1.Hive架构图
官方架构图如下图所示:
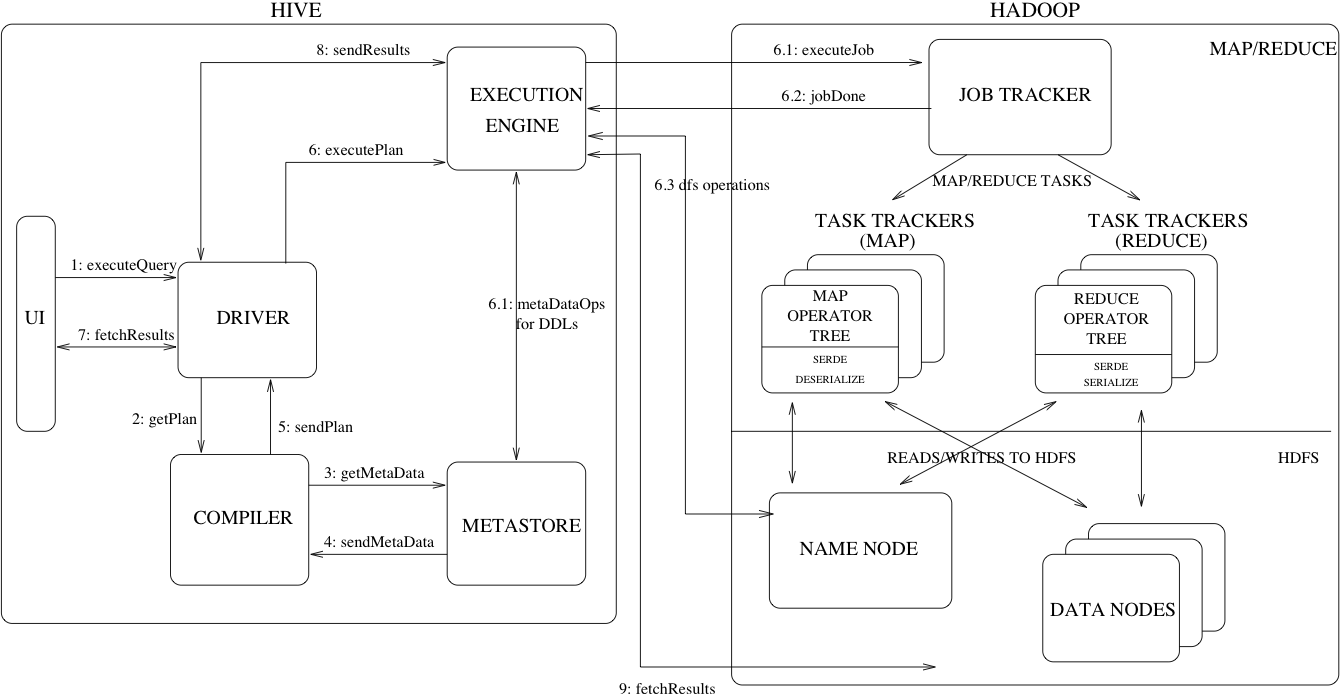
可以看到Hive中主要有五个模块:
(1)UI:用户提交查询和其他操作的交互接口,在2011年Hive就提供了命令行终端和GUI web页面。
(2)Driver:接收查询的组件。这个组件实现了会话管理,通过JDBC/ODBC来提供execute和fetch接口。
(3)Compiler:这个组件会对查询语句进行转换,执行语法解析,在metastore中存在的表和分区元数据的帮助下,最终生成一个执行计划。
(4)Metastore:这个组件保存数据仓库中不同表和分区的结构化数据,包括列、列类型、序列化和反序列化器,这些数据有利于从HDFS中读取数据。
(5)Execution Engine:这个组件用于执行Compiler生成的执行计划。执行计划是一个DAG任务树。执行引擎管理执行计划不同阶段的任务依赖关系,并在正确的系统组件中执行该任务。
2.Hive Metastore——HMS
Metastore只负责提供操作元数据的接口,不负责存储元数据,元数据保存在MySQL或derby数据库当中。
2.1.HMS的运行模式
Metastore有两种运行模式,分别是:嵌入式模式和独立服务模式。
2.1.1.HMS嵌入式模式
嵌入式模式就是metastore作为jar包,加入到hiveserver2或hive cli进程的classpath中。部署架构如下图所示:
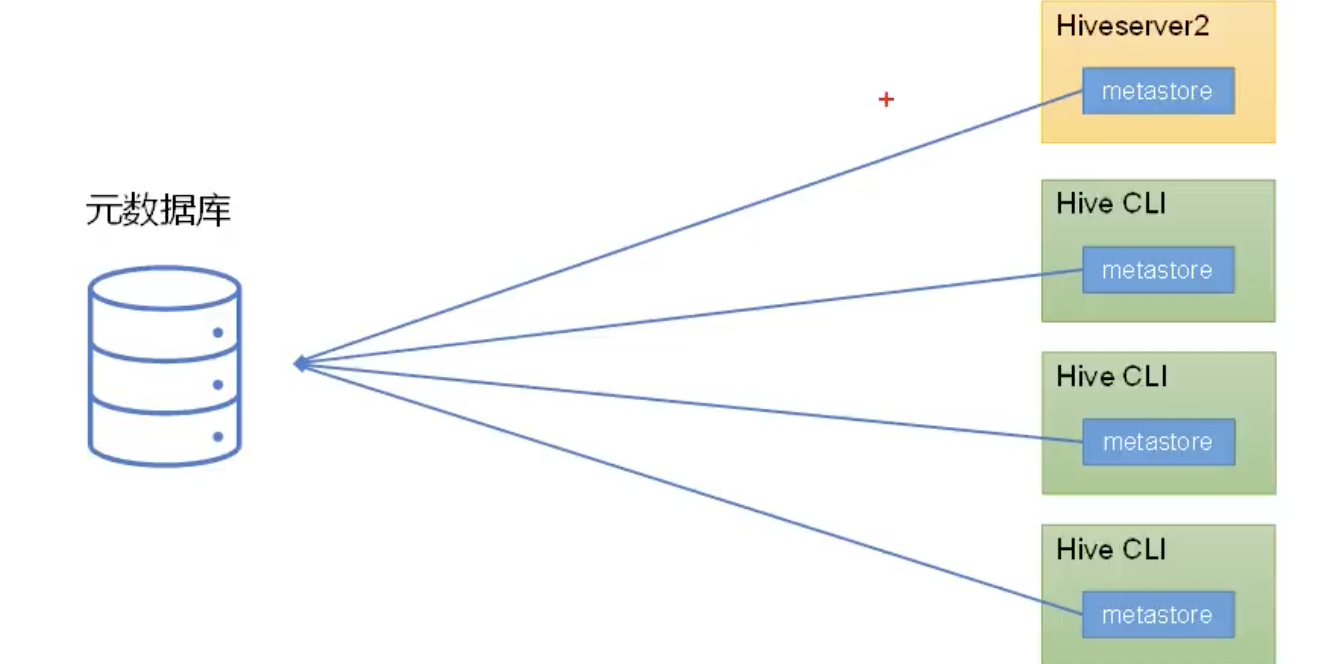
这里可以看出Hiveserver2和Hive Cli都是直接调用metastore的方法去操作元数据库,而不是通过RPC接口访问。
2.1.2.HMS独立服务模式
Metastore服务独立出来,作为单独的进程提供服务。Hiveserver2和Hive Cli不直接连接元数据库,而是通过metastore的RPC接口操作元数据。
部署架构如下图所示:
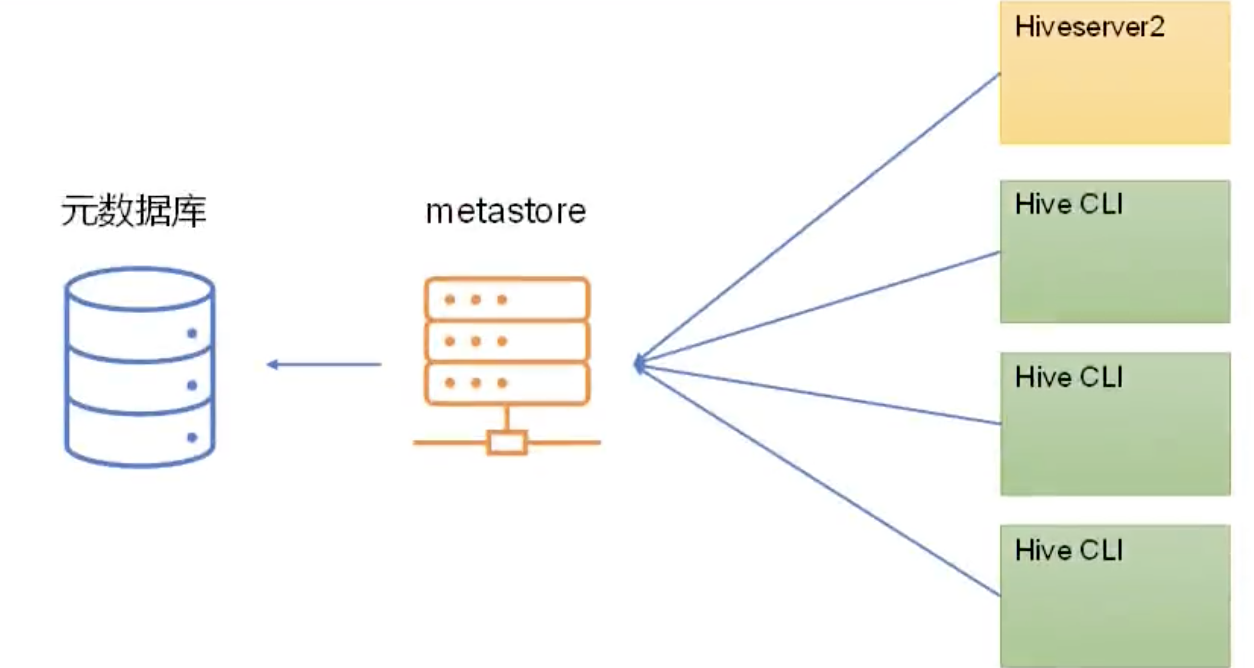
生产环境下,不允许使用嵌入式模式,有两点原因:
(1)嵌入式模式下,每个Hive Cli都需要直接连接元数据库,当Hive Cli较多时,元数据库压力较大。
(2)每个客户端都需要元数据库的读写权限,元数据库的安全得不到很好的保证。
2.2.HMS部署
不同的运行模式对应不同的部署模式。
嵌入式模式下,只需要保证Hiveserver2和每个Hive Cli的配置文件hive-site.xml中包含以下连接元数据库所需要的参数即可。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<description>HMS嵌入式运行模式下,对应的元数据库的jdbc url</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>HMS嵌入式运行模式下,对应的元数据库的jdbc连接驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<description>HMS嵌入式运行模式下,对应的元数据库的jdbc连接用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<description>HMS嵌入式运行模式下,对应的元数据库的jdbc连接密码</description>
</property>独立服务模式下,首先,需要保证metastore服务的配置文件hive-site.xml中包含连接元数据库所需的信息,参数名称与嵌入式模式一样。
然后,需要保证每个Hive Cli和Hiveserver2的配置文件hive-site.xml中包含访问metastore服务所需的以下参数:
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>HMS独立服务运行模式下,对应的metastore服务的地址</description>
</property>如果在Hive Cli的hive-site.xml中既配置了metastore的地址,又配置了元数据库的信息。Hive Cli会优先选择连接metastore。
3.HiveServer2
HiveServer2提供JDBC和ODBC的访问接口,提供用户认证的相关功能。
3.1.用户模拟
远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由HiveServer2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需要考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是HiveServer2的启动用户?还是客户端的登录用户。
由参数hive.server2.enable.doAs控制,表示是否启用Hiveserver2用户模拟的功能。若为true,表示Hiveserver2会模拟成客户端的登录用户去访问Hadop集群的数据;若为false,Hiveserver2会直接使用HiveServer2的启动用户去访问Hadoop集群数据。
在生产环境,建议开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
3.2.HiveServer2用户模拟 vs Hadoop代理用户
HiveServer2的用户模拟功能依赖Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此需要将hiveserver2的启动用户设置为Hadoop的代理用户,需要在core-site.xml添加如下配置(启动用户为hippo):
<property>
<name>hadoop.proxyuser.hippo.groups</name>
<value>*</value>
<description>配置hippo用户能够代理的用户组为任意组</description>
</property>
<property>
<name>hadoop.proxyuser.hippo.hosts</name>
<value>*</value>
<description>配置所有节点的hippo用户都可以作为代理用户</description>
</property>
<property>
<name>hadoop.proxyuser.hippo.users</name>
<value>*</value>
<description>配置hippo用户能够代理的用户为任意用户</description>
</property>星号(*)表示所有,也可以是具体的值,比如我的hiveserver2在host1上,那么我可以配置hadoop.proxyuser.hippo.hosts为host1,表示只允许host1上的通过hippo用户启动的hiveserver2可以代理。
4.Compiler
生成执行计划的过程,分为以下阶段:
4.1.语法解析——SQLParser
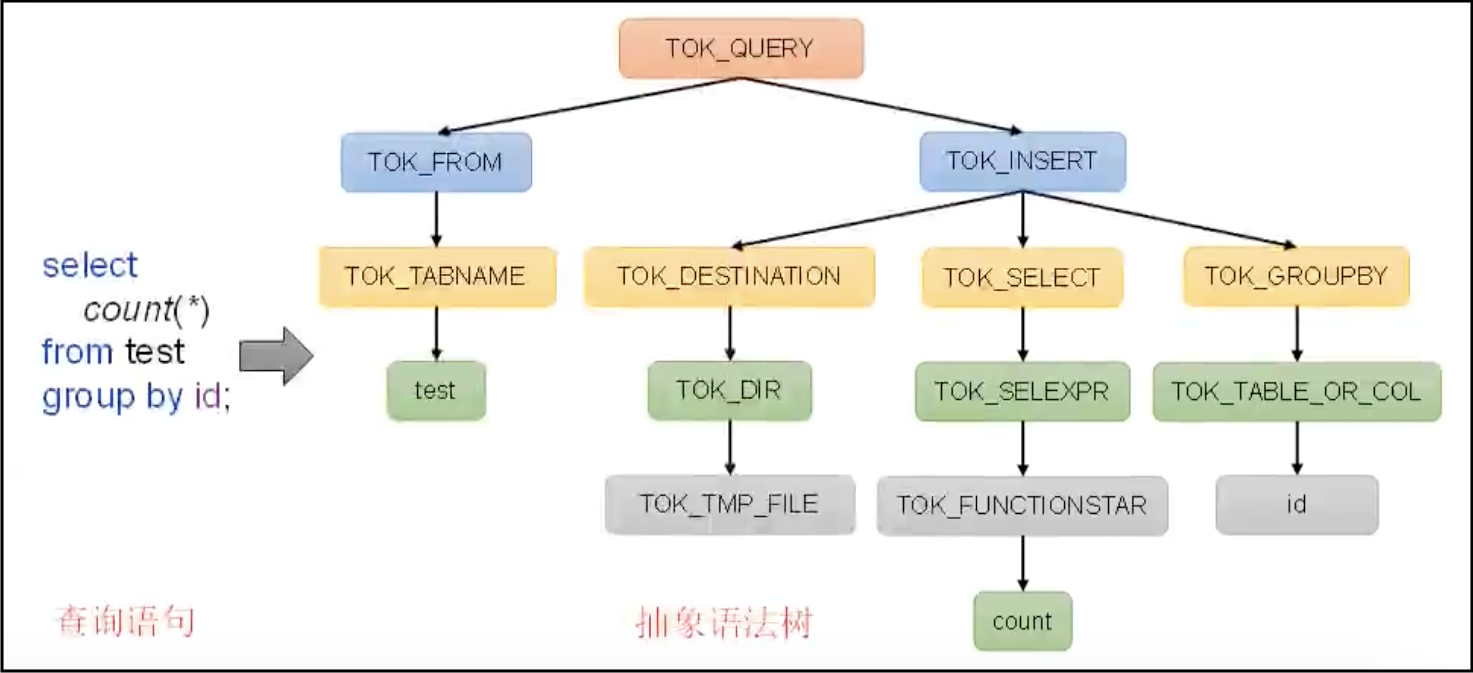
将SQL字符串转换成抽象语法树(AST)。语法解析包括:词法分析和语法分析。
词法分析:识别sql中的关键字。对用户的sql字符串进行遍历,根据预制规则,识别到关键的单词(比如select、from、where),然后生成一个一个的token(比如select token、where token等)。
语法分析:将词法分析生成的一系列的token进行进一步的分析。将若干个token组成一个一个的短句,比如将where条件组合成表达式。然后将一个个短句组合成一个完整的语法结构。因为我们的sql通常都是层层嵌套的,所以得到的语法结构是一个树状结构,这也就是语法解析的结果——抽象语法树(AST)。
典型的AST案例如下图所示:
4.2.语义分析——Semantic Analyzer
将SQLParser生成的AST进一步划分为QueryBlock。一条SQL中可能包含多个子查询,每个子查询就是一个查询单元,也就是一个QueryBlock。划分QueryBlock后,还需要去MetaStore中获取Hive的元数据信息,并填充到各个QueryBlock中。
4.3.逻辑计划生成器——Logical Plan Generator
根据SQLPaser中生成的AST,生成对应的逻辑计划。逻辑计划是通过逻辑操作树(Logical Operator Tree)来表示。一个Operator对应一个单一的逻辑操作,一系列的Operator组合成了一个逻辑计划。常用的Operator有Select Operator、Filter Operator、GroupBy Operator、Join Operator等。
典型的逻辑计划如下图所示:
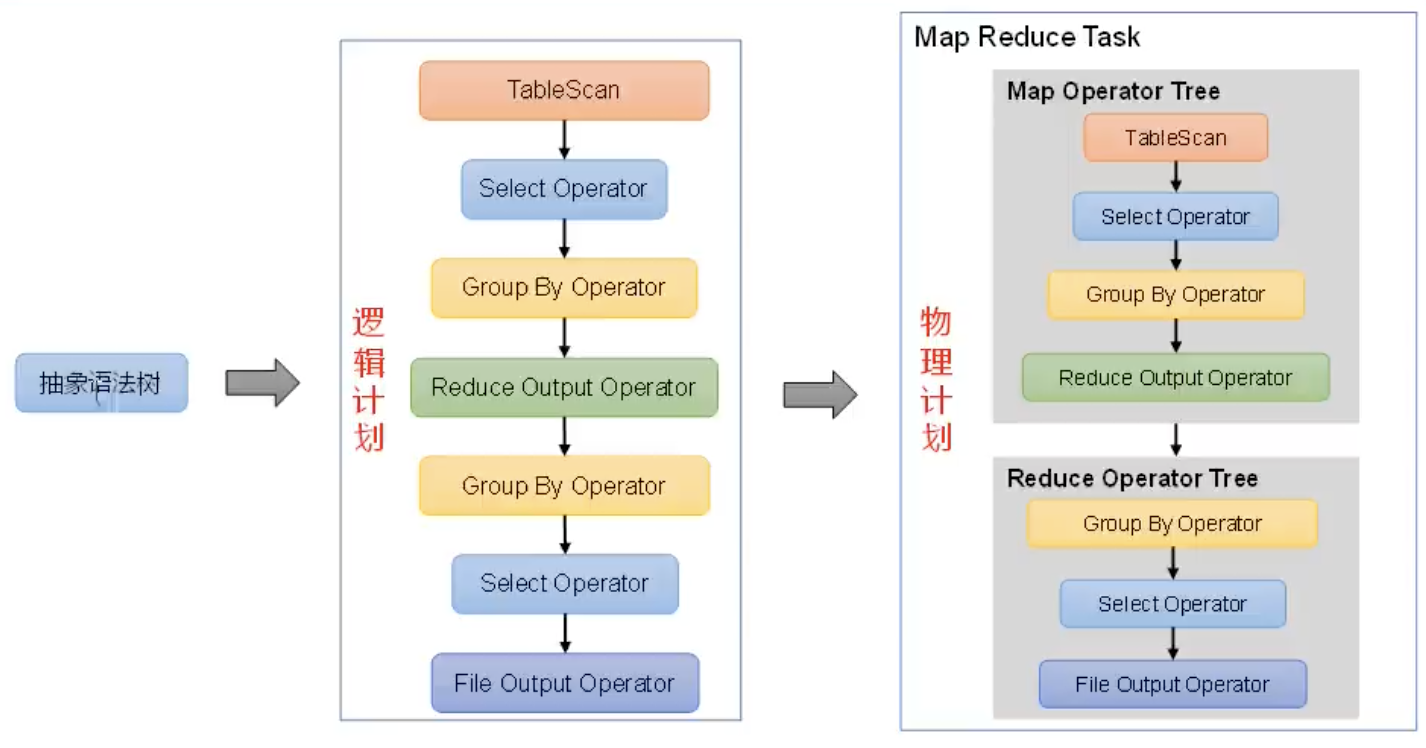
4.4.逻辑优化器——Logical Optimizer
顾名思义,就是对逻辑计划进行优化。
谓词下推的优化就是在逻辑优化器中完成的。谓词下推就是在不影响结果的前提下,尽量把Filter Opeartor往前放。
4.5.物理计划生成器——Physical Plan Generator
根据优化后的逻辑计划生成对应的物理计划。物理执行计划就是对应的MapReduce任务链。
4.6.物理优化器——Physical Optimizer
顾名思义,就是对物理计划进行优化。比如map、join的优化。
4.7.执行器——Executor
执行该计划,得到查询结果,并返回给客户端。