kafka是一个对磁盘空间严重依赖的服务,因为大部分数据都存储在磁盘中,对内存的要求不高。下面我们看看kafka在磁盘的文件系统结构是怎么样的,以及磁盘怎么实现磁盘存储层面的负载均衡,以及存储层面的横向扩展。
1.数据文件存储目录配置
kafka中,有两个参数和数据存储目录相关。
(1)log.dir:默认值为/tmp/kafka-logs,如果只配置一个目录,则可以使用此参数。
(2)log.dirs:默认值为null,可通过此参数配置配置多个目录,也可以说是多块盘,为空时,使用log.dir。
从这里可以推断出,通过在log.dirs配置多块盘的挂载目录,可以把kafka消息数据均衡地分配到这些磁盘上。
还有一点,kafka的每个数据目录结构都是一样的,log.dirs配置的每块盘在kakfa启动的时候,都会初始化同样的文件系统结构。
下面,我们就通过实践,看看kafka数据文件存储目录下的文件系统结构。
2.存储目录元数据
元数据主要是指:在kafka-logs存储目录中,分区目录以外的文件。
例如
# ls -al /data1/kafka-logs/
drwxrwxr-x 56 nieo nieo 4096 May 13 20:23 .
drwxrwxr-x 5 nieo nieo 49 Apr 28 11:41 ..
-rw-rw-r-- 1 nieo nieo 52 May 8 20:15 cleaner-offset-checkpoint
-rw-rw-r-- 1 nieo nieo 0 Apr 28 11:41 .lock
-rw-rw-r-- 1 nieo nieo 4 May 13 20:22 log-start-offset-checkpoint
-rw-rw-r-- 1 nieo nieo 88 May 8 11:38 meta.properties
-rw-rw-r-- 1 nieo nieo 1559 May 13 20:22 recovery-point-offset-checkpoint
-rw-rw-r-- 1 nieo nieo 1559 May 13 20:23 replication-offset-checkpoint主要包含5个文件。
2.1.meta.properties
记录当前节点的元数据信息。内容如下所示:
# cat /data/emr/kafka/data/meta.properties
#
#Wed May 08 11:38:04 CST 2024
broker.id=1
version=0
cluster.id=AAbC23EEE2iAAdd3R89L7q第一行表示写文件的时间。
第二行表示当前broker的id。是一个随机UUID的base64编码。
第三行表示当前的版本号。
第四行表示集群id。
2.2.cleaner-offset-checkpoint
记录当前cleaner清理完成的各个分区的offset信息。内容如下所示:
# cat /data1/kafka-logs/cleaner-offset-checkpoint
0
2
__consumer_offsets 25 9
__consumer_offsets 37 7文件的读写kafka.server.checkpoints.CheckpointFile类中。
通过write方法,我们可以知道文件的组织结构是什么样的。
(1)第一行表示版本号
(2)第二行表示记录的分区清理offset的记录数
(3)从第三行开始,每一行的格式是“{topic名称} {分区号} {offset值}” 。总行数与第二行的整数是相匹配的。记录格式可参考kafka.server.checkpoints.OffsetCheckpointFile。比如案例中第二行是2,那么就有2条分区清理记录。
2.3.log-start-offset-checkpoint
此文件对应logStartOffset,用来标识日志的起始偏移量。kafka中有一个定时任务负责将所有分区的logStartOffset刷写到起始点文件log-start-offset-checkpoint中,定时周期由broker端参数log.flush.start.offset.checkpoint.interval.ms配置,默认值60000,即60s。
内容如下所示:
# cat /data1/kafka-logs/log-start-offset-checkpoint
0
02.4.recovery-point-offset-checkpoint
负责记录topic被写入磁盘的offset信息。内容如下所示:
# cat /data/emr/kafka/data/recovery-point-offset-checkpoint
0
54
test-perf-producer-consumer 0 102266
……(1)第一行表示OffsetCheckpointFile文件的版本号,当前固定为0。
(2)第二行表示此文件有多少个分区记录。
(3)第三行开始,用“{TOPIC} {PARTITION} {OFFSET}”的格式表示,列举当前broker保存的每个分区的分区号和相应的offset信息。总行数与第二行的整数相匹配。注意,为了简化,案例中省略了其余53条记录。
2.5.replication-offset-checkpoint
用来存储每个replica的HW,表示已经被commited的offset信息。失败的follower开始恢复时,会首先将自己的日志截断到上次的checkpointed时刻的HW,然后向leader拉取消息。kafka有一个定时任务负责将所有分区的HW刷写到复制点文件replication-offset-checkpoint中,定时周期由broker端参数replica.high.watermark.checkpoint.interval.ms配置,默认值5000,即5s。
内容如下所示:
# cat /data1/kafka-logs/replication-offset-checkpoint
0
54
test-perf-producer-consumer 0 102266
……格式与recovery-point-offset-checkpoint类似,只不过offset表示的是HighWatermark对应的offset。
注意,为了简化,案例中省略了其余53条记录。
3.分区目录
分区目录是存储目录下的一个字目录,具体应该称之为分区副本目录,目录名称格式为“{topic名称}-{分区号}”
分区目录下保存的是分区数据文件,如下所示:
# ls -al /data1/kafka-logs/test-perf-producer-consumer-0
total 52004
drwxrwxr-x 2 nieo nieo 204 May 8 21:48 .
drwxrwxr-x 56 nieo nieo 4096 May 13 20:29 ..
-rw-rw-r-- 1 nieo nieo 10485760 May 8 21:48 00000000000000051131.index
-rw-rw-r-- 1 nieo nieo 53134775 May 8 01:57 00000000000000051131.log
-rw-rw-r-- 1 nieo nieo 10485756 May 8 21:48 00000000000000051131.timeindex
-rw-rw-r-- 1 nieo nieo 10 May 8 18:07 00000000000000102266.snapshot
-rw-rw-r-- 1 nieo nieo 13 May 8 21:48 leader-epoch-checkpoint
-rw-rw-r-- 1 nieo nieo 43 Apr 28 19:54 partition.metadata其中包含两个分区元数据文件,以及3个segment文件。
3.1.partition.metadata
分区元数据信息,文件内容如下:
# cat /data1/kafka-logs/test-perf-producer-consumer-0/partition.metadata
version: 0
topic_id: ABcdE0T1FFFdLL8BBjiLzc第一行表示版本号。
第二行表示topic的id。
3.2.leader-epoch-checkpoint
用于保存leader的epoch信息。内容如下所示:
# cat /data1/kafka-logs/test-perf-producer-consumer-0/leader-epoch-checkpoint
0
1
57 51131该文件在kafka.server.checkpoints.LeaderEpochCheckpointFile类中定义,文件格式也在类中进行了说明。
(1)第一行表示版本号。
(2)第二行表示记录数。
(3)第三行表示真正的记录,格式为“{epoch} {startOffset}”。epoch是leader版本,它是一个单调递增的一个正整数值,每次leader变更,epoch版本都会+1,小版本号的Leader被认为是过期Leader,不能再行使Leader权力。startOffset是每一代leader写入的第一条消息的位移值,即Leader副本在该Epoch值上写入的首条消息的位移。
3.3.segment段
每个分区都是由不同的segment组成,而一个segment由4个文件组成。
因为kafka中每个分区内数据都是顺序的,所以segment段文件也是顺序写入的,可以通过offset来命名段文件。
3.3.1.segment log文件
命名格式为“{起始offset}.log”。其中,{起始offset}是20位的十进制数字,不足20位的话前序填“0”补齐。
文件例如
0000000000000000000.log -> 有50条,offset为 0-49
0000000000000000050.log -> 有10条,offset为 50-59
0000000000000000060.log -> 有xx条,offset从60-xx文件中按照offset顺序记录了每一条消息。
我们把log文件内存储的消息集合称为record batch,每条消息就是一个record,segment格式以及record的格式如下图所示:
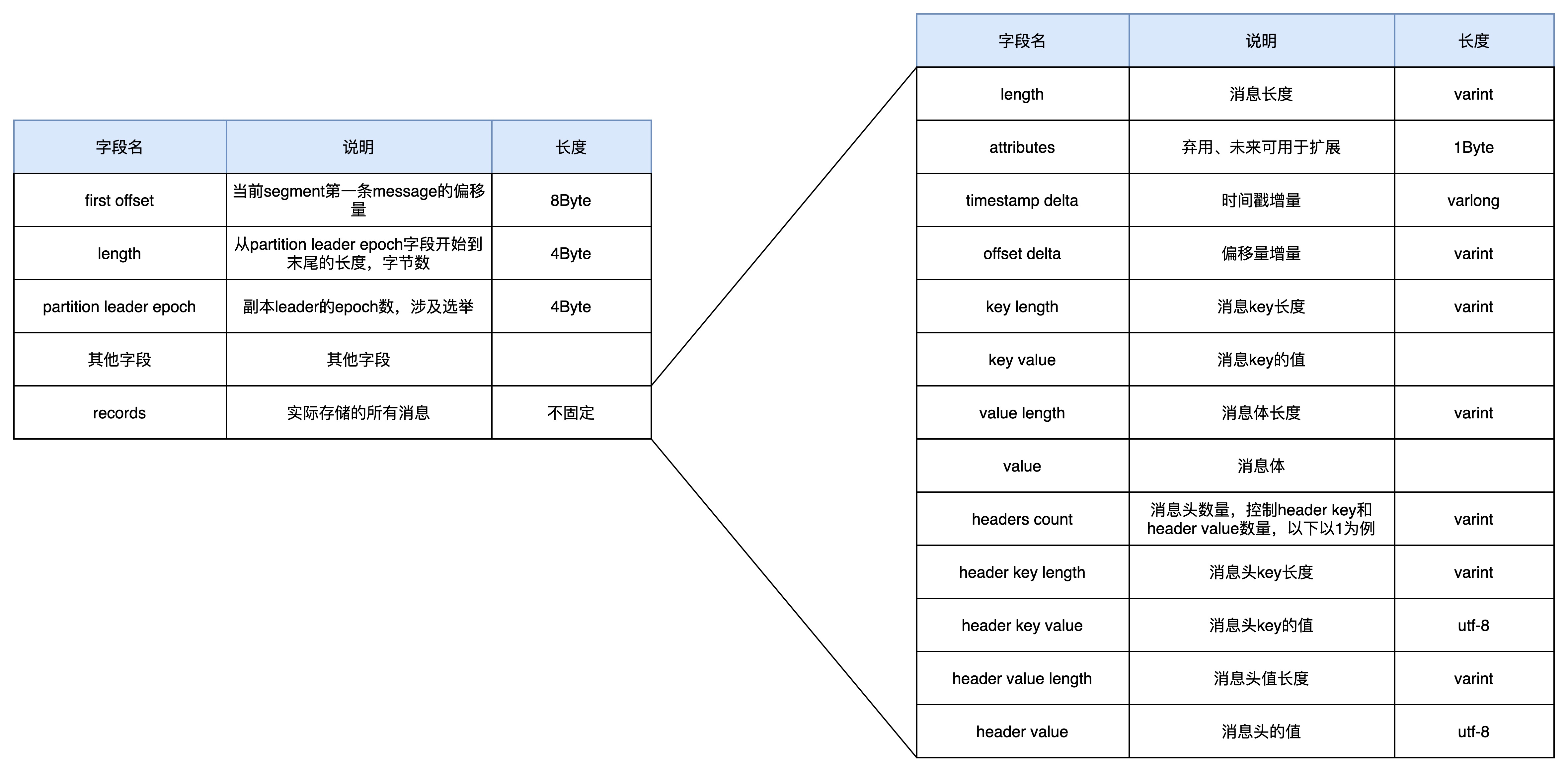
每条消息除了实际内容的value外,伴随着每条消息的产生,还会产生这条消息的额外附带信息,比如偏移量、时间戳等。
图中有大量的varint和varlong的字段,这就是可变长度的类型。
比如一条消息的偏移量是int存储容量是4字节,比如存储10这个偏移量,虽然前面都是0,但实际存储还是需要4个字节。
而varint则可以根据数据的范围选择合适的存储,比如还是10,那么实际记录这个值只需要1个字节就够了。
kafka这么做,就是为了尽最大的可能利用存储空间。
可以通过以下命令查看log文件中存放的是具体的每条消息
kafka-run-class.sh kafka.tools.DumpLogSegments --files XXXXXX.log --print-data-log输出以下字段信息:
(1)baseOffset:当前batch中第一条消息的位移。
(2)lastOffset:最新消息的位移相对于第一条消息的唯一增量。
(3)count:当前batch有的数据数量,kafka在进行消息遍历的时候,可以通过该字段快速的跳跃到下一个batch进行数据读取。
(4)partitionLeaderEpoch:记录了当前消息所在分区的 leader 的服务器版本,主要用于进行一些数据版本的校验和转换工作。
(5)crc:当前整个batch的数据crc校验码,主要用于对数据进行差错校验的。
(6)compresscode:数据压缩格式,主要有GZIP、LZ4、Snappy三种。
(7)Sequence、producerId、producerEpoch:这三个参数主要是为了实现事务和幂等性而使用的,其中producerId和producerEpoch用于确定当前 producer 是否合法,而起始序列号则主要用于进行消息的幂等校验。
(8)isTransactional:是否开启事务。
(9)magic:Kafka服务程序协议版本号。
(10)CreateTime:数据创建的时间戳。
(11)payload:实际存储的数据。
3.3.2.segment index文件
命名格式为“{起始offset}.index”
文件内容格式为:(offset, 内存偏移地址)
下面,我们通过一个案例来说明index文件和log文件在检索过程中的作用。
需求:consumer发起请求要求从offset=36的消息开始消费
第一步:kafka直接offset的大小,找到对应的log文件,发现36号消息在0000000000000000000.log这个log文件中。
第二步:log文件找到后,需要确认具体的消息在哪?这时需要根据log文件名确定index文件名,找到0000000000000000000.index文件,找到offset为36和37的文件偏移量,发现(36, 12345)和(37, 12400)。
第三步:从0000000000000000000.log文件的12345开始读,读到12400(不包含)为止。也就是读到下一条消息的偏移量停止就可以。这样就读取了一整条消息。如果是批量消息,也是类似的。
通过以下命令查看index文件的内容
kafka-run-class.sh kafka.tools.DumpLogSegments --files XXXXXX.index --print-data-log输出内容包含以下字段
(1)offset:这条数据在这个 Segment 文件中的位置,是这个文件的第几条。
(2)position : 这条数据在 Segment 文件中的物理偏移量。
3.3.3.segment timeindex文件
命名格式为“{起始offset}.timeindex”
通过以下命令查看index文件的内容
kafka-run-class.sh kafka.tools.DumpLogSegments --files XXXXXX.timeindex --print-data-log输出内容包含以下字段
(1)timestamp:该日志段目前为止最大时间戳。
(2)offset:记录的是插入新的索引条目时,当前消息的偏移量。
3.3.4.segment snapshot文件
命名格式为“{}.snapshot”