leader选举
选主是zookeeper可实现的最常用的功能。
选主的实现方案如下。
Curator LeaderLatch
LeaderLatch是Curator 框架提供的 Leader 选举实现方案。
LeaderLatch核心方法
await是LeaderLatch的核心方法,主要有两种重载方法
await()
调用该方法会导致当前线程等待,直到此实例获得领导权,除非线程被中断或关闭。如果此实例已经是 Leader,则此方法立即返回 true。否则,当前线程将被禁用并处于休眠状态,直到发生以下三种情况之—:
(1)此实例成为 Leader
(2)其他线程中断当前线程
(3)实例已关闭
await(long timeout, TimeUnit unit)
调用该方法会导致当前线程等待,直到此实例获得领导权,除非线程被中断、指定的等待时间已过或实例已关闭。如果指定的等待时间已过或实例已关闭,则返回 false,如果等待时间小于或等于0,则该方法根本不会等待。如果此实例已经是Leader,则此方法立即返回 true。否则,当前线程将被禁用并处于休眠状态,直到发生以下四种情况之一:
(1)此实例成为 Leader
(2)其他线程中断当前线程
(3)指定的等待时间已过
(4)实例已关闭
通过 await 方法,使用LeaderLatch 进行 Leader 选举就像使用 CountDownLatch 一样方便。
LeaderLatch选举过程
整个选举过程分为三步:
(1)LeaderLatch实例在zk上创建自己的临时有序子节点
参与竞选的LeaderLatch实例在zookeeper上的{latchpath}目录创建临时有序子节点,如{latchpath}/latch-{seqX},值默认为"".getBytes()。

每个LeaderLatch实例都有自己的临时有序节点,当这个LeaderLatch实例停止或者关闭时,对应临时有序节点被删除。
创建新的临时有序节点时,seqX会递增。
(2)选举出leader
LeaderLatch实例创建临时有序节点成功后,执行回调函数,读取节点{latchpath}目录的所有子节点信息,对子节点的名称按{seq}从小到大排序。
判断如果当前创建节点的值为最小的节点值,则断定当前的节点为master节点,回调执行isLeader的listener。
否则当前节点未竞选master成功,成为一个follower。
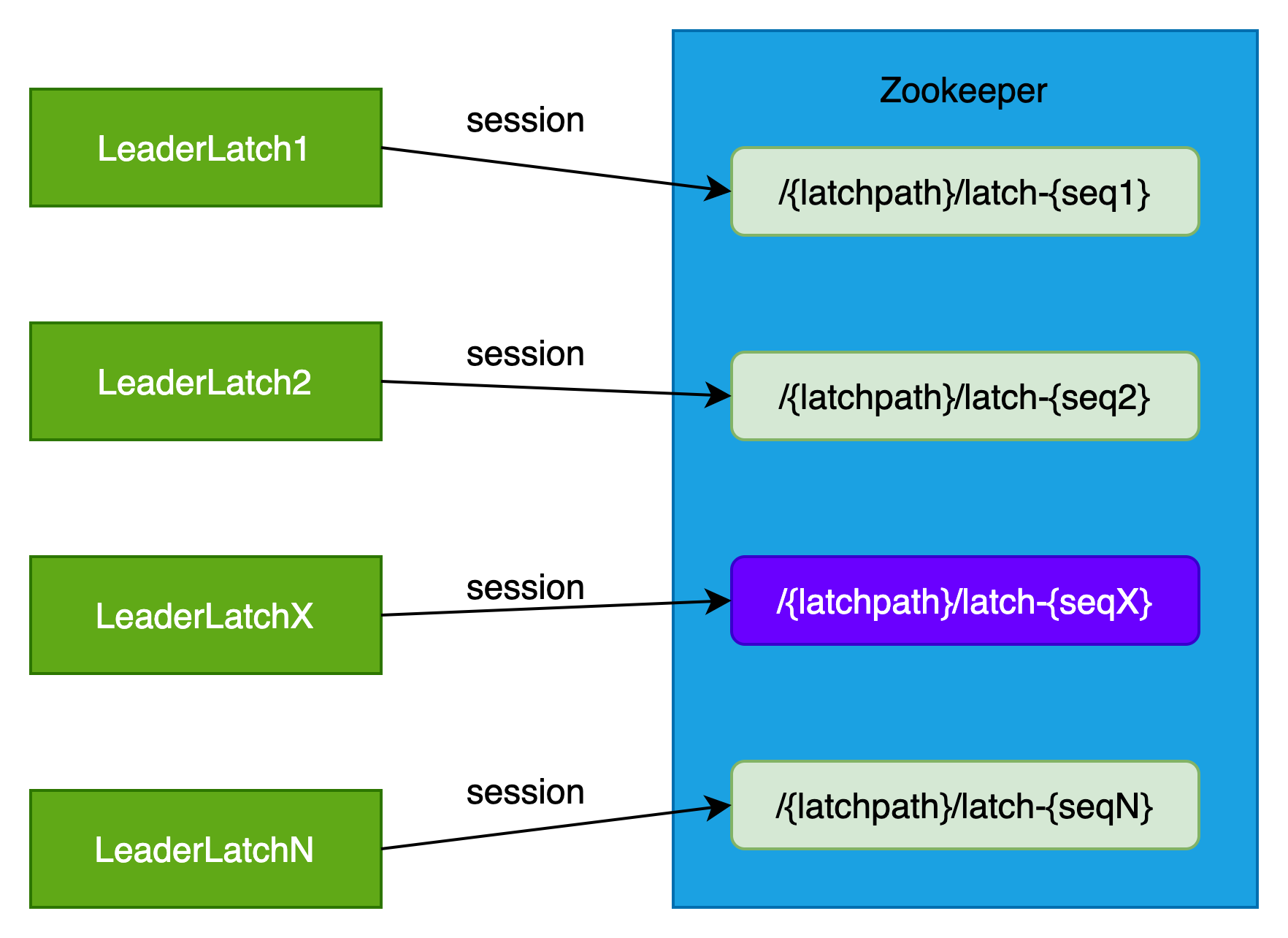
由于seqX的有序性,更早注册的临时有序节点会成为leader。
(3)所有follower角色的LeaderLatch实例注册watcher事件
所有成为follower角色的LeaderLatch实例注册对leader节点watcher事件。
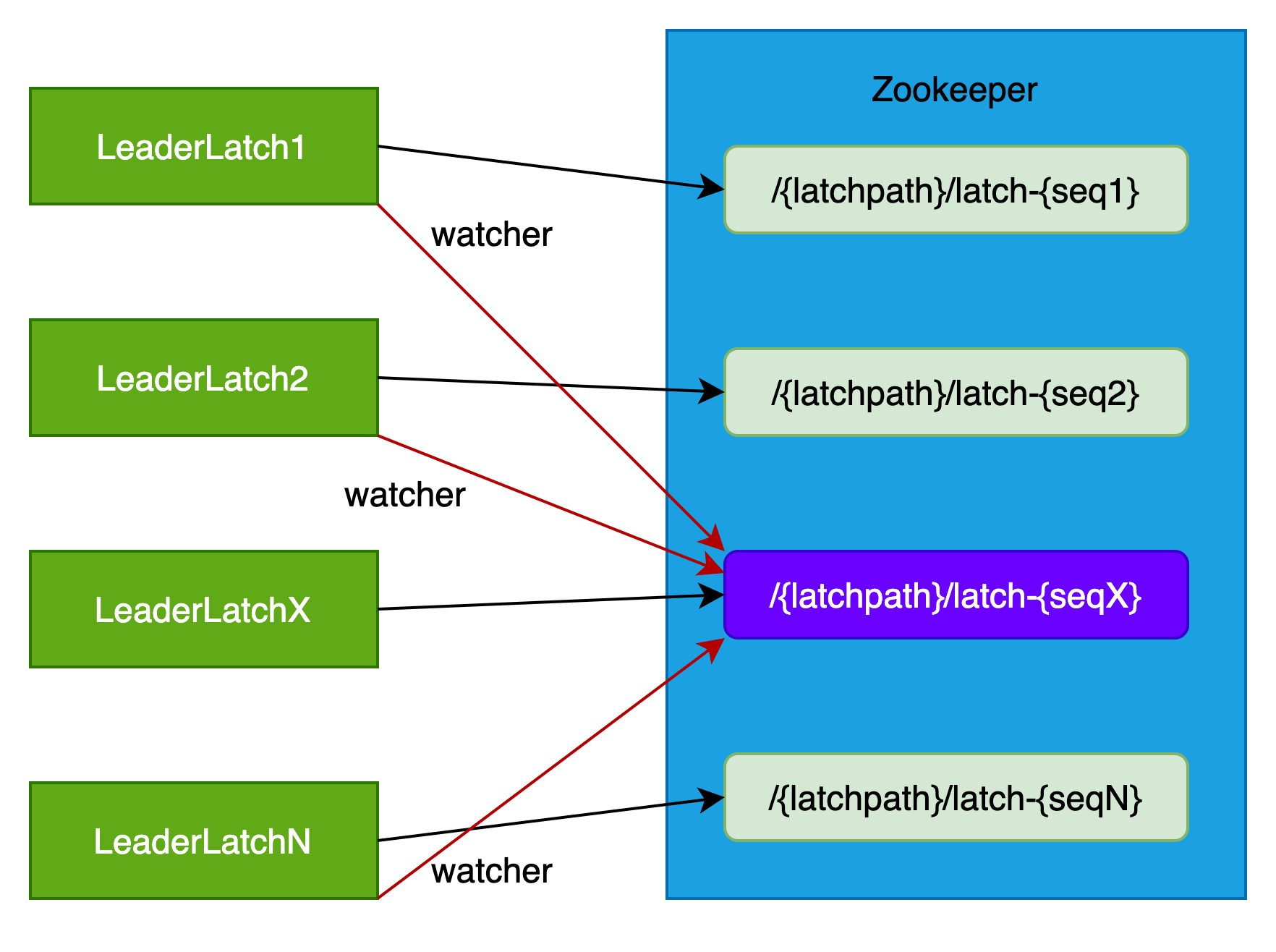
在watcher到NO_NODE事件后,所有的LeaderLatch实例尝试重新竞选master,即执行第(2)步。
LeaderLatch异常处理
LeaderLatch实例可以增加ConnectionStateListener来监听网络连接问题。
当 SUSPENDED 或 LOST 时, leader不再认为自己还是leader。当LOST 连接重连后 RECONNECTED,LeaderLatch会删除先前的ZNode然后重新创建一个。LeaderLatch用户必须考虑导致leadership丢失的连接问题。
强烈推荐使用ConnectionStateListener。
Curator LeaderSelector
LeaderSelector是Curator 框架提供的 Leader 选举实现方案。
LeaderSelector 组件提供了分布式领导者选举的功能,适用于分布式系统中主节点协调场景(如任务调度、资源分配)。
LeaderSelector基于zookeeper的临时顺序节点来实现。
leaderSelector.start()一旦启动,当实例取得领导权时你的listener的takeLeadership()方法被调用。而takeLeadership()方法只有领导权被释放时才返回。 当你不再使用LeaderSelector实例时,应该调用它的close方法。
异常处理 LeaderSelectorListener类继承ConnectionStateListener.LeaderSelector必须小心连接状态的改变。
如果实例成为leader,它应该响应SUSPENDED 或 LOST。
当 SUSPENDED 状态出现时, 实例必须假定在重新连接成功之前它可能不再是leader了。
如果LOST状态出现,实例不再是leader,takeLeadership方法返回。
分布式锁
我们可以通过zookeeper实现分布式锁,实现方式有三种
基于临时节点
核心原理
同名临时节点仅能被一个zookeeper客户端创建一次,当已被创建后,其他客户端继续创建则会报错。
也就是说,所有哪个节点第一次创建了临时节点,该节点即获取了锁。其他节点获取锁失败。
session不断开,则临时节点不会被删除,可以通过此特性来维持锁。
当session断开,则临时节点会被删除,可通过此特性来释放锁。
锁竞争流程
整个锁竞争流程分为三步。
(1)各个节点向zookeeper创建临时节点,比如“/lock”
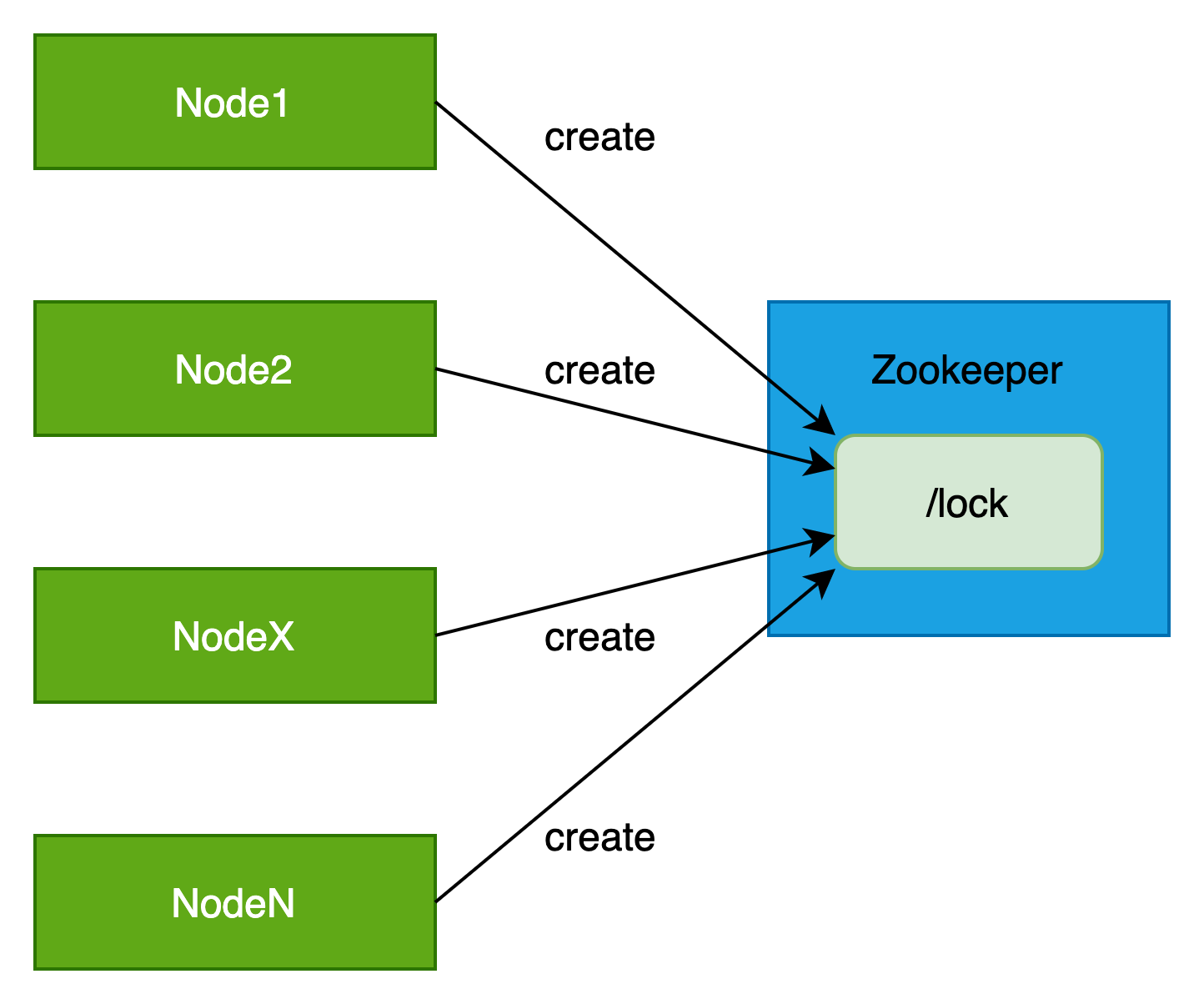
此时所有节点都具备相同的概率去创建临时节点。
(2)有一个人节点创建成功,比如是NodeX,则表示NodeX获取到了锁。其他节点获取锁失败。
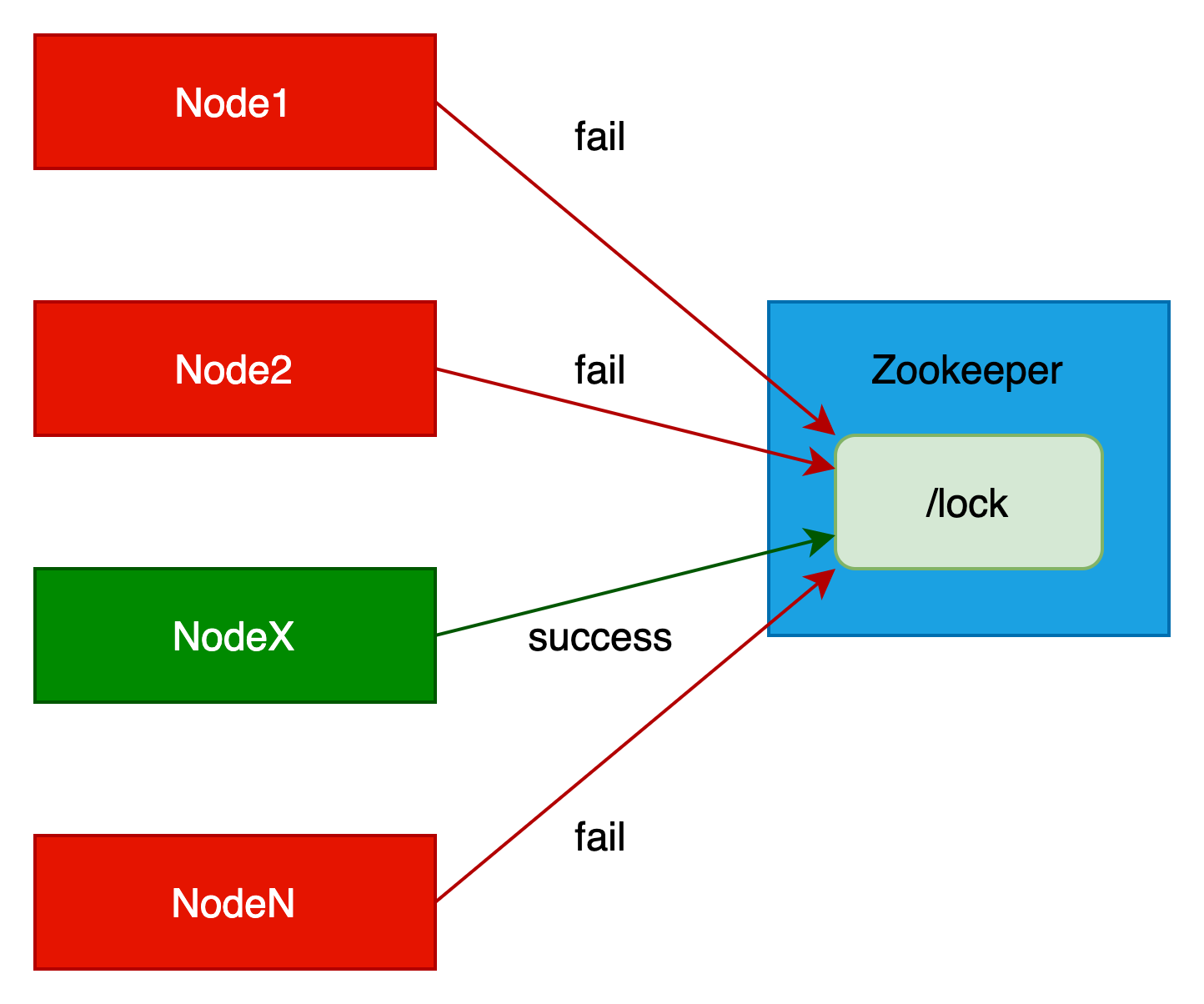
(3)其他未获取锁的节点则通过zookeeper监听器监听锁节点。
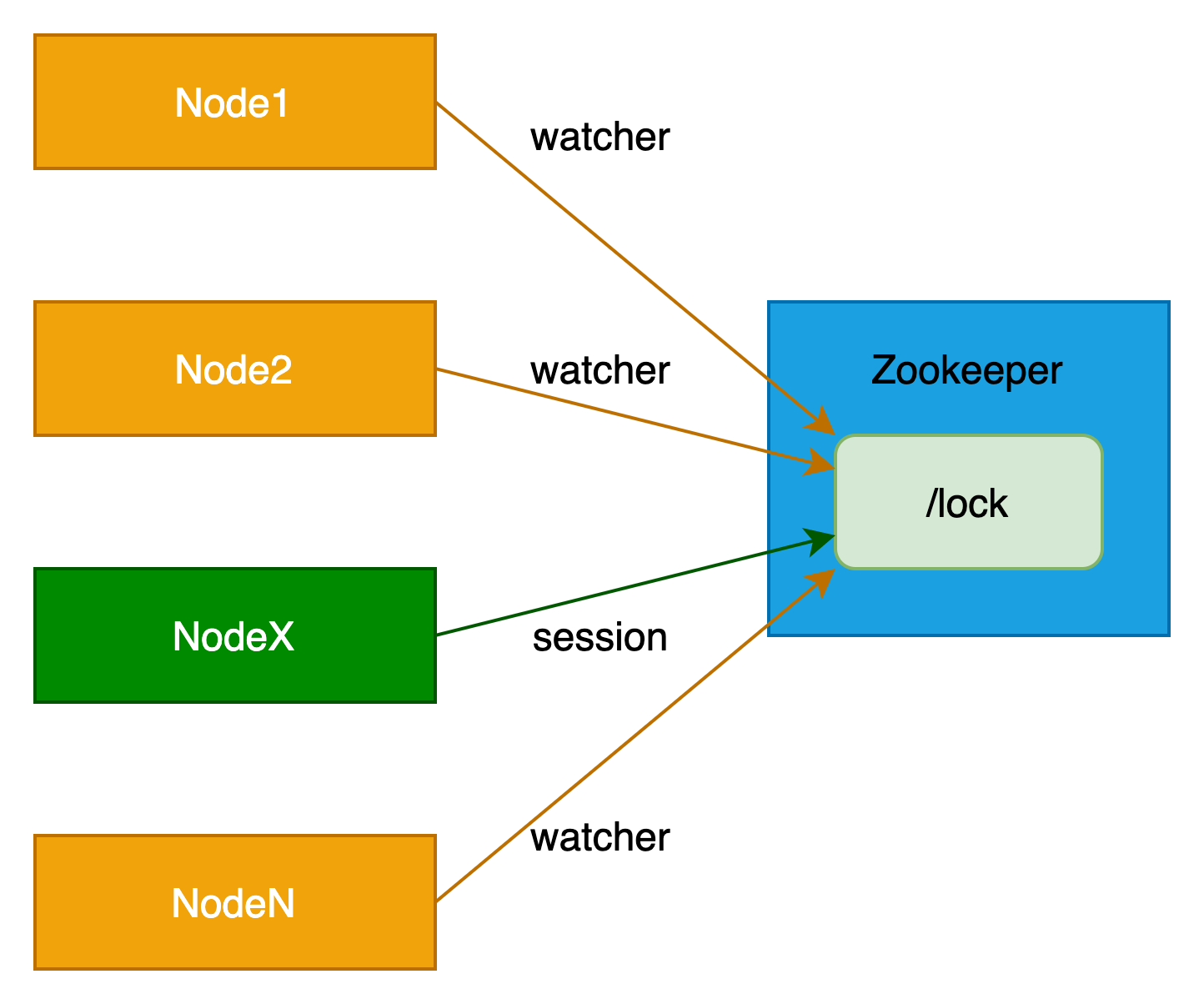
当锁节点被删除,表示锁已被释放,则重新进行锁竞争,即执行(1)步骤。
方案的缺点
可能产生惊群效应。
基于临时顺序节点
基于PERSISTENT_WITH_TTL节点
该方案通过PERSISTENT_WITH_TTL来实现,PERSISTENT_WITH_TTL是带有过期时间的持久节点,如果该znode在给定的TTL时间内未被修改,且该节点无子节点,则该znode会被删除。
核心原理
锁的生命周期相关的方法有3个。
(1)获得锁
获得锁的唯一方法就是创建成功PERSISTENT_WITH_TTL类型的znode,如果znode已经存在,则会抛出异常,提示“Node already exists”,当前session无法获得锁。
(2)维持锁
锁节点为PERSISTENT_WITH_TTL类型,当达到过期时间,锁被释放,锁节点被删除。为了更好地维护当前会话的锁,我们需要维持与zookeeper server之间的心跳,保证锁锁节点能在过期时间内被更新,心跳主要是更新锁节点的数据,这里需要对锁节点数据进行一定的设计,保证和业务逻辑相一致。
(3)释放锁
释放锁有两种情况:主动释放锁,即由zookeeper client删除锁节点znode;被动释放锁,即锁节点znode已过期,被zookeeper server自动删除。
方案的缺点
在维持锁时,需要定期心跳,修改超时时间。
负载均衡
可以通过ZooKeeper 实现服务的负载均衡。
基于临时节点
以下是一种常见的实现负载均衡的方式:
(1)注册服务:每个服务实例在启动时向 Zookeeper 注册自己的信息,包括服务地址、端口等。注意:这里使用 ZooKeeper 的临时节点来存储服务器信息,当客户端连接断开后,临时节点将自动被删除。
(2)服务发现:客户端向 Zookeeper 查询可用的服务实例列表,并选择其中一个进行访问。
(3)监听节点变化:客户端可以注册监听器,当服务实例列表发生变化时,Zookeeper 会通知客户端,客户端可以及时更新可用的服务实例列表。
(4)负载均衡策略:客户端根据负载均衡策略选择一个合适的服务实例进行访问,常见的负载均衡策略有轮询、随机、权重等等。
我们通过以上步骤,Zookeeper 可以实现服务的注册、发现和负载均衡,从而帮助客户端实现对服务实例的动态调度和负载均衡。
配置中心
配置中心功能一般通过持久节点来实现。
ZooKeeper 可以作为一个统一的配置中心,存储和管理应用的配置信息,并通过 Watch 机制实现配置的动态更新。