap的方式进行操作,以提高速度。
分段和稀疏索引
index文件采用了分段和稀疏索引的方式。和log文件一样,index文件被划分为多个段,每个log文件都对应一个index文件。每个index文件中中包含对应log文件中部分消息数据的索引项。
注意,索引项不是每个消息都有,而是按照一定规律设置,使得索引文件的大小相对较小。这就是稀疏索引的含义。
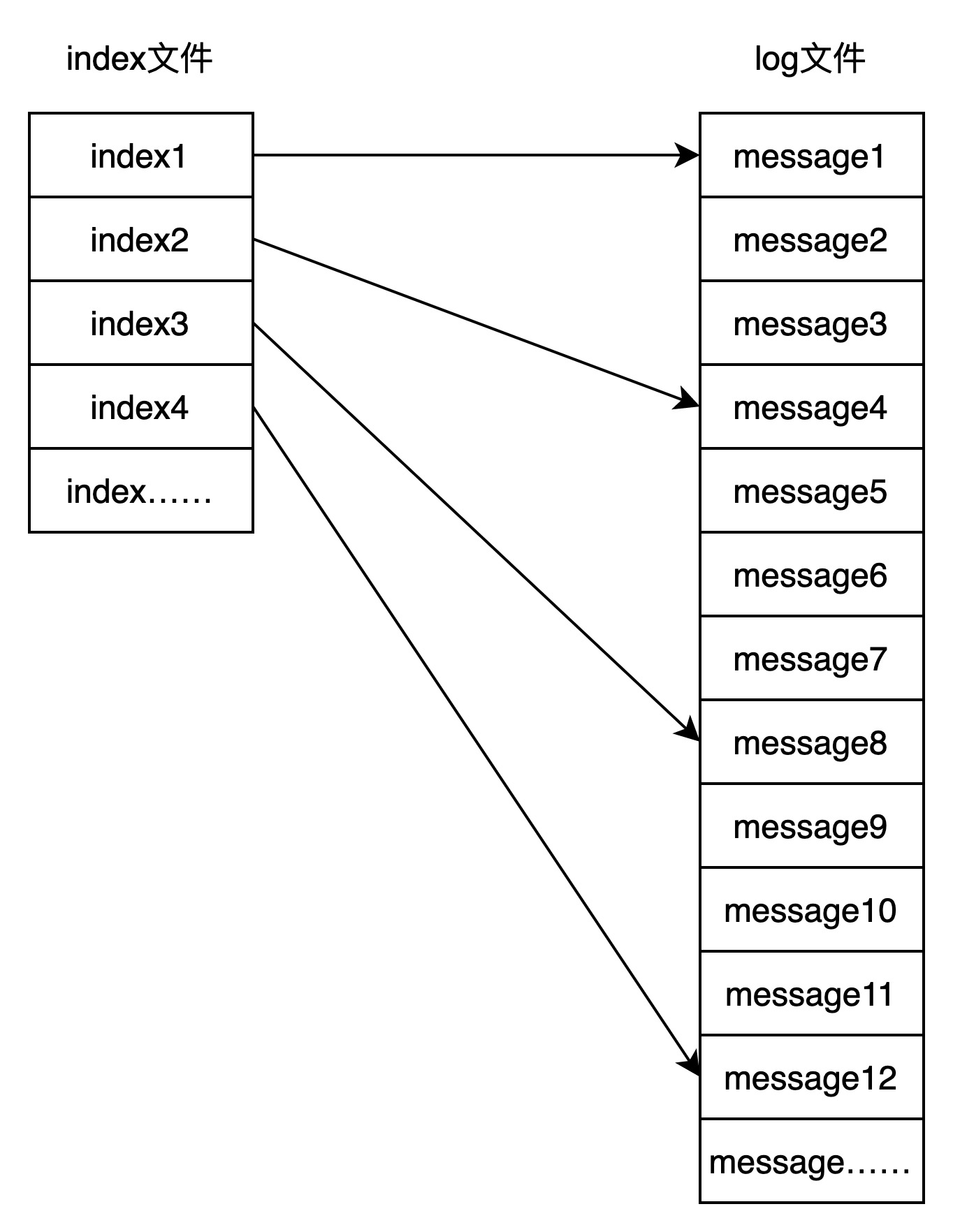
如上图所示,log文件中每隔3条消息设置一个索引,而不是一条消息对应一个索引。这样,index文件中索引记录数将会是log文件中消息记录数的1/3。
二分查找
采用二分查找的方式,通过index文件快速定位到特定的日志位点。这样的查找算法具有较高的效率,能够在日志文件很大的情况下快速定位到目标位置。
上图中,如果要读取message5,加入index记录数为10个,则查找顺序为index5--->index3--->index2,这样就能读取到index2对应的message4。
返回低位点
在查找时,索引文件返回的是低位点,即最接近但不超过目标位点的索引项。这样的设计有助于准确定位到目标位置,从而提高读取的准确性。
根据稀疏索引的特性,需要找到低于目标offset对应的消息的,也就是上例中index2,通过index2索引到的log文件中的消息(message4),再顺序往后读,就能读取到message5这条消息。
mmap方式操作
有了稀疏索引,当给定一个 offset 时,Kafka 采用的是二分查找来扫描索引定位不大于 offset 的物理位移 position,再到日志文件找到目标消息。
利用稀疏索引,已经基本解决了高效查询的问题,但是这个过程中仍然有进一步的优化空间,那便是通过 mmap(memory mapped files) 读写上面提到的稀疏索引文件,进一步提高查询消息的速度。
由于index文件相对较小,Kafka使用mmap(内存映射)的方式进行操作。mmap将文件映射到虚拟内存,使得文件的读取和访问可以直接在内存中进行,避免了磁盘IO的开销,提高了操作速度。

基于 JDK nio 包下的 MappedByteBuffer 的 map 函数,将磁盘文件映射到内存中。
进程通过调用mmap系统函数,将文件或物理内存的一部分映射到其虚拟地址空间。这个过程中,操作系统会为映射的内存区域分配一个虚拟地址,并将这个地址与文件或物理内存的实际内容关联起来。
一旦内存映射完成,进程就可以通过指针直接访问映射的内存区域。这种访问方式就像访问普通内存一样简单和高效。
Segment timeindex文件
timeindex文件用于根据时间戳快速查找特定消息的位移值。
timeindex文件中保存的是“<时间戳,相对位移值>”键值对。时间戳是Long类型,相对偏移值是Integer类型。因此,TimeIndex单个索引项需要占12字节。存储同数量索引项,TimeIndex(12字节)比OffsetIndex(8字节)占更多磁盘空间。
虽然OffsetIndex和TimeIndex是不同类型索引,但Kafka内部把二者结合使用。通常先使用TimeIndex寻找满足时间戳要求的消息位移值,然后再利用OffsetIndex定位该位移值所在的物理文件位置。也就是说,如果要使用timeindex文件中的TimeIndex索引,则必须用到index文件中的OffsetIndex索引。
顺序磁盘IO
写入新消息时,数据直接以追加(append)的方式添加到log文件的末尾。由于是追加写入,无论文件多大,写入的时间复杂度都是O(1)。
kafka读取消息是根据offset从小到大读取的,因为写入消息是顺序的,所以读取肯定也是顺序的。
磁盘的运行原理如下图所示
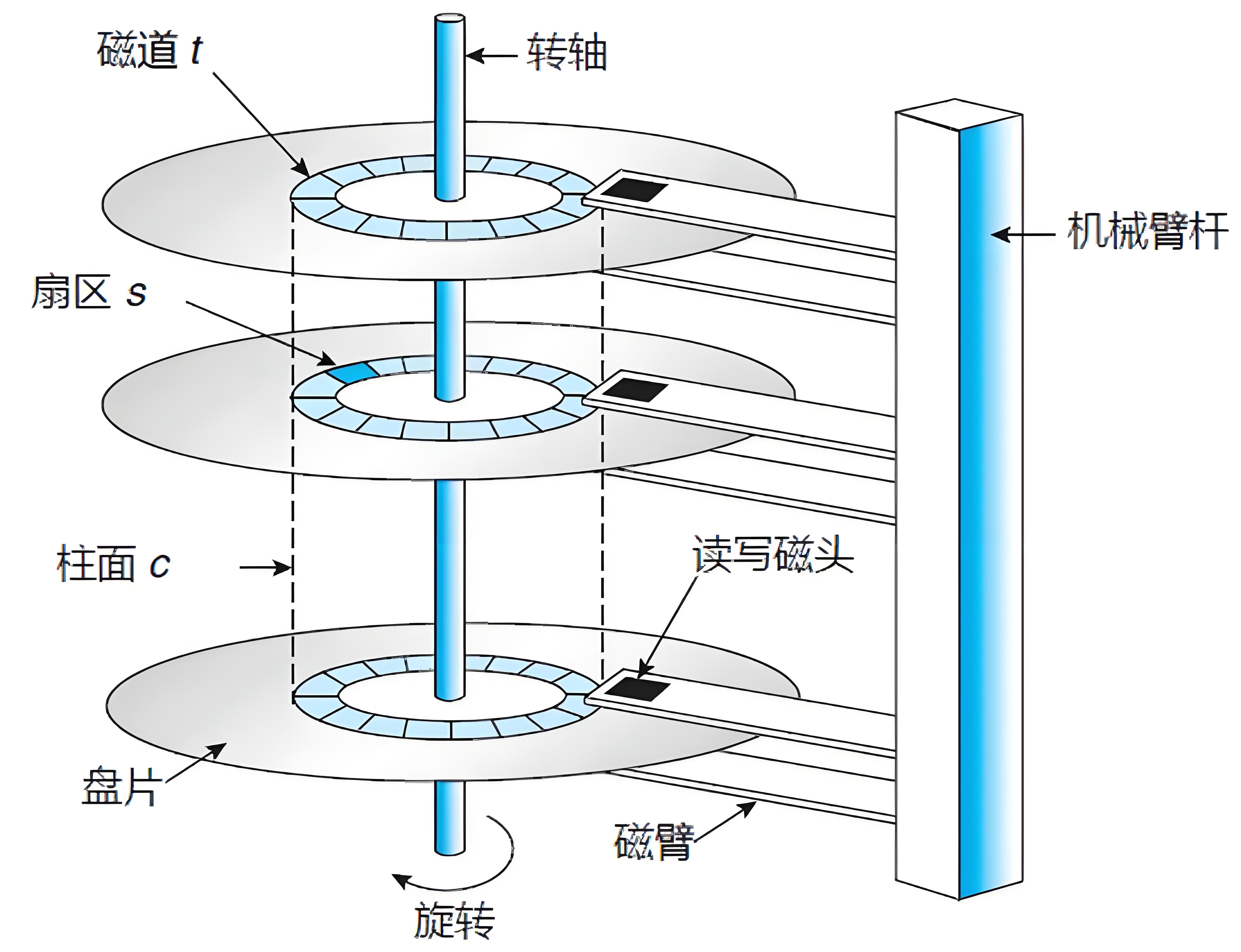
硬盘在逻辑上被划分为磁道、柱面以及扇区。硬盘的每个盘片的每个面都有一个读写磁头。
完成一次磁盘 I/O ,需要经过寻道、旋转和数据传输三个步骤。
(1)寻道:首先必须找到柱面,即磁头需要移动到相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间。寻道时间越短,I/O 操作越快,目前磁盘的平均寻道时间一般在 3-15ms。
(2)旋转:磁盘旋转将目标扇区旋转到磁头下。这个过程耗费的时间叫做旋转时间。旋转延迟取决于磁盘转速,通常用磁盘旋转一周所需时间的 1/2 表示。比如:7200rpm 的磁盘平均旋转延迟大约为 60*1000/7200/2 = 4.17ms,而转速为 15000rpm 的磁盘其平均旋转延迟为 2ms。
(3)数据传输:数据在磁盘与内存之间的实际传输。
因此,如果在写磁盘的时候省去寻道、旋转可以极大地提高磁盘读写的性能。
Kafka 采用顺序写文件的方式来提高磁盘写入性能。顺序写文件,顺序 I/O 的时候,磁头几乎不用换道,或者换道的时间很短。减少了磁盘寻道和旋转的次数。磁头再也不用在磁道上乱舞了,而是一路向前飞速前行。
机械硬盘的IO测试中发现:顺序读IO的性能是随机读IO的40~400倍;顺序写IO的性能是随机写IO的10~100倍。原因在于随机IO的寻道时间比顺序IO要长。

页缓存机制
Kafka并不太依赖JVM内存,更注重充分发挥Page Cache的作用。
Page Cache是操作系统中的一种内存管理技术,它通过将磁盘上的数据块缓存在内存中,提供了对数据的快速访问。如果使用应用层缓存(JVM堆内存)可能会加重垃圾回收GC的负担,导致额外的停顿和延迟增加。
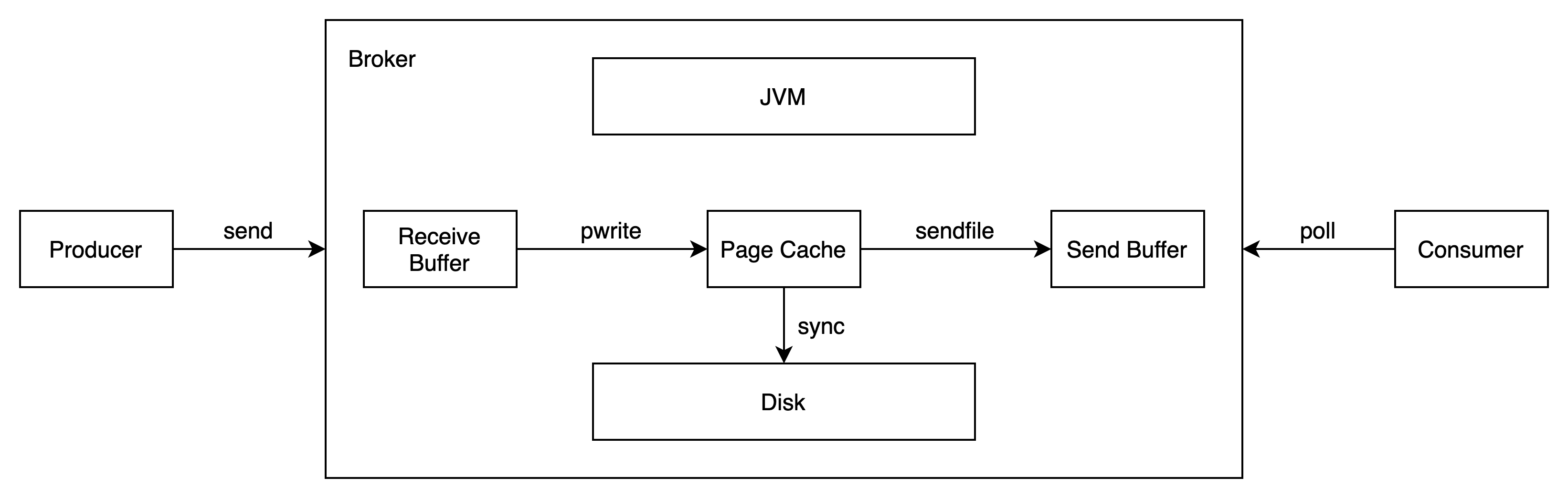
Producer 发送消息到 Broker 时,Broker 会使用 pwrite() 系统调用写入数据,此时数据都会先写入page cache。
Consumer 消费消息时,Broker 使用 sendfile() 系统调用函数,通零拷贝技术地将 Page Cache 中的数据传输到 Broker 的 Socket buffer,再通过网络传输到 Consumer。
leader 与 follower 之间的同步,与上面 consumer 消费数据的过程是同理的。
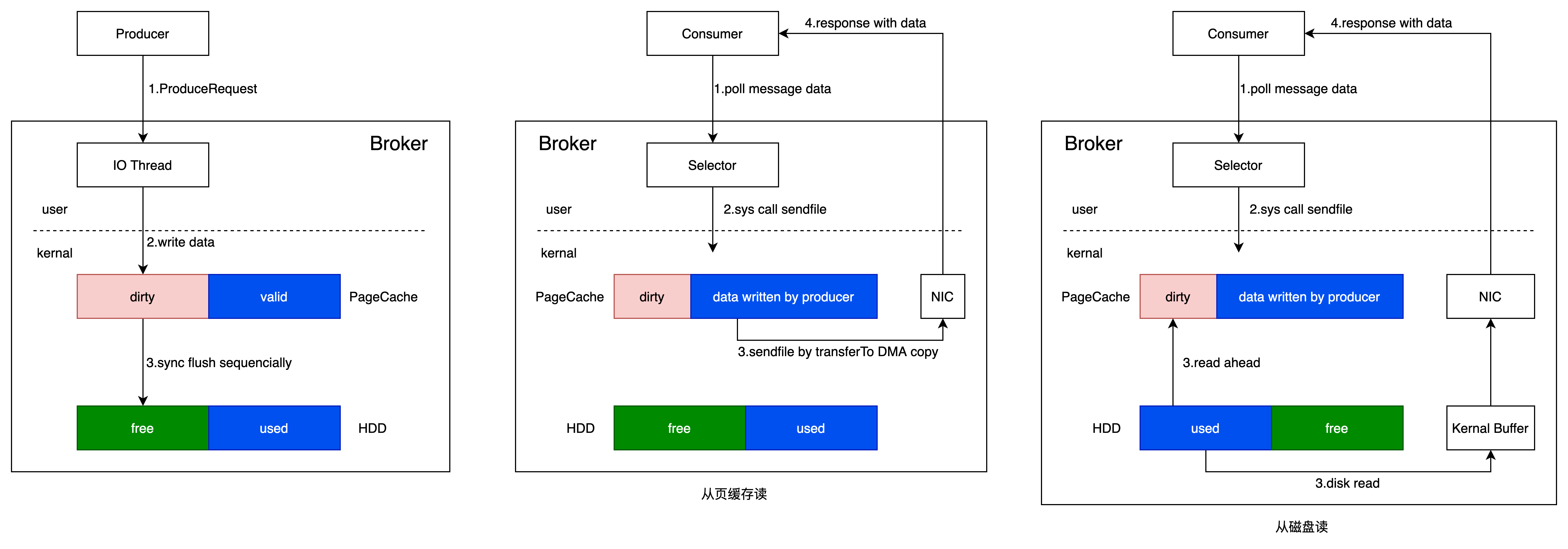 Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。
而Page Cache则将磁盘上的数据块缓存在Page Cache中,使得读取操作能够直接在Page Cache上进行,而无需每次都访问物理磁盘。这样的设计在消费和生产速度相当时尤为有效,甚至在某些情况下可以避免直接在物理磁盘上进行数据交换。当数据块已存在于Page Cache中时,读写操作可以在内存中直接进行,避免了较慢的物理磁盘访问。当Page Cache写满的时候,才会由Kafka进行统一的刷盘操作,来完成数据写入磁盘。
另外,即使Kafka发生重启,Page Cache仍然可用,因为Page Cache是由操作系统管理的,而不是由应用程序控制的。这使得Kafka在重启后能够迅速恢复读取性能,而不必等待缓存重新加载。
零拷贝机制
在Kafka中,大量的网络数据经过两个关键过程进行持久化和传输,直接影响了整个系统的吞吐量。生产者(Producer)将数据通过网络传输到Broker,并在Broker端进行持久化到磁盘的操作。经过磁盘文件,这些数据再通过网络发送给消费者(Consumer)。这两个环节的性能对Kafka整体的吞吐量产生直接而深刻的影响。
传统的数据文件拷贝
传统的数据文件拷贝过程如下图所示
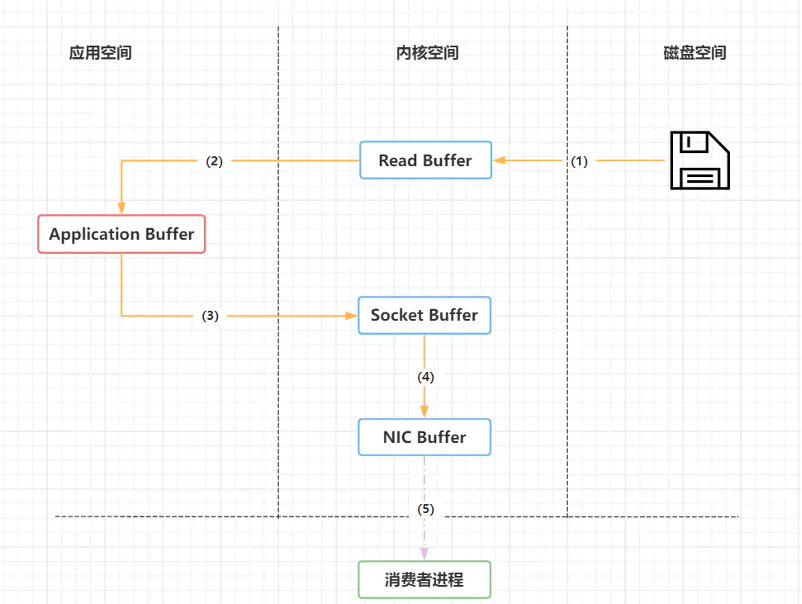
大概可以分成四个过程:
(1)操作系统将数据从磁盘中加载到内核空间的Read Buffer(页缓存区)中。
(2)应用程序将Read Buffer中的数据拷贝到应用空间的应用缓冲区中。
(3)应用程序将应用缓冲区的数据拷贝到内核的Socket Buffer中。
(4)操作系统将数据从Socket Buffer中发送到网卡,通过网卡发送给数据接收方。
传统的数据文件传输需要多次在用户态和核心态进行切换,并且需要把数据在用户态和核心态之间拷贝多次,最终才到达网卡,传输到接收方。
零拷贝(zero copy)
零拷贝中,数据传输的的过程就简化了,如下图所示
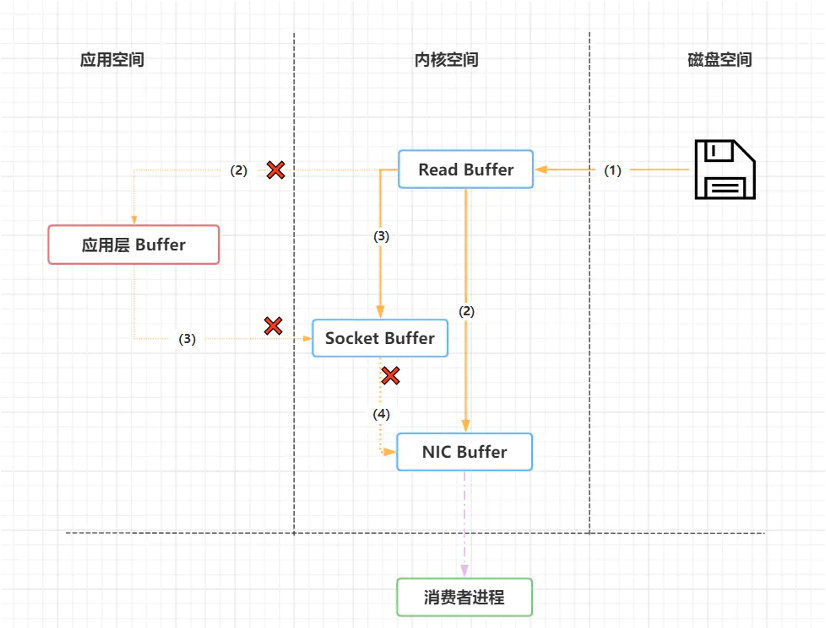
共分为三个步骤:
(1)操作系统将数据从磁盘中加载到内核空间的Read Buffer(页缓存区)中。
(2)操作系统之间将数据从内核空间的Read Buffer(页缓存区)传输到网卡中,并通过网卡将数据发送给接收方。
(3)操作系统将数据的描述符拷贝到Socket Buffer中。Socket 缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到 Socket 缓存。
通过零拷贝基数,不需要把内核空间页缓存中的数据拷贝到应用层缓存,再从应用层缓存拷贝到Socket缓存,这两次拷贝都省略了,所以叫做零拷贝。
这个过程大大地提升了数据消费时读取文件数据的性能。Kafka从磁盘读取数据的时候,会先看看内核空间的页缓存中是否存在,如果存在,则直接通过网关发送出去。
DMA技术
DMA全称Direct Memory Access,直接内存访问,是零拷贝基数的基础。
DMA传输将数据从一个地址空间复制到另一个地址空间。当CPU初始化这个传输动作时,传输动作本身是由DMA控制器来实行和完成的。因此通过DMA,硬件可以绕过CPU,自己去直接访问系统主内存。
很多硬件都支持DMA,包括网卡、声卡、磁盘驱动控制器等。
有了DMA技术的支持后,网卡就可以直接去访问内核空间的饿内存,可以实现内核空间和应用空间之间的零拷贝,极大地提升传输性能。
如何使用zero-copy
如果要使用zero-copy,可通过调用java.nio.channels.FileChannel#transferTo方法来实现。
/**
* Transfers bytes from this channel's file to the given writable byte
* channel.
*
* <p> An attempt is made to read up to <tt>count</tt> bytes starting at
* the given <tt>position</tt> in this channel's file and write them to the
* target channel. An invocation of this method may or may not transfer
* all of the requested bytes; whether or not it does so depends upon the
* natures and states of the channels. Fewer than the requested number of
* bytes are transferred if this channel's file contains fewer than
* <tt>count</tt> bytes starting at the given <tt>position</tt>, or if the
* target channel is non-blocking and it has fewer than <tt>count</tt>
* bytes free in its output buffer.
*
* <p> This method does not modify this channel's position. If the given
* position is greater than the file's current size then no bytes are
* transferred. If the target channel has a position then bytes are
* written starting at that position and then the position is incremented
* by the number of bytes written.
*
* <p> This method is potentially much more efficient than a simple loop
* that reads from this channel and writes to the target channel. Many
* operating systems can transfer bytes directly from the filesystem cache
* to the target channel without actually copying them. </p>
*
* @param position
* The position within the file at which the transfer is to begin;
* must be non-negative
*
* @param count
* The maximum number of bytes to be transferred; must be
* non-negative
*
* @param target
* The target channel
*
* @return The number of bytes, possibly zero,
* that were actually transferred
*
* @throws IllegalArgumentException
* If the preconditions on the parameters do not hold
*
* @throws NonReadableChannelException
* If this channel was not opened for reading
*
* @throws NonWritableChannelException
* If the target channel was not opened for writing
*
* @throws ClosedChannelException
* If either this channel or the target channel is closed
*
* @throws AsynchronousCloseException
* If another thread closes either channel
* while the transfer is in progress
*
* @throws ClosedByInterruptException
* If another thread interrupts the current thread while the
* transfer is in progress, thereby closing both channels and
* setting the current thread's interrupt status
*
* @throws IOException
* If some other I/O error occurs
*/
public abstract long transferTo(long position, long count,
WritableByteChannel target)
throws IOException;transferTo方法的底层实现是基于操作系统的sendfile这个system call来实现的,无需将数据拷贝到用户态,sendfie负责把数据从某个fd(file descriptor)传输到另一个fd。这样就完成了零拷贝的过程。
其他设计
以下设计也为Kafka高性能表现提供了支持。
异步处理设计
Kafka采用全异步的设计,确保在发送和接收消息、以及复制数据等操作中基本上没有阻塞操作。
异步发送: 在Kafka中,调用发送方法(send)会立即返回,而不会等待消息实际被发送到服务器。发送的消息会首先被放入生产者的缓冲区(buffer)中。
缓冲区管理: 缓冲区管理是异步操作的关键。Kafka使用一个内部的缓冲区来暂时保存待发送的消息,当缓冲区满了或者达到一定的条件时,消息会被批量发送。这样可以最大程度地减少网络开销和提高吞吐量。
轮询机制: 发送和接收消息、以及复制数据的过程都是通过NetworkClient封装的poll方式进行的。这种轮询机制是异步操作的关键。在生产者和消费者内部,都有一个后台线程负责轮询缓冲区中的消息并将其发送到目标。这种方式充分利用了异步I/O的特性,不阻塞主线程的执行。
回调机制: 在异步发送的过程中,Kafka提供了回调机制,允许你注册回调函数以处理消息发送的结果。这样,你可以在消息成功发送或发送失败时执行相应的逻辑。
批量操作设计
批量操作在Kafka中是非常关键的性能优化策略之一。结合磁盘顺序写入和异步发送,批量操作可以显著提高Kafka的性能和吞吐量
RecordAccumulator: 在Kafka中,RecordAccumulator是一个用于聚合记录(records)的缓冲区。当生产者发送消息时,消息会首先进入RecordAccumulator,而不是立即发送到服务器。这个缓冲区的存在允许多个消息被批量处理,以减少网络开销。
批量压缩: Kafka支持在消息发送时进行批量压缩,以减小网络传输的数据量。这通过配置Producer的压缩类型(例如snappy、gzip等)来实现。批量压缩可以减轻网络负担,特别是在处理大量数据时,能够显著提高效率。
批量刷盘: Kafka的生产者通常会有一个配置,控制消息何时被批量刷写到磁盘。这可以通过配置batch.size参数,表示RecordAccumulator中的消息数量达到一定阈值时触发批量刷盘。
总的来说,批量操作有助于减少网络开销、提高磁盘顺序写入效率,并在一定程度上降低了系统的延迟。这种机制充分利用了Kafka的异步和缓冲特性,是构建高性能、高吞吐量消息系统的关键设计之一。
数据压缩机制
文件压缩是Kafka中的一个重要性能优化策略,通过减小数据的存储空间和降低网络传输的数据量,可以提高整体系统的效率。以下是有关Kafka文件压缩的一些关键概念和实现:
压缩类型: Kafka支持多种压缩算法,例如snappy、gzip、lz4等。你可以根据具体的需求选择合适的压缩类型。这可以在Producer和Consumer的配置中进行设置。
Producer端压缩: 在Producer端,你可以配置消息在发送时进行压缩。这可以通过设置Producer的compression.type属性来实现。压缩后的消息将占用更小的存储空间,并在网络上传输时减小数据量。
Consumer端解压缩: 在Consumer端,Kafka会自动解压缩消息,无需额外的配置。Consumer从Broker接收到的消息已经是解压缩后的原始数据。这意味着Consumer不需要关心消息是否经过了压缩。
Broker配置: 在Broker端,你可以配置允许或禁止消息压缩。在Kafka的Broker配置文件中,你可以设置compression.type属性,以决定Broker是否接受和存储压缩后的消息。
KafkaServer启动过程
启动过程大致可分为39个过程,如下图所示:
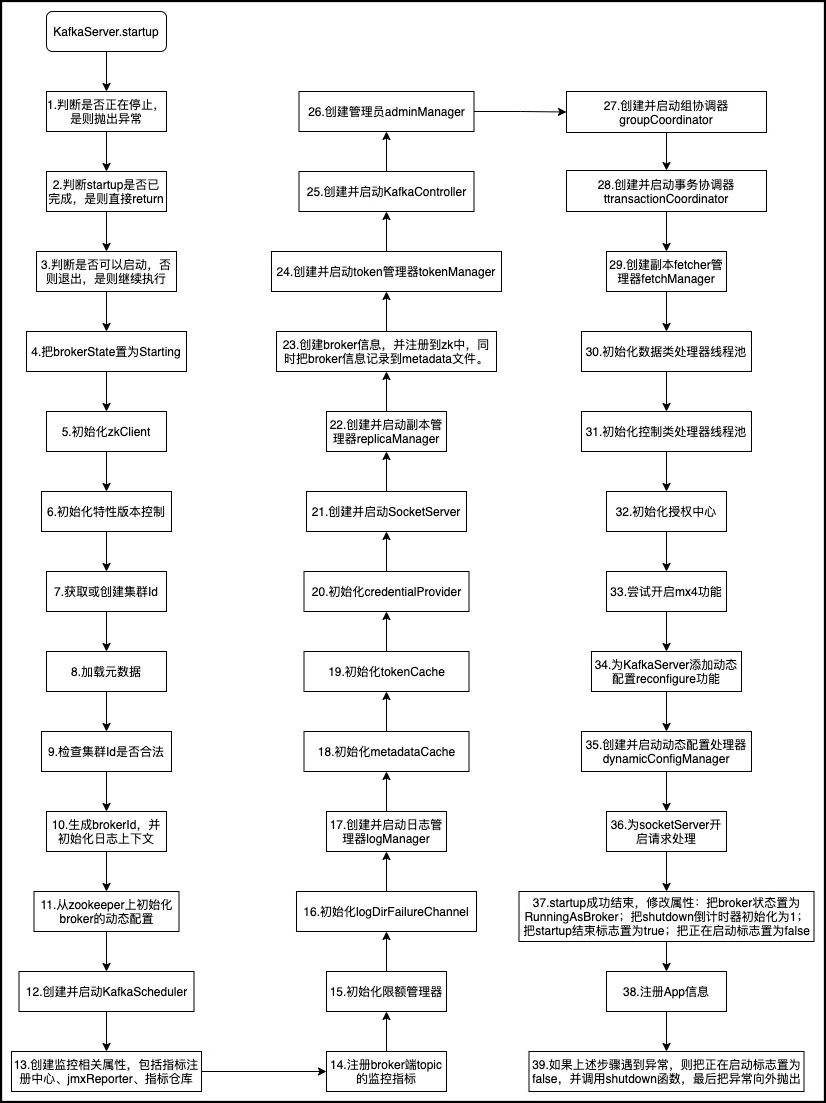 下面对一些重要的过程进行解析。
下面对一些重要的过程进行解析。
KafkaServer启动耗时
数据量的大小会影响kafka启动的耗时,下面是启动过程中的一些日志
[2024-04-01 10:10:49,431] [INFO ] [main:1173] [kafka.utils.Log4jControllerRegistration$] [Logging.scala:31] - Registered kafka:type=kafka.Log4jController MBean
[2024-04-01 10:10:50,005] [INFO ] [main:1747] [org.apache.kafka.common.utils.LoggingSignalHandler] [LoggingSignalHandler.java:72] - Registered signal handlers for TERM, INT, HUP
[2024-04-01 10:10:50,009] [INFO ] [main:1751] [kafka.server.KafkaServer] [Logging.scala:66] - starting
……
[2024-04-01 10:18:17,226] [INFO ] [main:448968] [kafka.network.SocketServer] [Logging.scala:66] - [SocketServer listenerType=ZK_BROKER, nodeId=1] Starting socket server acceptors and processors
[2024-04-01 10:18:17,241] [INFO ] [main:448983] [kafka.network.SocketServer] [Logging.scala:66] - [SocketServer listenerType=ZK_BROKER, nodeId=1] Started data-plane acceptor and processor(s) for endpoint : ListenerName(SASL_PLAINTEXT)
[2024-04-01 10:18:17,242] [INFO ] [main:448984] [kafka.network.SocketServer] [Logging.scala:66] - [SocketServer listenerType=ZK_BROKER, nodeId=1] Started socket server acceptors and processors
[2024-04-01 10:18:17,245] [INFO ] [main:448987] [kafka.server.KafkaServer] [Logging.scala:66] - [KafkaServer id=1] startedBroker节点启动耗时约7.5分钟,总体数据量为8TB,共加载了9000个分区。
Broker启动时间与分区数和segment数相关。
第五步:初始化zkClient
Zookeeper client的创建过程如下图所示:
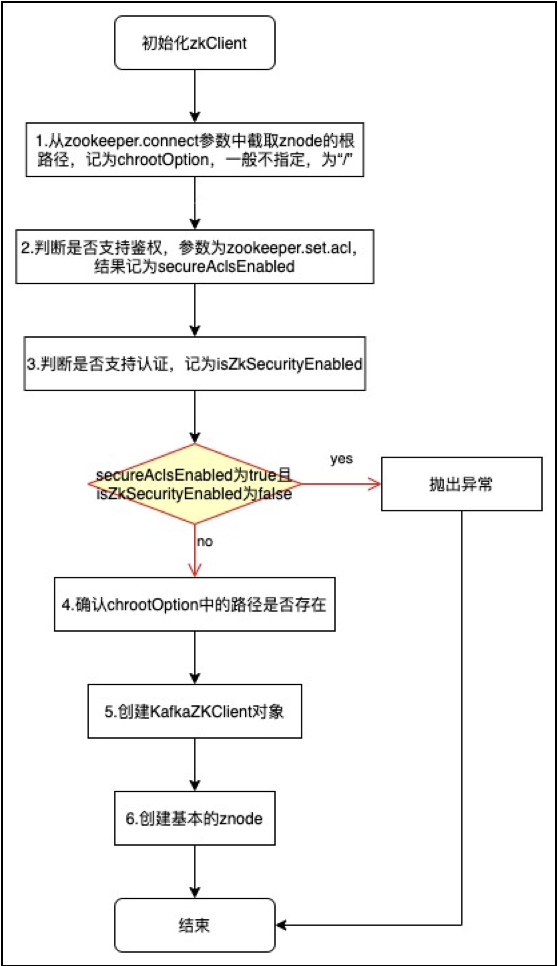 此过程的重点在于创建KafkaZKClient对象,并掌握KafkaZKClient类中所用到的一些函数,以及KafkaServer通过zk进行管理的机制。
此过程的重点在于创建KafkaZKClient对象,并掌握KafkaZKClient类中所用到的一些函数,以及KafkaServer通过zk进行管理的机制。
在第6步中,创建持久节点,通过zkClient.createTopLevelPaths()方法进行创建。zookeeper上的持久节点有以下几个:
/brokers/ids
保存整个kafka集群broker id的一些映射信息。例如下图所示:
 包含所有broker的信息,包括broker id、broker支持的认证方式。
包含所有broker的信息,包括broker id、broker支持的认证方式。
/brokers/topics
保存了所有的topics,以及每个topic对应的分区和副本详情信息。其中:
(1)controller_epoch表示当前controller的版本号(从1开始),也隐式表达了controller进行切换的次数。
(2)leader_epoch表示当前分区leader的版本号(从1开始),隐式表达了leader节点切换的次数。
例如下图所示:
 可以看到,分区0没有经历过leader切换。
可以看到,分区0没有经历过leader切换。
/brokers/seqid
用于生成broker id的序列号。这是一个空节点,不保存任何数据,只为了获取dataVersion,保证broker id递增,不重复。
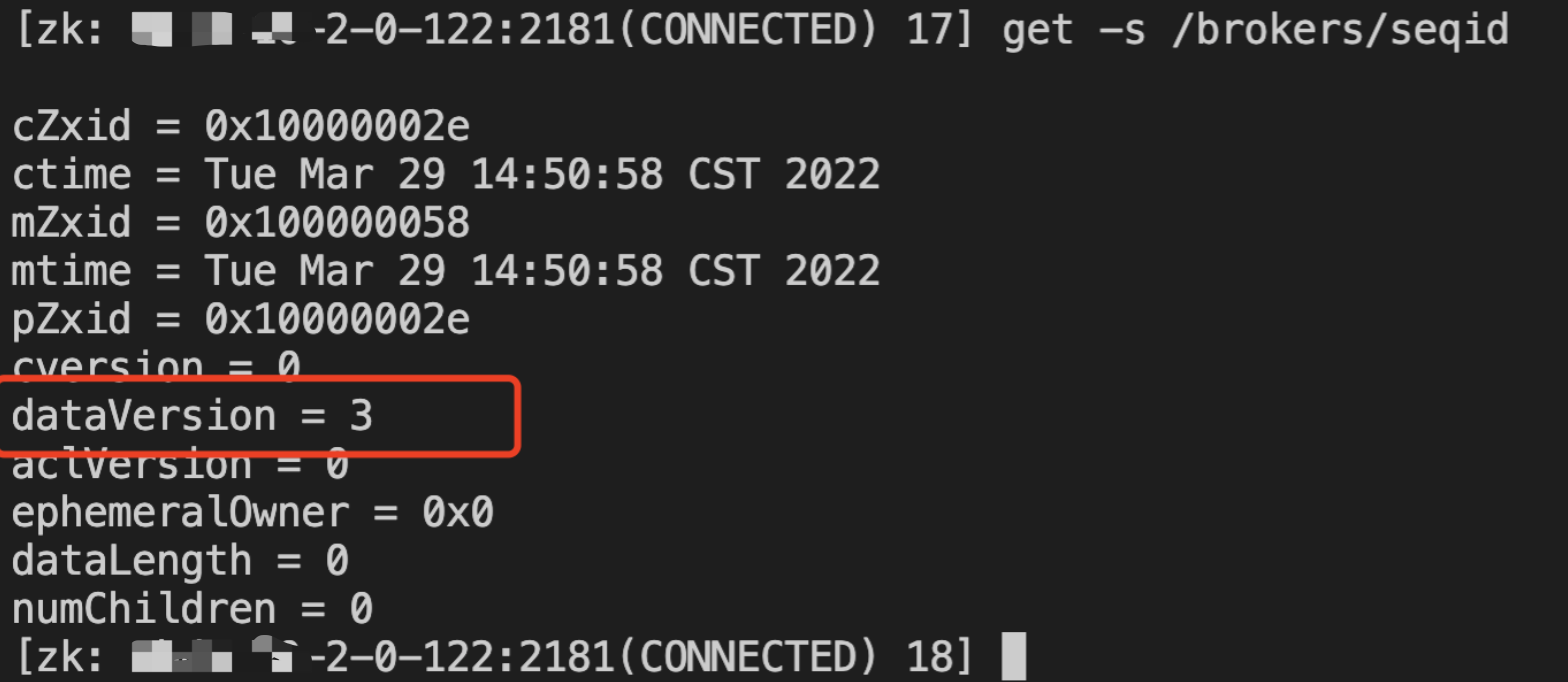 自动生成broker.id的原理是先往/brokers/seqid节点中写入一个空字符串,然后获取返回的Stat信息中的version的值,然后将version的值和reserved.broker.max.id参数配置的值相加可得。之所以是先往节点中写入数据再获取Stat信息,这样可以确保返回的version值大于0,进而就可以确保生成的broker.id值大于reserved.broker.max.id参数配置的值,符合非自动生成的broker.id的值在[0, reserved.broker.max.id]区间的设定。
自动生成broker.id的原理是先往/brokers/seqid节点中写入一个空字符串,然后获取返回的Stat信息中的version的值,然后将version的值和reserved.broker.max.id参数配置的值相加可得。之所以是先往节点中写入数据再获取Stat信息,这样可以确保返回的version值大于0,进而就可以确保生成的broker.id值大于reserved.broker.max.id参数配置的值,符合非自动生成的broker.id的值在[0, reserved.broker.max.id]区间的设定。
这里用到了zkNode的一个特性:可以看到zkNode的dataVersion=0,这个就是前面所说的version。在插入一个空字符串之后,dataVersion就自增1,表示数据发生了变更,这样通过zookeeper的这个功能来实现集群层面的序号递增的功能,整体上相当于一个发号器。
如果log.dir或log.dirs中配置了多个根目录,那么这些根目录中的meta.properties文件所配置的broker.id不一致的话则会报出InconsistentBrokerIdException的异常。
如果config/server.properties配置文件里配置的broker.id的值和meta.properties文件里的broker.id的值不一致的话,同样会报出InconsistentBrokerIdException的异常。如果config/server.properties配置文件中并未配置broker.id的值,那么就以meta.properties文件中的broker.id为准。
如果没有meta.properties文件,那么在获取到合适的broker.id值之后会创建一个新的meta.properties文件并将broker.id的值存入其中。
如果config/server.properties配置文件中并未配置broker.id,并且根目录中也没有任何meta.properties文件(比如服务第一次启动时),那么应该作何处理呢?
/latest_producer_id_block
记录最新的producer_id的块信息。例如下图所示:
 具体这个节点有什么作用,我们在之后的章节中会讲述。
具体这个节点有什么作用,我们在之后的章节中会讲述。
其他zkNodes
其他的zkNode主要有以下9个:
(1)/consumers:这是old consumer path,新版本已经不使用了,数据为空。
(2)/admin/delete_topics:保存已删除,但未被清理的topic,正常状态下数据为空。
(3)/isr_change_notification:记录ISR的变化,通知其他节点。
(4)/log_dir_event_notification:log dir的变更事件。
(5)/config/changes:记录配置的变化。
(6)/config/topics:记录每个topic的配置。
(7)/config/clients:记录客户端配置。
(8)/config/users:记录用户的配置。
(9)/config/brokers:记录broker的配置。
第六步:初始化特性版本控制
这个功能是kafka 2.7版本之后加入的内容。
这是FinalizedFeatureChangeListener类中定义的内容,有一个名为feature-zk-node-event-process-thread的线程进行工作。
第八步:加载broker元数据
Broker元数据加载的过程如下伪代码所示:
private def getBrokerMetadataAndOfflineDirs: (BrokerMetadata, Seq[String]) = {
val brokerMetadataMap = mutable.HashMap[String, BrokerMetadata]()
val brokerMetadataSet = mutable.HashSet[BrokerMetadata]()
val offlineDirs = mutable.ArrayBuffer.empty[String] // 表示该kafka-log目录不可读,可能磁盘损坏
for (logDir <- config.logDirs) {
// 遍历log.dirs或log.dir属性指定的每个磁盘目录
try {
// 读取logDir目录下meta.properties文件,broker元数据记录在brokerMetadataSet变量中
} catch {
case e: IOException =>
offlineDirs += logDir
}
}
if (brokerMetadataSet.size > 1) {
// 抛异常,broker的元数据量大于1
} else if (brokerMetadataSet.size == 1)
(brokerMetadataSet.last, offlineDirs)
else
(BrokerMetadata(-1, None), offlineDirs)
}meta.properties的配置内容例如下图所示:
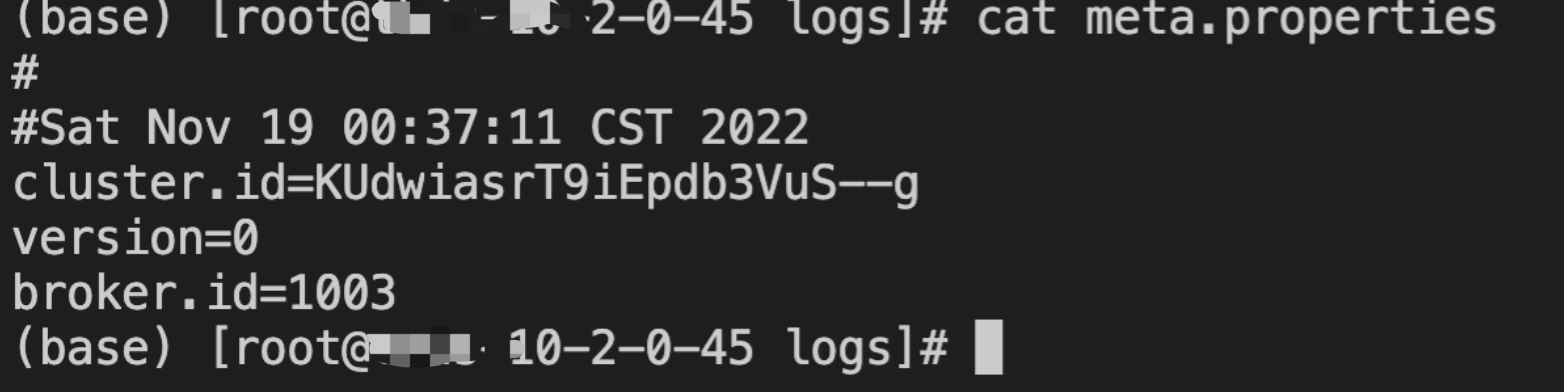 同一个log.dirs中的meta.properties必须属于同一个broker。也就是说broker id是相同的。
同一个log.dirs中的meta.properties必须属于同一个broker。也就是说broker id是相同的。
第十二步:KafkaScheduler初始化
KafkaScheduler类全称为kafka.utils.KafkaScheduler,构造函数中包含以下三个参数:
(1)threads:int,表示线程池线程数量。
(2)threadNamePrefix:表示每个线程名称的前缀,默认为“kafka-scheduler-”。
(3)Daemon:是否守护进程,默认为true。
初始化KafkaScheduler对象需要传入一个参数——线程数,参数配置为background.threads,默认值为10。
启动KafkaScheduler就是初始化一个指定核心线程数量的线程池,对应的类为java.util.concurrent.ScheduledThreadPoolExecutor。
每个线程的类型为org.apache.kafka.common.utils.KafkaThread。
第十七步:LogManager初始化
logManager是kafka-log管理器,在构造函数中包含KafkaConfig和KafkaScheduler,调用代码如下:
logManager = LogManager(config, initialOfflineDirs, zkClient, brokerState, kafkaScheduler, time, brokerTopicStats, logDirFailureChannel)
logManager.startup()LogManager的构造过程中,会调用loadLogs方法,这个方法是用于恢复和加载kafka-logs目录下面的所有LogSegment信息。
private def loadLogs(): Unit = {
for (dir <- liveLogDirs) {
// 遍历当前有效的kafka-logs目录
try {
// 启动一个固定线程数量的线程池,线程数量由num.recovery.threads.per.data.dir参数决定,默认为1
val pool = Executors.newFixedThreadPool(numRecoveryThreadsPerDataDir)
// 判断当前是否处于shutdown过程,如果是shutdown过程,则存在名为“.kafka_cleanshutdown”的标记文件
val cleanShutdownFile = new File(dir, Log.CleanShutdownFile)
if (cleanShutdownFile.exists) {
info(s"Skipping recovery for all logs in $logDirAbsolutePath since clean shutdown file was found")
} else {
info(s"Attempting recovery for all logs in $logDirAbsolutePath since no clean shutdown file was found")
// 设置当前broker的状态为RecoveringFromUncleanShutdown
brokerState.newState(RecoveringFromUncleanShutdown)
}
var recoveryPoints = Map[TopicPartition, Long]()
try {
// 读取kafka-log目录下的recovery-point-offset-checkpoint文件,获取需要恢复到的checkpoint点
recoveryPoints = this.recoveryPointCheckpoints(dir).read()
} catch {
case e: Exception =>
warn(s"Error occurred while reading recovery-point-offset-checkpoint file of directory " +
s"$logDirAbsolutePath, resetting the recovery checkpoint to 0", e)
}
var logStartOffsets = Map[TopicPartition, Long]()
try {
// 读取kafka-log目录下的log-start-offset-checkpoint文件,checkpoint开始的offset
logStartOffsets = this.logStartOffsetCheckpoints(dir).read()
} catch {
case e: Exception =>
warn(s"Error occurred while reading log-start-offset-checkpoint file of directory " +
s"$logDirAbsolutePath, resetting to the base offset of the first segment", e)
}
// 往线程池提交恢复的任务
} catch {
case e: IOException =>
offlineDirs.add((logDirAbsolutePath, e))
error(s"Error while loading log dir $logDirAbsolutePath", e)
}
}
// 等待线程池中的任务都执行完成后,清理响应的标记文件
}下面是启动logManager的伪代码。
def startup(): Unit = {
if (scheduler != null) {
scheduler.schedule("kafka-log-retention",
cleanupLogs _,// 遍历所有的LogSegments,清理未压缩的日志
delay = InitialTaskDelayMs, //延迟30秒
period = retentionCheckMs, //对应配置log.retention.check.interval.ms,默认5*60*1000L
TimeUnit.MILLISECONDS)
info("Starting log flusher with a default period of %d ms.".format(flushCheckMs))
scheduler.schedule("kafka-log-flusher",
flushDirtyLogs _,//将超写回限制时间且存在更新的Log写回磁盘。调用Java NIO中的FileChannel中的force方法,将负责该channel中的所有未写入磁盘的内容写入磁盘。
delay = InitialTaskDelayMs,//延迟30秒
period = flushCheckMs, //对应配置log.flush.scheduler.interval.ms,默认最大LONG值
TimeUnit.MILLISECONDS)
scheduler.schedule("kafka-recovery-point-checkpoint",
checkpointLogRecoveryOffsets _,//向kafka-logs目录下的recovery-point-offset-checkpoint文件写入当前的checkpoint点,避免在重启时需要重新恢复全部数据
delay = InitialTaskDelayMs,//延迟30秒
period = flushRecoveryOffsetCheckpointMs, //对应配置log.flush.offset.checkpoint.interval.ms,默认60000
TimeUnit.MILLISECONDS)
scheduler.schedule("kafka-log-start-offset-checkpoint",
checkpointLogStartOffsets _,//向kafka-logs目录下的log-start-offset-checkpoint文件写入当前存储的日志中的start offset,避免读到已经被删除的日志
delay = InitialTaskDelayMs,//延迟30秒
period = flushStartOffsetCheckpointMs,//对应配置log.flush.start.offset.checkpoint.interval.ms,默认值60000
TimeUnit.MILLISECONDS)
scheduler.schedule("kafka-delete-logs", // will be rescheduled after each delete logs with a dynamic period
deleteLogs _,//清理已经标记为删除的LogSegments
delay = InitialTaskDelayMs,
unit = TimeUnit.MILLISECONDS)
}
if (cleanerConfig.enableCleaner)
cleaner.startup()
}startup方法其实就是往KafkaScheduler中添加了5个定时任务,用于LogSegment的管理。
第二十一步:SocketServer初始化
创建并启动SocketServer
第二十二步:ReplicaManager初始化
创建并启动replicaManager
第二十五步:KafkaController初始化
创建并启动KafkaController
第二十六步:AdminManager初始化
创建管理员adminManager
第二十七步:GroupCoordinator初始化
创建并启动groupCoordinator
第二十九步:FetcherManager初始化
创建fetcherManager
第三十步:数据类处理器线程池初始化
初始化数据类处理器线程池
第三十一步:管理类处理器线程池初始化
初始化管理类处理器线程池